









今天的博客主要参考了2016年KDD会议上的paper《Structural Deep Network Embedding》,主要将了一种基于非线性空间中的网络节点的Embedding生成策略。
需要注意的是这篇paper和2016年之前很多网络节点Embedding策略相比,有2大创新的地方:
1 节点的非线性映射表征。最大的不同点就是“非线性”这三个字,像之前的Deepwalk,Line等算法本质上都是在线性空间中对节点进行映射。而随着深度学习时代的到来,多层非线性变化层给图像、语言和文本领域带来了太多的突破,作者这里把多层非线性思想融入到了网络节点的表征中来,并在后续很多大型数据集上证明了,非线性变化所带来的好处;
2 一阶关系和二阶关系的同时考虑。这种特性对于稀疏网络来说(实际问题中,稀疏网络是非常常见的现象)尤其重要。一阶关系只考虑了2个直连的节点,即认为两个直连的节点是相似的,paper里称之为local structure information;而二阶节点更多地考虑到了目标节点的邻居节点,即认为两个共享较多邻居的节点即使没有直连,那么它们也是相似的,paper里称之为global structure information。
当明白了这两点的真正含义之后,其实作者真正的意图就非常好讲了,话不多说,直接上图:
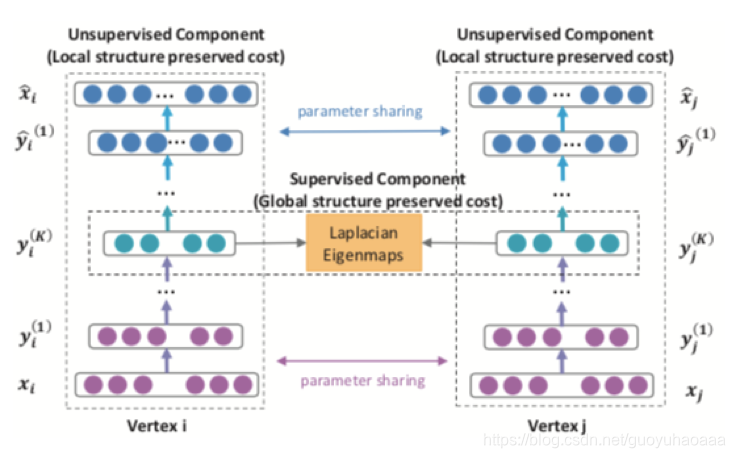
我首先想说的是,针对第一阶表征和第二阶表征作者分别构建了2种目标函数。
图中的 x i x_i xi作为节点i的输入向量,是以节点i为核心的临接向量(即邻接矩阵中的第i行)。从 x i x_i xi到中间的 y i K y_i^{K} yiK经过了多层的全连接网络+非线性激活函数sigmoid,然后从中间的 y i K y_i^{K} yiK经过对称的非线性变换到 x i ∗ x_i^* xi∗,其实就是最基础的auto-encoder架构,而中间层的表征 y i K y_i^{K} yiK就是目标节点i最终的network Embedding表征向量。作者说这个编码解码的过程促使模型能够学到更加本质的 y i K y_i^{K} yiK表征形式,而这个过程更多考虑的是节点的二阶特征即global structure information,因为如果两个节点的邻居节点多,那么它们的输入临接向量 x x x也会更相似,它们中间层的表征 y i K y_i^{K} yiK也会更相似,需要注意的是这里的损失函数,在传统auto-encoder损失函数的基础上修改了部分: L 2 n d = ∑ i = 1 n ∣ ∣ ( x i ∗ − x i ) ⨀ b i ∣ ∣ 2 2 L_{2nd}=\sum_{i=1}^n ||(x_i^*-x_i)\bigodot b_i||_2^2 L2nd=∑i=1n∣∣(xi∗−xi)⨀bi∣∣22,如果 x i > 0 x_i>0 xi>0,那么 b i = 1 b_i=1 bi=1,否则的话 b i = 0 b_i=0 bi=0。即令auto-encoder的注意力更多的放到 x i x_i xi向量中非0的位置上。因为两个 x x x如果某些位置为0,说明它们和该位置对应的节点是都没有联系的,并不能因此说它们就是相似的;而如果两个 x x x如果某些位置同时不为0,说明它们和该位置对应的节点是有联系的,可以说它们比较相似的。
接下来就是对一阶关联信息的建模,其实思想还是非常简单的,其损失函数如下
L
1
s
t
=
∑
i
,
j
=
1
n
s
i
j
∣
∣
y
i
K
−
y
j
K
∣
∣
2
2
L_{1st}=\sum_{i,j=1}^n s_{ij}||y_i^K-y_j^K||_2^2
L1st=∑i,j=1nsij∣∣yiK−yjK∣∣22,可以看出其也是对非线性空间中映射后的向量进行建模,两个节点间的边权重越大,说明两个节点间的关系越紧密,则两个节点的非线性映射表征形式越相近。
综合考虑一阶和二阶的目标函数,那么整体的损失函数如下所示:
L
t
o
t
a
l
=
L
1
s
t
+
α
L
2
n
d
+
β
∣
∣
W
∣
∣
2
L_{total}=L_{1st}+\alpha L_{2nd}+\beta ||W||_2
Ltotal=L1st+αL2nd+β∣∣W∣∣2
我个人觉得,像这种类似的network Embedding技术的产出,一方面可以直接拿来用(比方说说节点的相似度衡量),另一方面可以被看做是特征工程的一部分,其作为特征补充到原有的任务中去。具体哪一种方式,需要灵活的根据自己的整体目标任务进行选择。















 3453
3453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









