






点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文链接:https://arxiv.org/pdf/2409.08475
计算机视觉研究院专栏
Column of Computer Vision Institute
RT-DETR是第一个基于实时端到端Transformer的目标检测器。其效率来源于框架设计和Hungarian matching。然而与YOLO系列等密集的监督检测器相比,Hungarian matching提供了更稀疏的监督,导致模型训练不足,难以达到最佳结果。
PART/1
概述
为了解决这些问题,研究者提出了一种基于RT-DETR的分层密集正监督方法,称为RT-DETRv3。首先引入了一个基于CNN的辅助分支,该分支提供密集的监督,与原始解码器协同工作,以增强编码器的特征表示。其次为了解决解码器训练不足的问题,进一步提出了一种涉及self-att扰动的新学习策略。该策略使多个查询组中阳性样本的标签分配多样化,从而丰富了阳例。此外引入了一个共享权重解编码器分支,用于密集的正向监督,以确保更多高质量的查询与GT匹配。值得注意的是,上述所有模块都只是训练策略。
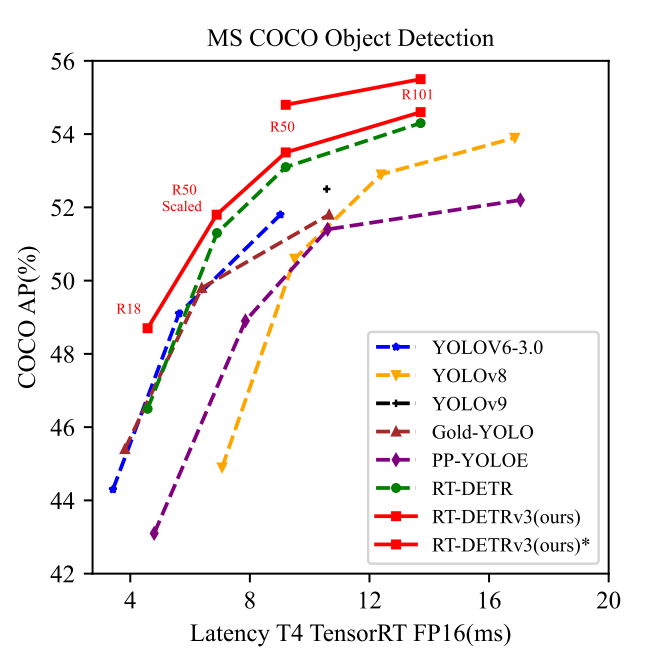
研究者进行了广泛的实验,以证明新的方法对COCOval2017的有效性。RT-DETRv3的性能明显优于现有的实时检测器,包括RT-DETR系列和YOLO系列。例如,与RT-DETR-R18/RT-DETRv2-R18相比,RT-DETRv3-R18实现了48.1%的AP(+1.6%/+1.4%),同时保持了相同的耗时。同时它只需要一半的时间就可以达到类似的性能。此外,RT-DETRv3-R101以54.6%的AP性能超越YOLOv10-X。
PART/2
背景
基于CNN的实时目标检测算法
目前基于CNN的实时目标探测器主要是YOLO系列。YOLOv4和YOLOv5优化了网络架构(例如,通过采用CSPNet和PAN),同时还利用了Mosaic数据增强。YOLOv6进一步优化了结构,包括RepVGG骨干、解耦头、SimSPPF和更有效的训练策略(例如SimOTA等)。YOLOv7引入了E-ELAN注意力模块,以更好地整合不同层次的特征,并采用自适应锚机制来提高小目标检测。YOLOv8提出了一个C2f模块,用于有效的特征提取和融合。YOLOv9提出了一种新的GELAN架构,并设计了一个PGI来增强训练过程。PP-YOLO系列是基于百度提出的飞桨框架的实时目标检测解决方案。该系列算法在YOLO系列的基础上进行了优化和改进,旨在提高检测精度和速度,以满足实际应用场景的需求。
基于Transformer的实时目标检测算法
RT-DETR是第一个实时端到端目标检测器。该方法设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来有效地处理多尺度特征,并提出了IoU感知查询选择,通过向解码器提供更高质量的初始目标查询来进一步提高性能。其精度和速度均优于同期YOLO系列,受到了广泛关注。RT-DETRv2进一步优化了训练策略,包括动态数据增强和优化采样算子以便于部署,从而进一步提高了其模型性能。然而由于它们一对一的稀疏监督,收敛速度和最终效果有限。因此引入一对多标签分配策略可以进一步提高模型的性能。
辅助训练策略
Co-DETR提出了多个并行的一对多标签分配辅助头部训练策略(例如ATSS和Faster RCNN),可以很容易地增强端到端检测器中编码器的学习能力。例如,ViT-CoMer与Co-DETR的集成在COCO检测任务上取得了最先进的性能。DAC-DETR、MS-DETR和GroupDETR主要通过向模型的解码器添加一对多监督信息来加速模型的收敛。上述方法通过在模型的不同位置添加额外的辅助分支来加速收敛或提高模型的性能,但它们不是实时目标检测器。受此启发,我们在RT-DETR的编码器和解码器中引入了多个一对多辅助密集监控模块。这些模块提高了收敛速度,改善了RT-DETR的整体性能。由于这些模块仅在训练阶段参与,因此它们不会影响RT-DETR的推理耗时。
PART/3
新框架详解
RT-DETRv3的整体结构如下图所示。
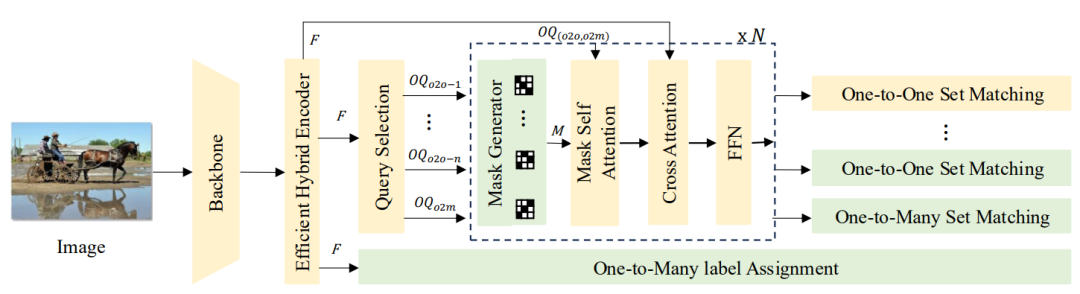
研究者保留了RT-DETR的整体框架(以黄色突出显示),并额外引入了我们提出的分层解耦密集监督方法(以绿色突出显示)。最初,输入图像通过CNN骨干网(例如ResNet)和特征融合模块(称为高效混合编码器)进行处理,以获得多尺度特征{C3、C4和C5}。然后,这些特征被并行馈送到基于CNN的一对多辅助分支和基于变压器的解码器分支中。对于基于CNN的一对多辅助分支,我们直接采用现有的最先进的密集监督方法,如PP-YOLOE,来协同监督编码器的表示学习。在基于Transformer的解码器分支中,首先对多尺度特征进行展平和级联。然后,我们使用查询选择模块从中选择前k个特征来生成目标查询。在解码器中引入了一个掩码生成器,可以生成多组随机掩码。这些掩码应用于自我关注模块,影响查询之间的相关性,从而区分正向查询的分配。每组随机掩码都与相应的查询配对,如图2中的所示。此外,为了确保有更多高质量的查询与每个gt相匹配,我们在解码器中加入了一对多标签分配分支。以下部分详细描述了本工作中提出的模块。
Overview of RT-DETR
RT-DETR是一个为目标检测任务设计的实时检测框架。它集成了DETR的端到端预测的优点,同时优化了推理速度和检测精度。为了实现实时性能,编码器模块被一个轻量级的CNN骨干网和一个为高效特征融合而设计的高效混合编码器模块所取代。RT-DETR提出了一种不确定性最小查询选择模块,用于选择高置信度特征作为目标查询,降低了查询优化的难度。随后,解码器的多层通过自关注、交叉注意力和前馈网络(FFN)模块增强这些查询,并由MLP层产生预测结果。在训练优化过程中,RT-DETR采用匈牙利语匹配进行一对一分配。对于损失计算,它使用L1损失和GIoU损失来监督盒回归,并使用可变焦点损失(VFL)来监督分类任务的学习。
基于此CNN的One-to-Many辅助分支
为了缓解解码器的一对一集匹配方案导致的编码器输出稀疏监督问题,我们引入了一种具有一对多分配的辅助检测头,如PP-YOLOE。该策略可以有效地加强对编码器的监督,使其具有足够的表示能力来加速模型的收敛。具体来说,我们直接将编码器的输出特征{C3、C4和C5}集成到PP-YOLOE头中。对于一对多匹配算法,我们遵循PP-YOLOE头的配置,在训练的早期使用ATSS匹配算法,然后切换到TaskAlign匹配算法。为了学习分类和定位任务,分别选择了VFL和分布式聚焦损失(DFL)。其中,VFL使用IoU分数作为阳性样本的目标,这使得IoU较高的阳性样本对损失的贡献相对较大。这也使得模型在训练过程中更关注高质量的样本,而不是低质量的样本。具体来说,解码器头还使用VFL损失来确保任务定义的一致性。我们将CNN辅助分支的总损失表示为Laux,相应的损失重量表示为α。
基于变压器的多组自注意力扰动分支
解码器由一系列变压器块组成,每个块都包含一个自注意力、cross-att和FFN(前馈网络)模块。最初,查询通过自注意力模块相互交互,以增强或减少它们的特征表示。随后,每个查询通过交叉注意力模块从编码器的输出特征中检索信息来更新自身。最后,FFN预测与每个查询对应的目标的类和边界框坐标。然而,在RT-DETR中采用一对一的集合匹配会导致监督信息稀疏,最终损害模型的性能。
为了确保与同一目标相关的多个相关查询有机会参与正样本学习,我们提出了基于掩码自注意的多个自注意扰动模块。这个扰动模块的实现细节如上图所示。首先,研究者通过查询选择模块生成多组目标查询,表示为OQi(i=1…N,其中N是集合的数量)。相应地,我们使用掩模生成器为每组OQi生成随机扰动掩模Mi。OQi和Mi都被输入到面具自注意模块中,从而产生扰动和融合的特征。
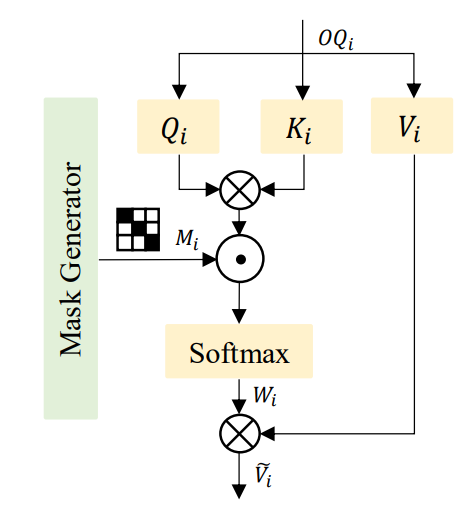
Mask Self-Attention模块的详细实现如上图所示,首先线性投影OQi以获得Qi、Ki和Vi。然后,将Qi和Ki相乘以计算注意力权重,再将注意力权重乘以Mi,并通过softmax函数得到扰动注意力权重。最后,将该扰动注意力权重乘以Vi,得到融合结果。该过程可以表示为:
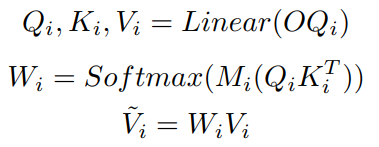
引入多组随机扰动使查询的特征多样化,允许与同一目标相关的多个相关查询有机会被分配为正样本查询,从而丰富了监督信息。在训练过程中,多组目标查询被连接并馈入单个解码器分支,从而实现了参数共享并提高了训练效率。损失计算和标签分配方案与RT-DETR保持一致。我们将第i个集的损失表示为损失,N个扰动集的总损失计算如下:
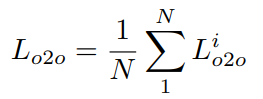
基于变压器的一对多密集监督分支
为了使多组自关注扰动分支的收益最大化,我们在解码器中引入了一个具有共享权重的额外密集监督分支。这确保了更多高质量的查询与每个基本事实相匹配。具体来说,我们使用查询选择模块来生成一组唯一的目标查询。在样本匹配阶段,通过将训练标签复制因子m来生成增强目标集,默认值为4。随后,将此增强集与查询的预测进行匹配。损失计算与原始检测损失保持一致,我们将指定为该分支的损失函数,损失权重为。整体损失如下所示:
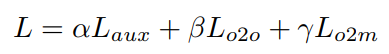
PART/4
实验及可视化
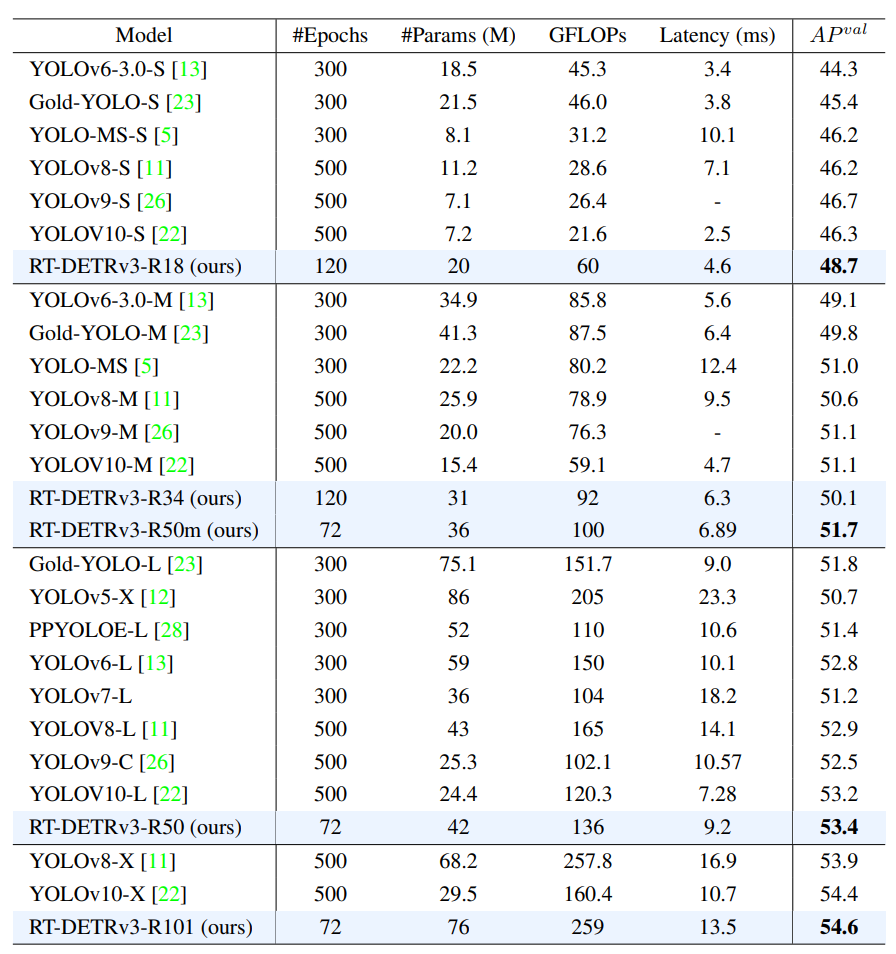
推理速度和算法性能。基于变压器架构的实时目标检测器主要由RT-DETR系列表示。表1显示了我们的方法和RT-DETR系列之间的比较结果。我们的方法在各种骨干上都优于RT-DETR和RT-DETRv2。具体而言,与RT-DETR相比,采用6倍训练计划,我们的方法显示R18、R34、R50和R101主干分别提高了1.6%、1.0%、0.3%和0.3%。与RT-DETRv2相比,我们在6x/10x训练计划下评估了R18和R34骨干,我们的方法分别提高了1.4%/0.8%和0.9%/0.2%。此外,由于我们提出的辅助密集监督分支仅用于训练,因此我们的方法保持了与RT-DETR和RT-DETRv2相同的推理速度。
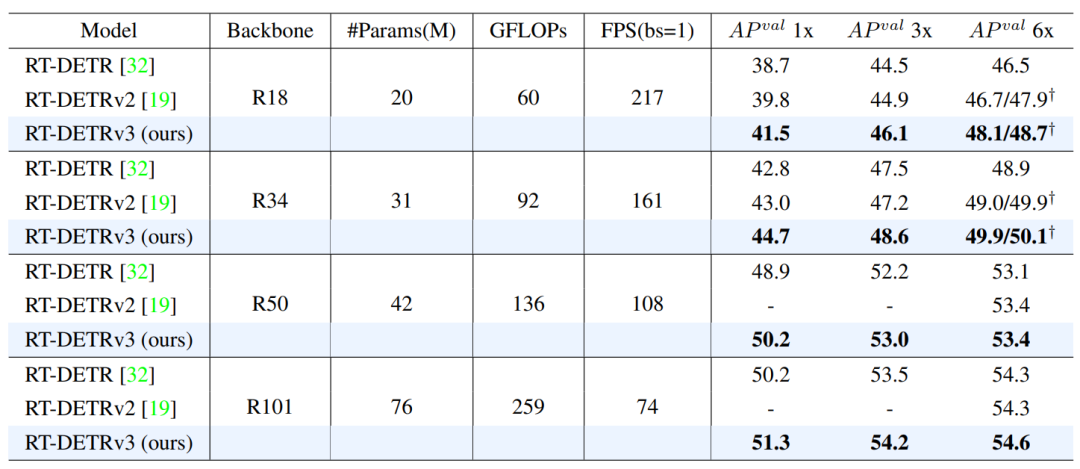
收敛速度。我们的方法基于RT-DETR框架,通过结合基于CNN和基于Transformer的一对多密集监督,不仅提高了模型性能,还加快了收敛速度。我们进行了广泛的实验来验证我们方法的有效性。表1显示了不同训练计划下RT-DETRv3、RT-DETR和RT-DETRv2的比较分析。它清楚地表明,在任何调度中,我们的方法在收敛速度方面都优于它们,只需要一半的训练周期就可以达到类似的性能。
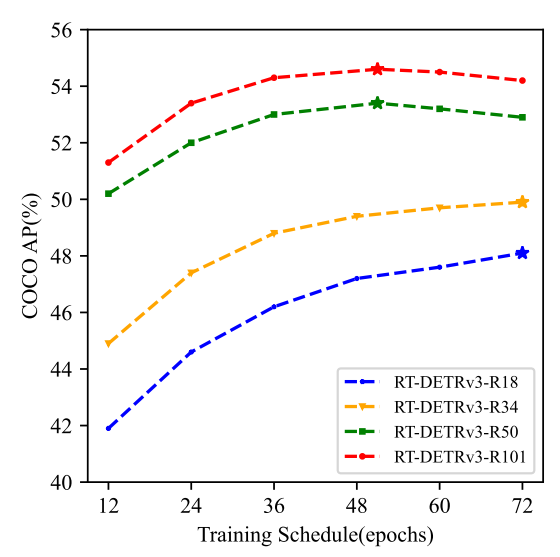
收敛速度。如下表所示,很高兴地发现,与基于CNN的实时检测器相比,RT-DETRv3在实现卓越性能的同时,可以将训练时间减少到60%甚至更少。

END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗

















 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









