








智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》
目录
智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》
1. 前言
这是项目《智能驾驶 车牌检测和识别》系列之《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》;项目将搭建一个智能的支持多车牌的车牌检测和识别系统;整套项目主要包含两大算法:
(1)车牌检测:项目使用YOLOv5进行车牌检测,轻量化后的模型可以部署到Android平台或者开发板上,在多线程或者GPU下,可以达到实时车牌检测效果
(2)车牌识别:项目基于CRNN或LPRNet模型构建车牌识别算法,支持绿牌和蓝牌识别;为方便后续工程化,项目对CRNN模型进行魔改,提出一个PlateNet模型,用于支持部署到Android平台或者开发板上

整套智能车牌检测和识别系统,在普通Android手机上可以达到实时的检测效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。下表格给出CRNN,LPRNet和PlateNet模型的计算量和参数量以及其车牌识别的准确率:
| 模型 | input-size | params(M) | GFLOPs | Accuracy |
| LPRNet | 94×24 | 0.48M | 0.147GFlops | 0.9393 |
| CRNN | 160×32 | 8.35M | 1.06GFlops | 0.9343 |
| PlateNet | 168×48 | 1.92M | 1.25GFlops | 0.9583 |
车牌识别Demo效果展示:
 |  |
【 整套项目下载地址】:智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》
【Android Demo体验】https://download.csdn.net/download/guyuealian/87400593
【尊重原创,转载请注明出处】《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704209
更多项目《智能驾驶 车牌检测和识别》系列文章请参考:
- 智能驾驶 车牌检测和识别(一)《CCPD车牌数据集》:https://blog.csdn.net/guyuealian/article/details/128704181
- 智能驾驶 车牌检测和识别(二)《YOLOv5实现车牌检测(含车牌检测数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704068
- 智能驾驶 车牌检测和识别(三)《CRNN和LPRNet实现车牌识别(含车牌识别数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704209
- 智能驾驶 车牌检测和识别(四)《Android实现车牌检测和识别(可实时识别车牌)》:https://blog.csdn.net/guyuealian/article/details/128704242
- 智能驾驶 车牌检测和识别(五)《C++实现车牌检测和识别(可实时识别车牌)》:https://blog.csdn.net/guyuealian/article/details/128704276
- 智能驾驶 红绿灯检测(一)《红绿灯(交通信号灯)数据集》:https://blog.csdn.net/guyuealian/article/details/128222850
- 智能驾驶 红绿灯检测(二)《YOLOv5实现红绿灯检测(含红绿灯数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128240198
- 智能驾驶 红绿灯检测(三)《Android实现红绿灯检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128240334
-
智能驾驶 车辆检测(一)《UA-DETRAC BITVehicle车辆检测数据集》:https://blog.csdn.net/guyuealian/article/details/127907325
-
智能驾驶 车辆检测(二)《YOLOv5实现车辆检测(含车辆检测数据集+训练代码)》:https://blog.csdn.net/guyuealian/article/details/128099672
-
智能驾驶 车辆检测(三)《Android实现车辆检测(含Android源码 可实时运行)》:https://blog.csdn.net/guyuealian/article/details/128190532
2. 车牌识别的方法
传统的车牌识别的方法主要采用字符分割的方法实现车牌识别,即先将车牌图像按照预定的规则将车牌的字符一个一个切割,并按照模式匹配的方法识别车牌字符;显然该方法效率低,准确率也不高;
目前,车牌识别的研究方向是基于深度学习的无分割的车牌识别方法,即将车牌识别问题转化为字符序列标记问题,如项目使用的CRNN,LPRNet和PlateNet等模型都是无分割的车牌识别方法。
上述介绍的几种车牌识别方法,都需要进行车牌定位,然后才能进行车牌识别;当然也存在无需车牌定位(车牌检测)的方法,即将定位和识别放在了一个网络上,真正实现了一个网络端到端的车牌识别《Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks》
项目将搭建一个车牌检测和识别系统;整套项目主要包含两大算法:
(1)车牌检测:项目使用YOLOv5进行车牌检测,轻量化后的模型可以部署到Android平台或者开发板上,在多线程或者GPU下,可以达到实时车牌检测效果
(2)车牌识别:项目基于CRNN或LPRNet模型构建车牌识别算法,支持绿牌和蓝牌识别;为方便后续工程化,项目对CRNN模型进行魔改,提出一个PlateNet模型,用于支持部署到Android平台或者开发板上
3. 车牌检测+识别数据集
目前收集了约30W+的车牌检测数据集(含蓝牌和绿牌),主要使用开源的CCPD车牌数据集,关于CCPD车牌数据集说明,请参考智能驾驶 车牌检测和识别(一)《CCPD车牌数据集》:https://blog.csdn.net/guyuealian/article/details/128704181

4. 车牌检测模型训练
项目使用YOLOv5进行车牌检测,轻量化后的模型可以部署到Android平台或者开发板上,在多线程或者GPU下,可以达到实时车牌检测效果,关于车牌检测模型训练的说明,请参考智能驾驶 车牌检测和识别(二)《YOLOv5实现车牌检测(含车牌检测数据集和训练代码)》:https://blog.csdn.net/guyuealian/article/details/128704068

5. 车牌识别模型训练
(1)项目安装
.
├── configs
├── core
├── data
├── docs
├── modules
├── output
├── README.md
├── demo.py
├── demo.sh
├── train.py
└── train.sh
推荐使用Python3.8或Python3.7,更高版本可能存在版本差异问题,Python依赖环境,使用pip安装即可,项目代码都在Ubuntu系统和Windows系统验证正常运行,请放心使用;若出现异常,大概率是相关依赖包版本没有完全对应
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
Pillow
PyYAML>=5.3.1
scipy>=1.4.1
torch>=1.7.0
torchvision>=0.8.1
tqdm>=4.41.0
tensorboard>=2.4.1
seaborn>=0.11.0
pandas
thop # FLOPs computation
pybaseutils==0.7.0项目安装教程请参考(初学者入门,麻烦先看完下面教程,配置好开发环境):
- 项目开发使用教程和常见问题和解决方法
- 视频教程:1 手把手教你安装CUDA和cuDNN(1)
- 视频教程:2 手把手教你安装CUDA和cuDNN(2)
- 视频教程:3 如何用Anaconda创建pycharm环境
- 视频教程:4 如何在pycharm中使用Anaconda创建的python环境
- 推荐使用Python3.8或Python3.7,更高版本可能存在版本差异问题
(2)构建Train和Test车牌识别数据
车牌识别数据,主要来源于CCPD数据集,训练数据和测试数据的数据格式,要求非常简单:
- 对车牌进行裁剪时,请尽量保证车牌号的完整性,其他车身等非车牌区域尽量去除,仅裁剪车牌区域即可
- 一张图片仅包含一个车牌,可以绿牌也可以蓝牌
- 车牌图片文件命名规则:车牌号_序号ID ;如【沪AD07225_00798_000.jpg】,其中【沪AD07225】表示这个张图片的真实车牌号,【00798_000】是序号ID,这个序号ID是为了避免车牌号重复,序号ID可以是任意字符;模型训练时,仅取车牌号作为label进行训练,序号ID会被忽略。
- 如果,你需要新增自己的车牌识别数据集,请按照上面的要求制作即可
以下是车牌识别数据的样本数据,请参考格式制作即可;项目源码已经附带了制作好的CCPD车牌识别数据集,可以直接用于车牌识别模型训练:

(3)构建模型
项目实现了三个车牌识别模型:CRNN,LPRNet和PlateNet,其计算量和参数量参考如下:
- CRNN:最经典的OCR模型了,采用CNN+RNN的网络结构,提出CTC-Loss对齐算法解决不定长序列对齐问题;原始源码是用于文字识别的,稍微改成车牌数据集,即可用于车牌识别了
- LPRNet:相比经典的CRNN模型,LPRNet 没有采用RNN结构;是专门设计用于车牌识别的轻量级的模型,整个网络结构设计高度轻量化,参数量仅有0.48M
- PlateNet:LPRNet网络结构中存在MaxPool3d等算子,在端上部署时,会存在OP不支持等问题,PlateNet模型去除MaxPool3d,改成使用MaxPool2d,保证模型可端上部署成功。
| 模型 | input-size | params(M) | GFLOPs |
| LPRNet | 94×24 | 0.48M | 0.147GFlops |
| CRNN | 160×32 | 8.35M | 1.06GFlops |
| PlateNet | 168×48 | 1.92M | 1.25GFlops |
(4)修改配置文件:config_crnn.yaml
准备好数据好,下一步是修改配置文件config_crnn.yaml的数据路径:
- 修改train_data和test_data为你自己的数据路径
- 其他参数保持默认即可
train_data:
- 'dataset/CCPD2020-voc/train/plates'
- 'dataset/CCPD2020-voc/val/plates'
- 'dataset/CCPD2019-voc/ccpd_base/plates-train'
- 'dataset/CCPD2019-voc/ccpd_blur/plates'
- 'dataset/CCPD2019-voc/ccpd_challenge/plates'
- 'dataset/CCPD2019-voc/ccpd_db/plates'
- 'dataset/CCPD2019-voc/ccpd_fn/plates'
- 'dataset/CCPD2019-voc/ccpd_rotate/plates'
- 'dataset/CCPD2019-voc/ccpd_tilt/plates'
- 'dataset/CCPD2019-voc/ccpd_weather/plates'
test_data:
- 'dataset/CCPD2020-voc/test/plates'
- 'dataset/CCPD2019-voc/ccpd_base/plates-test'
class_name: "data/plates_table.txt"
train_transform: "train"
test_transform: "test"
batch_size: 128
net_type: 'CRNN'
flag: "Perspective"
input_size: [ 160, 32 ]
rgb_mean: [ 0.5, 0.5, 0.5 ]
rgb_std: [ 0.5, 0.5, 0.5 ]
resample: True
work_dir: "work_space"
num_epochs: 200
optim_type: 'Adam'
lr: 0.001
weight_decay: 0.0
milestones: [ 100,150,170 ]
momentum: 0.0
gpu_id: [ 0 ]
num_workers: 8
log_freq: 10
pretrained: "data/pretrained/CRNN/CRNN.pth"
配置文件每个参数含义如下:
| 参数 | 类型 | 参考值 | 说明 |
|---|---|---|---|
| train_data | str, list | - | 训练数据文件,可支持多个文件 |
| test_data | str, list | - | 测试数据文件,可支持多个文件 |
| class_name | str | - | 类别文件 |
| train_transform | str | train | 训练数据数据处理方法 |
| test_transform | str | test | 测试数据数据处理方法 |
| work_dir | str | work_space | 训练输出工作空间 |
| net_type | str | CRNN | 骨干网络,支持CRNN,LPRNe和PlateNet等模型 |
| intput_size | list | [160,32] | 模型输入大小 |
| rgb_mean | list | [0.5,0.5,0.5] | 图像归一化均值 |
| rgb_std | list | [0.5,0.5,0.5] | 图像归一化方差 |
| resample | bool | True | 进行样本均衡 |
| batch_size | int | 128 | 批训练大小 |
| lr | float | 0.001 | 初始学习率大小 |
| optim_type | str | Adam | 优化器,{SGD,Adam} |
| milestones | list | [30,80,100] | 降低学习率的节点 |
| momentum | float | 0.9 | SGD动量因子 |
| num_epochs | int | 200 | 循环训练的次数 |
| num_workers | int | 8 | DataLoader开启线程数 |
| weight_decay | float | 5e-4 | 权重衰减系数 |
| gpu_id | list | [ 0 ] | 指定训练的GPU卡号,可指定多个 |
| log_freq | int | 10 | 显示LOG信息的频率 |
| pretrained | str | model.pth | pretrained的模型 |
(5)开始训练
整套训练代码非常简单操作,项目源码已经给出CRNN,LPRNet和PlateNet的配置文件;用户只需要修改好配置文件的的数据路径,即可开始训练了。
- 训练CRNN模型
python train.py -c configs/config_crnn.yaml- 训练LPRNet模型
python train.py -c configs/config_lprnet.yaml- 训练PlateNet模型
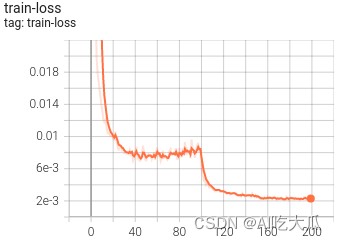
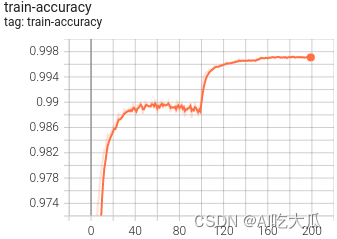
python train.py -c configs/config_platenet.yaml(6)可视化训练过程
训练过程可视化工具是使用Tensorboard,使用方法:
# 基本方法
tensorboard --logdir=path/to/log/
# 例如(请修改自己的训练的模型路径)
tensorboard --logdir=data/weight/CRNN_Perspective_20230113174750/log 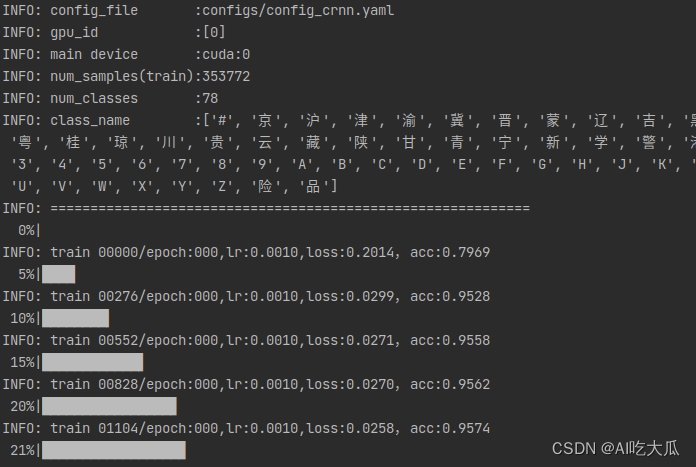 | 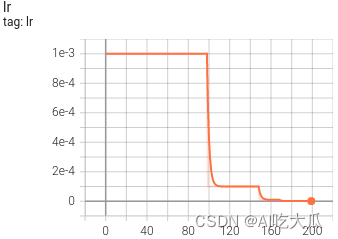 |
 |  |
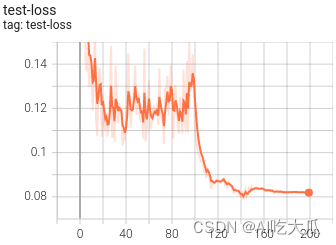 | 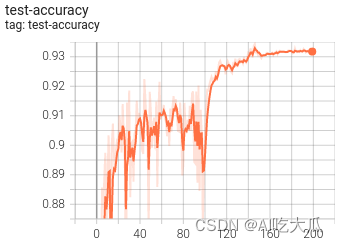 |
下表格给出CRNN,LPRNet和PlateNet模型的计算量和参数量以及其车牌识别的准确率:
| 模型 | input-size | params(M) | GFLOPs | Accuracy |
| LPRNet | 94×24 | 0.48M | 0.147GFlops | 0.9393 |
| CRNN | 160×32 | 8.35M | 1.06GFlops | 0.9343 |
| PlateNet | 168×48 | 1.92M | 1.25GFlops | 0.9583 |
(7)一些说明和优化建议
- 数据长尾问题:CCPD车牌数据集拍摄的车牌照片的环境复杂多变,包括了倾斜、模糊、雨天、雪天等多个场景的数据,并且大部分图片有且仅含有一个车牌;由于采集人员主要在安徽省城市的停车场进行采集,导致大部分数据都是含【皖】的车牌图片,而其他省份(如宁,藏省份)的车牌比较少,而一些特殊车牌的数据就几乎没有,比如【挂使领民航危险品】这些车牌几乎没有。数据长尾问题这会导致模型识别结果偏向于数据较多的样本类别,车牌省份经常被误识别为【皖】。CCPD数据各个省份的车牌数据统计:

- 样本均衡:为了减小数据长尾问题的影响,建议实现Re-Sampling机制,或者增加【新吉青琼宁藏】车牌,警用车牌,武警车牌,使馆车牌,民航车牌和危险品车牌等数据集,提高模型的泛化性;项目已经实现Re-Sampling机制,配置文件设置resample=True即可
- 车牌倾斜的问题:现实场景中,由于摄像头角度安装位置,车牌位置等因素,抓拍的车牌图片往往是倾斜的,这会影响车牌识别的效果;建议对车牌进行倾斜矫正,可以采用opencv的霍夫变换 cv2.HoughLines()进行倾斜矫正,提高识别准确率。项目实现了车牌矫正工具:core/utils/image_correction.py:
 |  |
 |  |
- 双层车牌:项目暂不支持双层车牌识别,一种简单可行的双层车牌识别方法是采用拼接成单层车牌的方式进行识别,如:

- 车牌颜色问题:普通蓝牌共有7位字符;新能源车牌有8位字符,蓝绿车牌可以通过车牌个数进行判断;当然后续优化,也可以修改模型增加一个分支用于预测车牌的颜色
6. 车牌识别效果(Python版本)
demo.py文件用于推理和测试模型的效果,填写好模型文件以及测试图片即可运行测试了
demo.py源码:
# -*-coding: utf-8 -*-
"""
@Author : PKing
@E-mail : 390737991@qq.com
@Date : 2022-12-30 10:40:48
@Brief :
"""
import os
import cv2
import torch
import numpy as np
import argparse
from typing import List, Tuple
from core.models.build_model import get_models
from core.transforms import build_transform
from core.utils import image_correction
from modules.yolov5.engine.yolov5_detector import Yolov5Detector
from pybaseutils import file_utils, image_utils
from basetrainer.utils.converter import pytorch2onnx
ROOT = os.path.dirname(__file__)
PLATE_TABLE = "#京沪津渝冀晋蒙辽吉黑苏浙皖闽赣鲁豫鄂湘粤桂琼川贵云藏陕甘青宁新学警港澳挂使领民航危0123456789ABCDEFGHJKLMNPQRSTUVWXYZ险品"
class Recognizer(object):
def __init__(self, model_file, net_type, class_name=None, use_detector=True, input_size=(),
rgb_mean=[0.5, 0.5, 0.5], rgb_std=[0.5, 0.5, 0.5], alignment=True, export=True, device="cuda:0"):
"""
:param model_file: 车牌识别模型文件
:param net_type: 车牌识别模型名称
:param class_name: 车牌所有字符类别
:param use_detector: 是否检测车牌
:param input_size: 模型输入大小
:param rgb_mean: rgb_mean
:param rgb_std: rgb_std
:param alignment: 是否进行车牌矫正
:param export: 是否导出ONNX模型
:param device: 运行设备
"""
self.device = device
self.rgb_mean = rgb_mean
self.rgb_std = rgb_std
self.net_type = net_type
self.alignment = alignment # 是否进行车牌倾斜矫正
if not input_size:
input_size = (168, 48) if net_type.lower() == "PlateNet".lower() else input_size
input_size = (94, 24) if net_type.lower() == "LPRNet".lower() else input_size
input_size = (160, 32) if net_type.lower() == "CRNN".lower() else input_size
self.input_size = input_size
self.use_detector = use_detector
self.transform = build_transform.image_transform(input_size=self.input_size,
rgb_mean=self.rgb_mean,
rgb_std=self.rgb_std,
trans_type="test")
# 类别
if not class_name: class_name = [n for n in PLATE_TABLE]
self.class_name, self.class_dict = file_utils.parser_classes(class_name)
self.num_classes = len(self.class_name)
# 加载车牌识别模型
self.model = self.build_model(model_file)
# 加载车牌检测模型
if self.use_detector:
# imgsz, weights = 640, os.path.join(ROOT, "modules/yolov5/data/model/yolov5s_640/weights/best.pt")
imgsz, weights = 320, os.path.join(ROOT, "modules/yolov5/data/model/yolov5s05_320/weights/best.pt")
self.detector = Yolov5Detector(weights, imgsz=imgsz, conf_thres=0.5, iou_thres=0.5, device=self.device)
# 转换为ONNX模型
if export:
onnx_file = model_file[:-len("pth")] + "onnx"
pytorch2onnx.convert2onnx(self.model, input_shape=(1, 3, input_size[1], input_size[0]),
onnx_file=onnx_file, simplify=True)
print("convert model to onnx:{}".format(onnx_file))
def build_model(self, model_file):
"""
构建模型
:param model_file:
:return:
"""
check_point = torch.load(model_file, map_location="cpu")
model_state = check_point['state_dict']
model = get_models(net_type=self.net_type, num_classes=self.num_classes,
input_size=self.input_size, is_train=False) # export True 用来推理
# model =build_lprnet(num_classes=len(plate_chr),export=True)
model.load_state_dict(model_state)
model.to(self.device)
model.eval()
return model
def plates_detect(self, image):
"""
车牌检测
:param image: BGR Image
:return:
"""
dets = self.detector.detect(image=image, vis=False)
dets = dets[0] if len(dets) > 0 else []
return dets
def plates_correction(self, images: List[np.ndarray]):
"""
车牌倾斜矫正
:param images:
:return:
"""
cimages = []
for img in images:
img, angle = image_correction.ImageCorrection.correct(img, vis=False)
cimages.append(img)
return cimages
def plates_recognize(self, image):
"""
车牌识别
:param image:
:return:
"""
h, w = image.shape[:2]
dets = [[0, 0, w, h]]
result = {"dets": [], "plates": []}
if self.use_detector:
dets = self.plates_detect(image)
image = image_utils.get_bboxes_crop(image, dets)
if len(image) == 0: return result
with torch.no_grad():
input_tensor = self.preprocess(image, alignment=self.alignment) # torch.Size([1, 3, 48, 168])
outputs = self.model(input_tensor.to(self.device)) # classifier prediction
outputs = outputs.argmax(dim=2) # torch.Size([1, 21, 78])
outputs = outputs.cpu().detach().numpy()
preb_labels = self.postprocess(outputs)
plates = self.map_class_name(preb_labels)
result = {"dets": dets, "plates": plates}
return result
def preprocess(self, images, alignment=True):
"""
数据预处理
:param images: BGR images
:param alignment: 车牌倾斜矫正
:return:
"""
if not isinstance(images, list): images = [images]
if alignment: images = self.plates_correction(images)
image_tensors = []
for img in images:
if len(img.shape) == 2: img = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
image_tensor = self.transform(img)
image_tensors.append(torch.unsqueeze(image_tensor, dim=0))
image_tensors = torch.cat(image_tensors)
return image_tensors
def postprocess(self, outputs):
"""
车牌识别后处理
:param outputs:
:return:
"""
pred_labels = []
for output in outputs:
label = 0
pred_label = []
for i in range(len(output)):
if output[i] != 0 and output[i] != label:
pred_label.append(output[i])
label = output[i]
pred_labels.append(pred_label)
return pred_labels
def map_class_name(self, pred_labels):
"""
:param pred_labels:
:return:
"""
pred_names = []
for preb_label in pred_labels:
preb_label = [self.class_name[int(l)] for l in preb_label]
pred_names.append("".join(preb_label))
return pred_names
def draw_result(self, image, result: dict, thickness=4, fontScale=0.6):
"""绘制车牌识别结果"""
dets = result["dets"]
if len(dets) > 0:
boxes = dets[:, 0:4]
score = dets[:, 4]
plates = result["plates"]
boxes_name = ["{} {:3.3f}".format(n, s) for n, s in zip(plates, score)]
image = image_utils.draw_image_bboxes_text(image, boxes=boxes, boxes_name=boxes_name, drawType="chinese",
color=(0, 0, 255), thickness=thickness, fontScale=fontScale)
return image
def start_capture(self, video_file, save_video=None, detect_freq=1, vis=True):
"""
start capture video
:param video_file: *.avi,*.mp4,...
:param save_video: *.avi
:param detect_freq:
:return:
"""
video_cap = image_utils.get_video_capture(video_file)
width, height, numFrames, fps = image_utils.get_video_info(video_cap)
if save_video:
self.video_writer = image_utils.get_video_writer(save_video, width, height, fps)
count = 0
while True:
if count % detect_freq == 0:
# 设置抽帧的位置
if isinstance(video_file, str): video_cap.set(cv2.CAP_PROP_POS_FRAMES, count)
isSuccess, frame = video_cap.read()
if not isSuccess:
break
result = self.plates_recognize(frame)
frame = self.draw_result(frame, result, thickness=5, fontScale=0.8)
if vis:
image_utils.cv_show_image("image", frame, use_rgb=False, delay=30)
if save_video:
self.video_writer.write(frame)
count += 1
video_cap.release()
def detect_image_dir(self, image_dir, out_dir=None, vis=True):
"""
:param image_dir: 车牌图片目录
:param out_dir:
:param vis:
:return:
"""
image_list = file_utils.get_files_lists(image_dir)
for image_file in image_list:
image = image_utils.read_image_ch(image_file, use_rgb=False) # BGR image
result = self.plates_recognize(image)
print("file:{}=\n{}".format(image_file, result))
image = self.draw_result(image, result)
if vis:
image_utils.cv_show_image("image", image, use_rgb=False)
if out_dir:
out_file = file_utils.create_dir(out_dir, None, os.path.basename(image_file))
cv2.imwrite(out_file, image)
def get_argparse():
image_dir = 'data/test_image' # 测试图片
video_file = "data/test-video2.mp4" # path/to/video.mp4 测试视频文件,如*.mp4,*.avi等
# model_file = 'data/weight/PlateNet_Perspective_20230104102743/model/best_model_186_0.9583.pth'
# net_type = "PlateNet"
model_file = 'data/weight/CRNN_Perspective_20230113174750/model/best_model_146_0.9343.pth'
net_type = "CRNN"
out_dir = "output/test-result" # 保存检测结果
parser = argparse.ArgumentParser()
parser.add_argument('--model_file', type=str, default=model_file, help='path/to/model.pth')
parser.add_argument('--net_type', type=str, default=net_type, help='set model type')
parser.add_argument('--video_file', type=str, default=None, help='camera id or video file')
parser.add_argument('--image_dir', type=str, default=image_dir, help='path/to/image-dir')
parser.add_argument('--out_dir', type=str, default=out_dir, help='save result image directory')
parser.add_argument('--use_detector', action='store_true', help='whether to detect plate', default=True)
parser.add_argument('--export', action='store_true', help='whether to export ONNX', default=True)
cfg = parser.parse_args()
return cfg
if __name__ == '__main__':
opt = get_argparse()
d = Recognizer(model_file=opt.model_file, net_type=opt.net_type, use_detector=opt.use_detector, export=opt.export)
if isinstance(opt.video_file, str):
if len(opt.video_file) == 1: opt.video_file = int(opt.video_file)
save_video = os.path.join(opt.out_dir, "result.avi") if opt.out_dir else None
d.start_capture(opt.video_file, save_video, detect_freq=1, vis=True)
else:
d.detect_image_dir(opt.image_dir, out_dir=opt.out_dir, vis=True)-
测试CRNN模型
python demo.py --image_dir data/test_image --model_file data/weight/CRNN_Perspective_20230113174750/model/best_model_146_0.9343.pth --net_type CRNN --use_detector
-
测试LPRNet模型
python demo.py --image_dir data/test_image --model_file data/weight/LPRNet_Perspective_20230104142632/model/best_model_011_0.9393.pth --net_type LPRNet --use_detector
-
测试PlateNet模型
python demo.py --image_dir data/test_image --model_file data/weight/PlateNet_Perspective_20230104102743/model/best_model_186_0.9583.pth --net_type PlateNet --use_detector
-
测试视频文件
python demo.py --video_file data/test-video.mp4 --model_file data/weight/PlateNet_Perspective_20230104102743/model/best_model_186_0.9583.pth --net_type PlateNet --use_detector
-
测试摄像头
# video_file=0 # 测试摄像头ID
python demo.py --video_file 0 --model_file data/weight/PlateNet_Perspective_20230104102743/model/best_model_186_0.9583.pth --net_type PlateNet --use_detector
车牌识别Demo效果展示:
| |
 |  |
 |  |
7. 车牌识别效果(Android版本)
已经完成Android版本车牌检测和识别算法开发,APP在普通Android手机上可以达到实时的检测和识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。详细说明请查看:智能驾驶 车牌检测和识别(四)《Android实现车牌检测和识别(可实时识别车牌)》:https://blog.csdn.net/guyuealian/article/details/128704242
Android Demo体验:https://download.csdn.net/download/guyuealian/87400593
|
|
|


8. 车牌识别项目源码下载
整套项目源码内容包含:车牌识别数据集 +车牌识别训练代码和测试代码(Pytorch)
如需下载项目源码,请WX关注【AI吃大瓜】,回复【车牌识别】即可下载
项目资源内容包含:
(1)CCPD车牌识别数据集:
智能驾驶 车牌检测和识别(一)《CCPD车牌数据集》_AI吃大瓜的博客-CSDN博客

- CCPD2019:官方原始数据,主要是蓝牌数据,约34W;
- CCPD2020:官方原始数据,主要是新能源绿牌数据,约1万
- CCPD2019-voc:将数据集CCPD2019转换为VOC数据格式(数据在Annotations,JPEGImages文件夹),可直接用于目标检测模型训练
- CCPD2020-voc:将数据集CCPD2020转换为VOC数据格式(数据在Annotations,JPEGImages文件夹),可直接用于目标检测模型训练
- 为了方便后续训练车牌识别模型,数据集提供已经裁剪好的车牌图片,并放在plates文件夹
(2)车牌识别训练代码和测试代码(Pytorch)
- 车牌识别训练代码,backbone支持CRNN,LPRNet和PlateNet模型,提供pretrained模型
- train.py训练简单,简单配置config文件,即可开始训练
- 项目支持Re-Sampling机制,配置文件设置resample=True即可,可减小数据长尾问题的影响
- demo.py支持图片,视频和摄像头测试;
- demo.py支持导出onnx文件(export=True)
- demo.py支持车牌倾斜矫正( alignment=True)
- 提供已经训练好的车牌检测YOLOv5模型(modules/yolov5),可直接用于车牌检测



















 841
841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











