






最近又被安排看一些基于深度学习的目标检测与追踪的算法,我就首先选择了YOLO,结果居然还两个版本,在这写一些自己的心得吧。
看到这篇博客,估计也都知道YOLO是干嘛的了,我就不再放YOLO的介绍了,直接将YOLO的原理吧。
YOLO这篇论文先讲的降图片划分为s*s块以及各种bounding boxes,这里感觉会让之前没看过R-CNN的人有点迷惑,当然看到这还是需要先知道CNN是干嘛的。关于CNN这里不多介绍了,网上很多,知乎上有个讲的不错,大家可以搜一下。
他这个结构是基于GoogLenet的,特点是中间的有些层采用了多尺度的卷积核,如1*1,3*3, 将这些卷积后的结果max pooling后串联,在传到下一层(GoogLenet的优点就是在宽度深度受限的情况下提高性能),最终得到的是一7*7*30的输出。
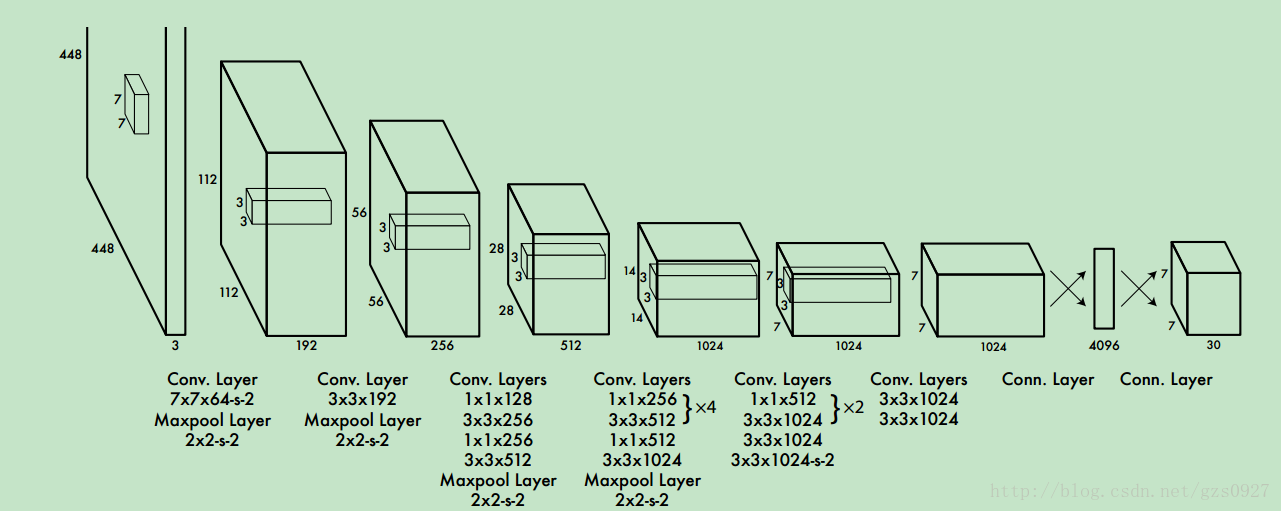
一张RGB图像转换成7*7*30的矩阵后有什么意义呢?这里再看之前提到吧图片划分成7*7的小格的目的。这里的7*7对应也就是原图像中的7*7块。那另一维度的30是由以下及部分组成,20个类的概率,所预测的bounding box的大小与位置(4个)及其一个置信度(1),而一个格子预测两个bbox,所有是(4+1)*2=10个,所以一共就是30。
那么问题来了,什么叫一个格子所预测的bbox呢,这就相当于对于任何一个格子,都会给这个格子一个任务,就是去根据自己画两个bounding boxes,这个去找bbox的过程就是神经网络向前传播的过程。所以一张图片经过神经网络会有7*7*2=98个bbox,所以如果一幅图像直接只用神经网络处理的话,得到的结果中会有98个大小位置不一的框框,其中大部分也都是错误的。那怎么去选的呢,那就是根据另一个参数,置信度,这个置信度,就是在经络神经网络的预测后,判断画出的框框中包含一个物体的可信程度。如图所示,这里就有很多的box,其中粗的是置信度高的,而其他的置信度都很低。在这98bbox中设置阈值,高于这个阈值的bbox就可以显示出来,那这个框框有了,那类别填什么呢。前边20个维度不就是概率吗,挑最高的呗。

这样又得到另一个图,这里呢每个小格子对应神经网络后预测的一个类,这样就得到了一个类别分布图,如下图所示,最后根据类分布图,也就是看之前框框里面那个类别所占面积最大,那么就选这个类作为分类结果。

举个例子,加入一幅图像划分成9个格子,预测3个类别,这样神经网络过后得到的是9*9*(3+(4+1)2)=9* 9*13的数据。假设其中置信度过阈值的在这9*9*2个bbox中有2个过阈值了,对应是第5个与第20个,那么这样对决定两个要画出来的的框框了。然后再根据类分布图,把框框里面出现最多的类别的类作为分出来的物体的类别。














 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









