







5、直接位置预测
使用anchor boxes的另一个问题是模型不稳定,尤其是在早期迭代的时候。大部分的不稳定现象出现在预测box的(x,y)坐标时。具体解释一下,就是因为一开始cell对于box位置的预测如果是全图随机的,对于一张图片来说,开始的范围很大,所以在训练初期在全图范围内变动会很大,也就是所谓的不稳定了。这里的直接位置预测说白了就是把对box位置的预测不再是基于全图,box的中心规定在cell之中。
在区域建议网络(RPN)中会预测坐标就是预测tx,ty。对应的中心点(x,y)按如下公式计算:
x=(t_x*w_a)-x_a;
y=(t_y*h_a)-y_a;
可见预测tx=1就会把box向右移动anchor box的宽度,预测tx=-1就会把box向左移动相同的距离。
这个公式没有任何限制,无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点。模型随机初始化之后将需要很长一段时间才能稳定预测敏感的物体偏移。因此作者没有采用这种方法,而是预测相对于grid cell的坐标位置,同时把ground truth限制在0到1之间(利用logistic激活函数约束网络的预测值来达到此限制)。
最终,网络在特征图(13 *13 )的每个cell上预测5个bounding box,每一个bounding box预测5个坐标值:tx,ty,tw,th,to。如果这个cell距离图像左上角的边距为(cx,cy)以及该cell对应的box维度(bounding box prior)的长和宽分别为(pw,ph),那么对应的box为:
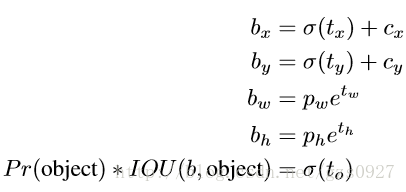
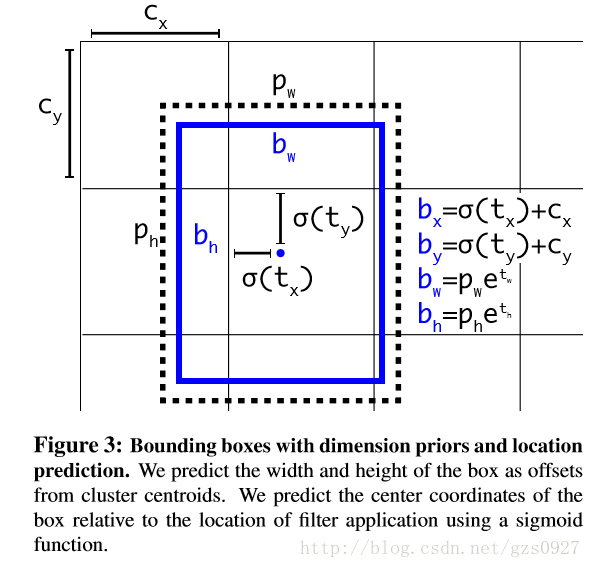
从公式可以看出,box的中心点的选择范围被logistic函数限制在相应的小格子内了。约束了位置预测的范围,参数就更容易学习,模型就更稳定。使用Dimension Clusters和Direct location prediction这两项anchor boxes改进方法,mAP获得了5%的提升。
多尺度训练
原始YOLO网络使用固定的448 * 448的图片作为输入,加入anchor boxes后输入变成416 * 416,由于网络只用到了卷积层和池化层,就可以进行动态调整(检测任意大小图片)。为了让YOLOv2对不同尺寸图片的具有鲁棒性,在训练的时候也考虑了这一点。
不同于固定网络输入图片尺寸的方法,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320 * 320,最大的尺寸为608 * 608。 调整网络到相应维度然后继续进行训练。
这种机制使得网络可以更好地预测不同尺寸的图片,同一个网络可以进行不同分辨率的检测任务,在小尺寸图片上YOLOv2运行更快,在速度和精度上达到了平衡。
在低分辨率图片检测中,YOLOv2是检测速度快(计算消耗低),精度较高的检测器。输入为228 * 228的时候,帧率达到90FPS,mAP几乎和Faster R-CNN的水准相同。使得其更加适用于低性能GPU、高帧率视频和多路视频场景。
在高分辨率图片检测中,YOLOv2达到了先进水平(state-of-the-art),VOC2007 上mAP为78.6%,而且超过实时速度要求。















 436
436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









