






点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文链接:https://arxiv.org/abs/2212.02015
代码链接:https://github.com/XuZhengzhuo/LiVT
计算机视觉研究院专栏
Column of Computer Vision Institute
Transformer 是现在火热的AIGC预训练大模型的基础,而ViT(Vision Transformer)是真正意义上将自然语言处理领域的Transformer带到了视觉领域。从Transformer的发展历程就可以看出,从Transformer的提出到将Transformer应用到视觉,其实中间蛰伏了三年的时间。而从将Transformer应用到视觉领域(ViT)到AIGC的火爆也差不多用了两三年。其实AIGC的火爆,从2022年下旬就开始有一些苗条,那时就逐渐有一些AIGC好玩的算法放出来,而到现在,AIGC好玩的项目真是层出不穷。

01
背 景
在机器学习领域中,学习不平衡的标注数据一直是一个常见而具有挑战性的任务。近年来,视觉 Transformer 作为一种强大的模型,在多个视觉任务上展现出令人满意的效果。然而,视觉 Transformer 处理长尾分布数据的能力和特性,还有待进一步挖掘。
目前,已有的长尾识别模型很少直接利用长尾数据对视觉 Transformer(ViT)进行训练。基于现成的预训练权重进行研究可能会导致不公平的比较结果,因此有必要对视觉 Transformer 在长尾数据下的表现进行系统性的分析和总结。
本文旨在填补这一研究空白,详细探讨了视觉 Transformer 在处理长尾数据时的优势和不足之处。本文将重点关注如何有效利用长尾数据来提升视觉 Transformer 的性能,并探索解决数据不平衡问题的新方法。通过本文的研究和总结,研究团队有望为进一步改进视觉 Transformer 模型在长尾数据任务中的表现提供有益的指导和启示。这将为解决现实世界中存在的数据不平衡问题提供新的思路和解决方案。
文章通过一系列实验发现,在有监督范式下,视觉 Transformer 在处理不平衡数据时会出现严重的性能衰退,而使用平衡分布的标注数据训练出的视觉 Transformer 呈现出明显的性能优势。相比于卷积网络,这一特点在视觉 Transformer 上体现的更为明显。另一方面,无监督的预训练方法无需标签分布,因此在相同的训练数据量下,视觉 Transformer 可以展现出类似的特征提取和重建能力。
基于以上观察和发现,研究提出了一种新的学习不平衡数据的范式,旨在让视觉 Transformer 模型更好地适应长尾数据。通过这种范式的引入,研究团队希望能够充分利用长尾数据的信息,提高视觉 Transformer 模型在处理不平衡标注数据时的性能和泛化能力。
02
文章贡献
本文是第一个系统性的研究用长尾数据训练视觉 Transformer 的工作,在此过程中,做出了以下主要贡献:
首先,本文深入分析了传统有监督训练方式对视觉 Transformer 学习不均衡数据的限制因素,并基于此提出了双阶段训练流程,将视觉 Transformer 模型内在的归纳偏置和标签分布的统计偏置分阶段学习,以降低学习长尾数据的难度。其中第一阶段采用了流行的掩码重建预训练,第二阶段采用了平衡的损失进行微调监督。

其次,本文提出了平衡的二进制交叉熵损失函数,并给出了严格的理论推导。平衡的二进制交叉熵损失的形式如下:
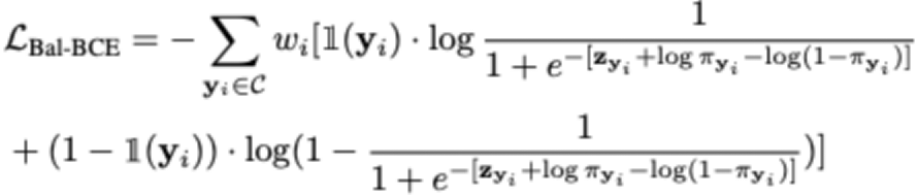
与之前的平衡交叉熵损失相比,本文的损失函数在视觉 Transformer 模型上展现出更好的性能,并且具有更快的收敛速度。研究中的理论推导为损失函数的合理性提供了严密的解释,进一步加强了我们方法的可靠性和有效性。
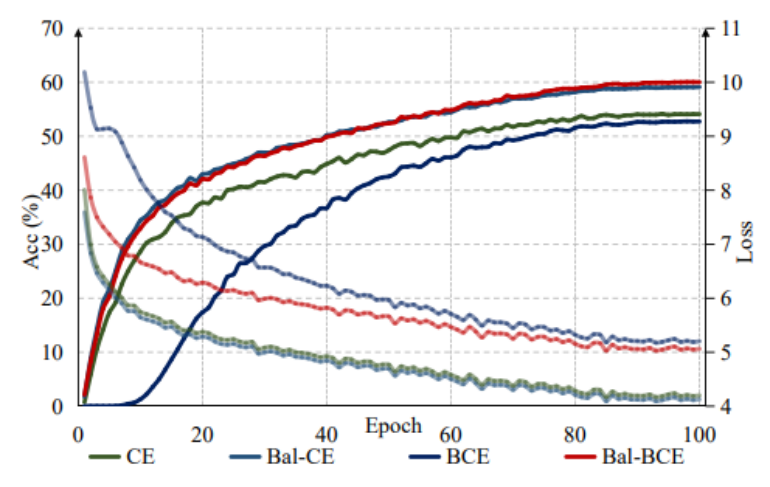
不同损失函数的收敛速度的比较
基于以上贡献,文章提出了一个全新的学习范式 LiVT,充分发挥视觉 Transformer 模型在长尾数据上的学习能力,显著提升模型在多个数据集上的性能。该方案在多个数据集上取得了远好于视觉 Transformer 基线的性能表现。
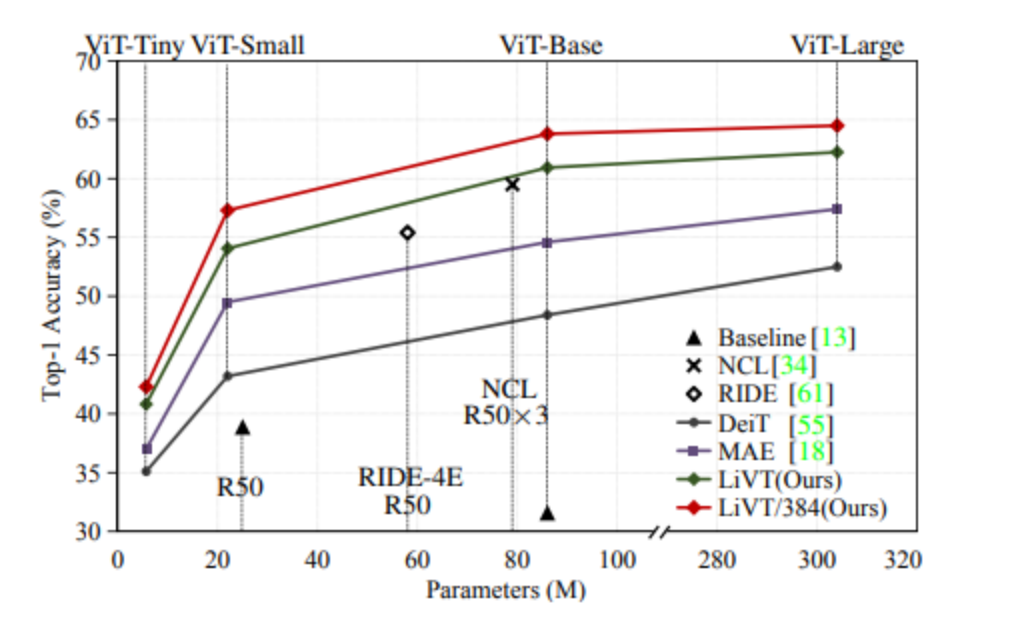
不同参数量下在 ImageNet-LT 上的准确性。
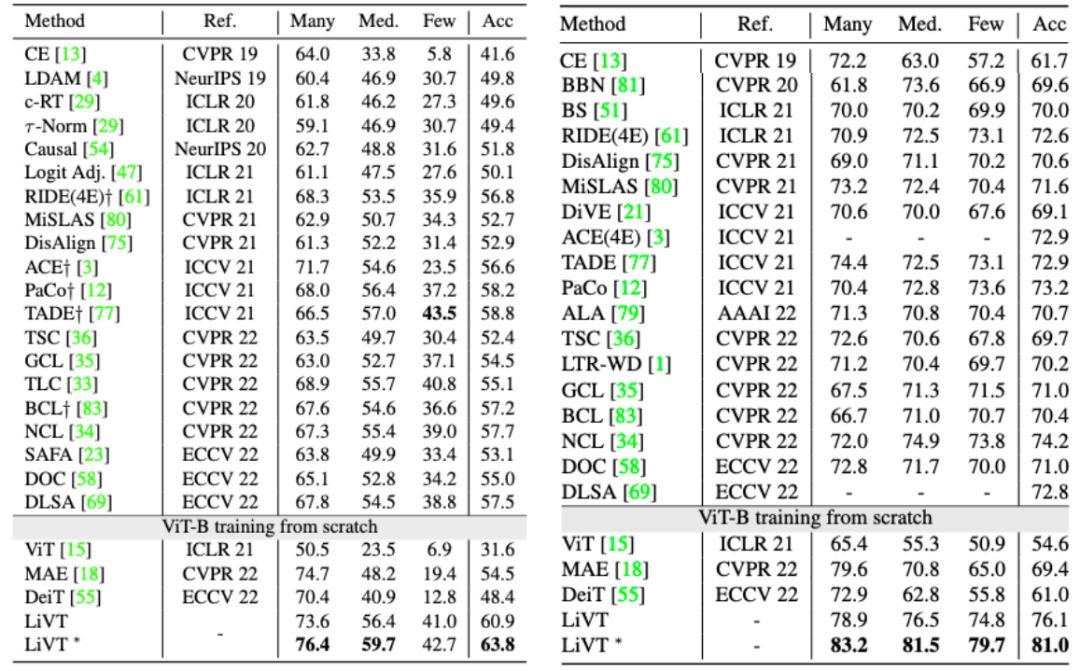
在 ImagNet-LT(左)和 iNaturalist18(右)数据集上的性能表现
同时,本文还验证了在相同的训练数据规模的情况下,使用ImageNet的长尾分布子集(LT)和平衡分布子集(BAL)训练的 ViT-B 模型展现出相近的重建能力。如 LT-Large-1600 列所示,在 ImageNet-LT 数据集中,可以通过更大的模型和 MGP epoch 获得更好的重建结果。

03
总 结
本文提供了一种新的基于视觉 Transformer 处理不平衡数据的方法 LiVT。LiVT 利用掩码建模和平衡微调两个阶段的训练策略,使得视觉 Transformer 能够更好地适应长尾数据分布并学习到更通用的特征表示。该方法不仅在实验中取得了显著的性能提升,而且无需额外的数据,具有实际应用的可行性。
转自《机器之心》
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
考的习惯!计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
🔗














 5182
5182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









