






点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
在人工智能和计算机视觉领域,物体检测是一项基础且关键的任务。尤其在空中图像的背景下,这项任务变得更加复杂和具有挑战性。

PART/1
概述
目前航拍图像中检测物体有着一下几项重大挑战:
1)航拍图像通常具有非常大的尺寸,通常有数百万甚至数亿像素,而计算资源有限。
2) 物体尺寸小会导致有效检测的信息不足。
3) 不均匀的对象分布会导致计算资源的浪费。

为了解决这些问题,研究者提出了YOLC(You Only Look Clusters),这是一个基于无锚目标检测器CenterNet的高效框架。为了克服大规模图像和非均匀对象分布带来的挑战,引入了一种局部尺度模块(LSM),该模块自适应地搜索聚类区域以放大以进行精确检测。此外,研究者还使用Gaussian Wasserstein distance(GWD)修改回归损失,以获得高质量的边界框。检测头采用可变形卷积和细化方法来增强对小物体的检测。对包括Vi sdrone2019和UAVDT在内的两个航空图像数据集进行了广泛的实验,以证明新提出的方法的有效性和优越性。
PART/2
背景
早期的研究提出了新的多尺度训练策略,如图像金字塔的尺度归一化(SNIP)及其改进版本。这些方法可以有效地提高小对象的检测性能,而多尺度训练对计算资源和内存容量都有很大的要求。另一种方法是提高图像分辨率或特征分辨率。例如,生成对抗网络(GAN)可用于补偿小对象的信息丢失。因此,可以缩小小对象和大对象的特征表示之间的差距;但是计算成本将是昂贵的。最近,一些基于标签分配的方法旨在改进罕见小对象样本的样本分配策略。它们提高了小物体的检测性能,但在准确性或效率方面仍有改进的潜力。
高分辨率航空图像中小物体的不均匀分布对探测器提出了重大挑战,导致大规模航空图像的效率或精度降低。为了解决这些问题,一种简单的方法是将图像分成几个部分并放大,如均匀裁剪所示。然而,这种方法无法解释物体的非均匀分布,检测所有作物仍然需要大量时间。
为了应对上述挑战,已经提出了主流解决方案,包括设计专用方案来定位集群区域,这些方案可以随后用于检测。ClusSet采用集群检测网络来检测目标集群。DMNet对目标分布进行建模,并通过密度图生成聚类区域。这些策略显示出有希望的结果,因为聚类区域被保留,背景被尽可能地抑制。然而,对每种作物的独立检测降低了推理速度。此外,虽然上述方法生成了集群区域,但某些集群中的对象分布很稀疏,对最终性能的贡献很小。因此,在精度和效率之间实现最佳折衷是航空图像中目标检测的关键问题。
PART/3
新算法框架
准备工作
CenterNet是一个强大而高效的无锚目标象检测框架。与使用锚点预测边界框的传统方法不同,CenterNet从对象的中心点回归对象的大小、方向、姿势和关键点。这是通过一个全卷积网络实现的,该网络生成对象中心的热图(密度图),然后通过在热图中找到局部最大值来定位中心。使用这些峰值位置的特征,可以推断出物体的大小。由于其简单性,CenterNet在不依赖复杂特征工程的情况下实现了非凡的性能。它是一种快速有效的对象检测方法,已被研究界广泛采用。CenterNet作为一种代表性的无锚探测器,采用高分辨率特征图进行预测,使其对小物体特别友好和高效。密度贴图是提供图像中对象分布信息的强大工具。在CenterNet中,密度图用于定位对象。为了提高检测器检测小物体的性能,我们使用转置卷积层对特征图进行上采样,以匹配输入图像的大小。此外,我们提出了一种局部尺度模块,该模块利用热图自适应地搜索聚类区域并调整其大小以适应检测器,这可以进一步提高检测精度。
You Only Look Clusters
提出的YOLC遵循与Center-Net类似的管道,但它与CenterNet的区别在于使用了不同的主干、检测头、回归方式和损失函数。特别是,HRNet被用作生成高分辨率热图的骨干,这些热图更擅长检测小物体。此外,由于航空图像中物体的分布不平衡,设计了一种局部尺度模块(LSM)来自适应地搜索聚类区域。在检测到原始图像和裁剪后,在密集区域中,精确的结果直接替换为原始图像的结果。
高分辨率热图
为了提高在充满小物体的密集区域进行物体检测的准确性,YOLC使用了更高分辨率的热图。在CenterNet中,每个对象都被建模为其边界框中心的一个点,由热图中的高斯斑点表示。然而,相对于输入图像,热图被降采样了4倍。这种下采样可能会导致小物体在热图中只折叠成几个甚至一个点,从而难以准确定位它们的中心。为了解决这个问题,YOLC采用了一种经过修改的管道,该管道使用了更高分辨率的热图。具体来说,我们添加了一个卷积层和两个转置卷积层,以将热图放大到与输入图像相同的大小。这使我们能够捕获有关小物体的更详细信息,从而在密集区域中实现更准确的物体检测。在解码之前应用高斯滤波器有助于减少CenterNet中的假阳性预测。过滤器平滑热图并抑制对象周围的多个峰值。这种方法有助于提高对象的定位精度,并减少误分类的机会。
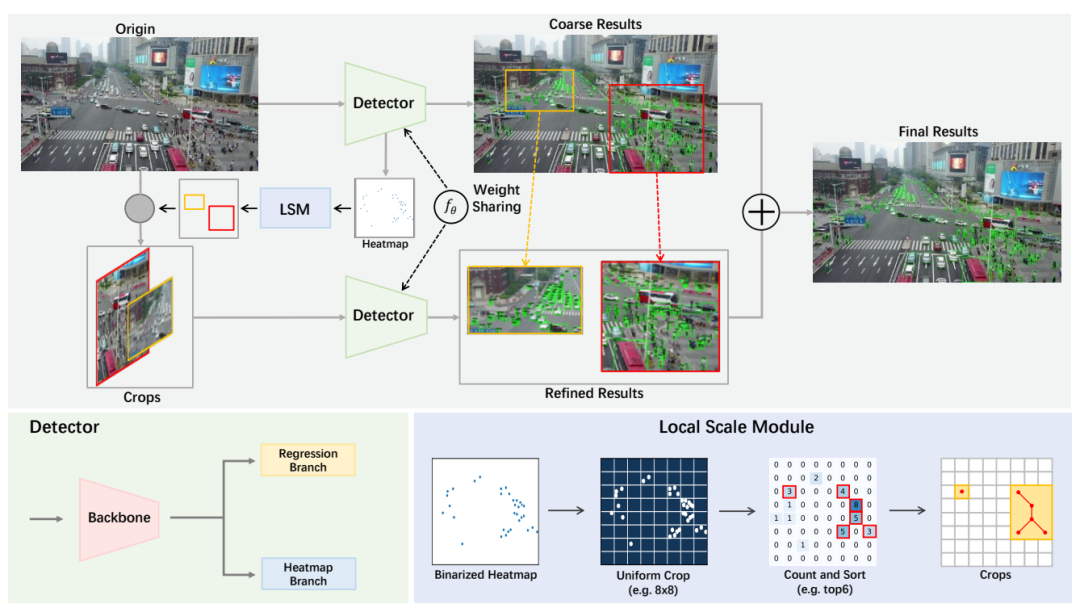
Local Scale Module
兴趣区域建议方法是基于裁剪的目标检测模型的关键组成部分。然而,在航拍图像中,车辆和行人等物体往往聚集在几个聚集的区域。图像中的大多数区域都是背景,不需要检测。此外,密集区域的有限分辨率可能会导致检测性能显著下降。现有的基于裁剪的方法,如DMNet,会产生许多作物或使用像ClusSet这样的额外网络,导致检测速度低和模型参数增加。为了解决这些问题,研究者提出了一种局部尺度模块(LSM),可以自适应地定位聚类区域。LSM受到AutoScale的启发,但研究者进行了一些修改,使其适用于航空图像。首先,LSM不是只搜索单个最大聚类区域,而是通过对每个网格中的密度进行排序来定位前K个密集区域。这很重要,因为航空图像通常有多个聚类区域。其次,AutoScale是为人群计数和定位而设计的,它只适用于具有单类目标的场景。然而,在航空图像中,有多个目标类别。研究者还注意到,UCGNet使用DBSCAN和K-Means等聚类方法从密集区域生成图像裁剪。然而,UCGNet产生的作物仍然很大,没有考虑不同作物之间的密度差异。

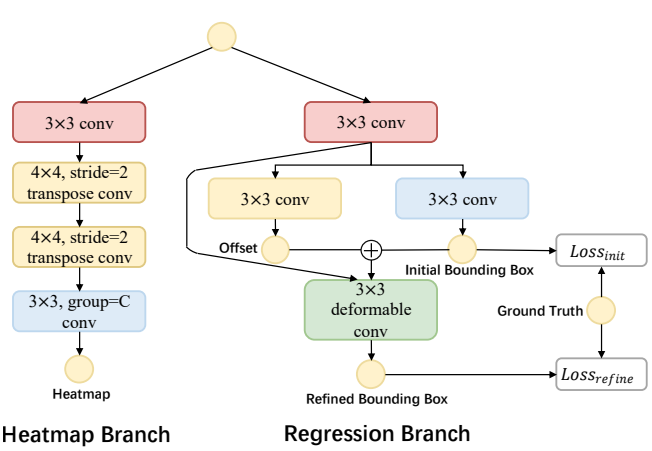
Improved Detection Head
为了提高对航空图像中小目标的检测,回归分支通过可变形卷积进行了增强,因为它可以自适应地调整卷积操作中的采样位置,以更好地捕捉小细节。此外,为了更好地捕捉不同类别目标的精细细节,热图分支被解耦为多个子分支,每个子分支负责预测特定对象类别的热图。这不仅减轻了同时预测所有热图的计算负担,而且使网络能够专注于学习每个类别的不同特征,从而提高了探测器的整体性能。下图展示了经过这些改进的检测头的结构。
PART/4
实验及可视化
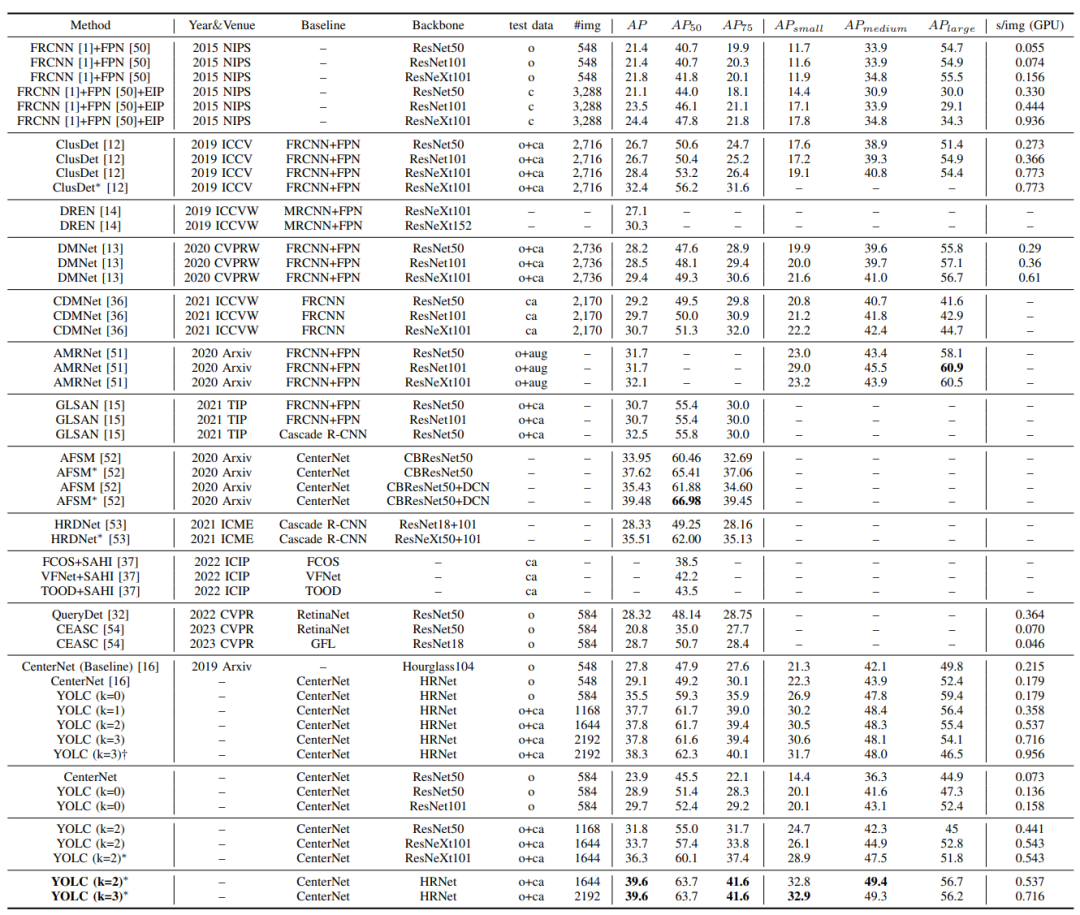
性能比较。“O”、“C”、“CA”和“AUG”分别代表原始验证集、均匀图像分割(EIP)裁剪图像、集群裁剪图像和增强图像。“*”表示多尺度推理。“†”表示通过超参数调整进行优化。
在VisDrone(第一行)和UAVDT(第二行)上可视化YOLC检测结果:

在VisDrone上可视化YOLC(右)和CenterNet(左)检测结果:


END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗
















 2388
2388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











