







临近2024年末,GPT 5迟迟未出,似乎预示着大模型 Scaling Law 遭遇了瓶颈。
但是,我们也看到,大模型在即将过去的一年仍然快速演进,展现出更加强大的文本理解及生成能力,以及复杂任务的推理能力。
最近我交流的很多企业,都在积极将人工智能的探索与应用,纳入到2025年的年度计划当中。
然而,企业要么处于不知道该具体做什么和怎么做的状态,要么对部署和应用大模型存在过高的期望,忽视了其本身的局限性和实际应用中的挑战。
本文就来探讨企业在应用大模型时可能遇到的挑战,以及如何选择适合的场景,采用工程化应用和阶段性方法论,让企业在AI大模型的投资,产生看得见的业务价值。
1
大模型不能“点石成金”
很多时候,我们会被**大模型表面上的“能说会道”**迷惑,误以为:只要在企业部署了大模型,就能在各种业务场景下发挥作用。
这里讲的大模型,指的是通用的预训练大语言模型,其使用了大量文本语料做预训练,用于文本的理解和生成。
实际上,大模型的能力虽很强,但在企业级场景,并非即插即用。
主要问题有三个。
1. 大模型不懂行业与内部话语
大模型是在特定知识和数据上做的预训练,一旦训练完成,难以动态更新知识。
同时,大模型还缺乏特定领域的知识,包括企业所在行业的专业知识,以及企业内部人才听得懂的“行话”等等。
因此,大模型不可能对一个没有正确理解的专业问题,提供精确、可靠的答案。
2. 大模型不太会逻辑推理
大模型擅长“文字接龙”。
当前,大模型厂商还在努力提升大模型的逻辑推理能力。比如, OpenAI 的 o1模型和 DeepSeek 最近上线的R1-Lite模型,都在试图解决数学、代码等复杂推理问题。
然而, 企业的应用场景并非数学竞赛。
大模型在数学能力上的评测高分,不一定能在企业场景中产生预期的效果。
3. 大模型回答的准确性存疑
大模型缺乏可解释性,输出不稳定,可能会出现幻觉。
这在文娱创意类行业,如网络小说、创意图片等,也许问题不大,甚至是加分项。
但在企业级应用场景,比如生成专业报告、数据图表分析、给出决策意见等方面,企业很难接受包含错误信息的内容。
甚至,判定大模型的输出是否正确,本身也是个问题。
目前,我们对大模型输出内容的正确性没有特别好的评测方法。在很多情况下,还是依赖于人工评估。
2
怎么从“玩具”走出来
市场上众多的文档问答、AI搜索等应用,还停留在“玩具”的水平,只能处理简单的任务,无法应对需要深度分析的复杂问题。
原因有三点。
第一,用户提出的问题往往不是简单的查询,而是需要深层次分析和推理的问题。
这些问题在现有的文档中往往没有直接的答案,需要AI通过复杂的推理过程来得出新的见解。
这意味着大模型必须具备超越表面信息,深入挖掘和理解数据的能力,以便为用户提供真正有价值的答案。
第二,分析过程的复杂性要求系统能够处理多个步骤和环节,而不是仅仅依赖一次检索和回答。
这涉及到对问题的分解、相关信息的整合、以及多维度的分析,以确保答案的全面性和准确性。
大模型需要能够理解问题背后的复杂性,调用相应的工具和智能体,并采取相应的策略来逐步解决问题。
第三,仅输出文本不能满足企业级场景需求。
在智能化时代,用户不仅需要文字答案,更期待得到包含结构化数据、图表、表格和图像的丰富内容。
这要求大模型不仅要能够生成文本,还要能够整合和展示多种类型的数据,以提供更直观、更易于理解的信息。
所以,实际情况远比想象的复杂!
我们想让大模型应用,避免成为一时新鲜的“玩具”,就必须****提升系统的多链路深层次分析能力,处理复杂任务的能力,以及理解与生成多模态内容的能力。
3
在哪些场景探索应用
选对了场景,就成功了一半。
对于绝大多数企业而言,不能也没有必要先花费重金,构筑AI算力基础设施。
我们应从一个场景切入,做到眼前一亮,激发和凝聚AI应用的共识。
企业如何选择AI应用场景呢?我们要考虑三个因素:
-
业务相关性
-
技术成熟度
-
使用频次
首先,看业务相关性。
举一个例子。比如法律、医疗、科研等行业,专业性非常强。其业务特点是:
-
大量的知识输入,如书籍、文献资料等
-
经过律师、医生、研究院等专业人士的分析
-
进行大量的输出,如学术成果、报告等
那么,构建一个面向专业人士的“AI助手”,结合行业领域知识库,解决其中某个特定问题,显著提升专业人士的工作效率,将是一个业务强相关的好场景。
其次,看技术成熟度。
如前文所述,当前大模型应用系统,在处理复杂任务时还力不从心。因此,我们不能一开始就选择高难度场景,而是从技术成熟度比较高的场景切入。
实际上,前文所述的“AI助手”,目前要实现端到端的能力,技术成熟度还不够高,大概率会让专业人士失望。
但是,目前知识检索的技术成熟度已经非常高,运用文档解析、全文检索、向量检索、融合、重排等技术可以很好地解决问题。
这时,我们可以先聚焦在“大量的知识输入“这个特定阶段,解决专业人士收集、整理、检索大量知识的难题,让专业人士可以集中精力在分析处理上。
第三,看使用频次。
我常说,很多数字化转型项目,最终“领导不认可、员工无感知”。使用频次会极大地影响员工感知度。
我们要尽量选择高频的使用场景,不但能产生更大的业务价值,也能提升项目的可见度和影响力。
例如,面向内外部客户的智能客服、企业制度流程智能问答等场景,技术成熟度和使用频次都比较高,是可供大多数企业选择切入的好场景。
当然,大模型应用落地场景还有很多,包括智能推荐、用户画像、业务预测、风险评估等等。
重点在于结合企业的实际情况,按照以上三个因素,仔细评估和选择。实现项目预期可管理,投资可控,产出看得见,成果令人满意。
4
工程化应用的关键是什么
大模型不能“点石成金”,其本身在快速发展中,各类应用的技术成熟度也不一样。
企业在选择的场景上发起的每一个项目,都不是简单的软硬件部署,而是要在工程化上做很多的工作。
关注以下三点。
第一,使用大模型API服务。
通用大模型的发展,称得上日新月异。
有些企业可能会使用专有语料,通过微调训练生成自己的模型,在特定任务上短期可媲美通用大模型。
但是,企业很难在专有模型的研发与持续迭代上,达到与大模型厂商同样的速度与水平,长期来看很难追赶通用大模型能力的提升。
因此,我建议企业尽可能采用通用****大模型API + 本地知识库的方式,更好地利用通用大模型的能力,同时保障本地数据的安全。
对于一些特定任务,模型参数并不要求很高,比如60亿参数的模型就可以解决问题。企业可采购相应的算力资源,在本地进行模型的训练和推理,并为AI应用提供API服务。
这种模式,适合于对数据安全有更严格的要求,或者整个系统处于内网环境的情况。
第二,融合领域知识与数据。
采用大模型检索增强生成(RAG) 技术,已经成为大模型在各行各业应用的主流方式。
知识库可以使大模型更好地适应特定领域的专业知识,可以实时动态更新,是大模型的完美搭档。
但是,这对知识库的构建和管理,提出了更高的要求。
我们需要对文档、网页、图片等非结构化数据,进行解析、分块等处理,并尽可能保留这些信息元素,彼此之间的结构关系、语义关系。
这就要在系统中,引入优秀的文档解析工具,各种小模型以及向量数据库、图数据库等工具,并进行完美的集成。
另一方面,企业还要对现有关系型数据库中的数据,进行数据治理,提升数据质量。然后,通过NL2SQL模型、数据服务API、智能体工具调用等方式,集成到大模型应用系统中。
当我们构建了企业级知识库和数据仓库,特别关键的是,我们要确保整个大模型应用系统,符合数据安全、网络安全和个人隐私保护等法律法规的要求。
第三,打造非凡的用户体验。
通常,对于ToB的企业软件系统,人们主要关注功能点是否满足,根据功能需求清单进行项目验收。
然而,系统的用户体验常常被忽视。
企业的每一个应用系统,实际上都有最终用户。用户是否信任这个系统,喜欢使用这个系统,对于系统的成败至关重要。
基于大模型应用的特点,我们需要特别注意以下两点,并纳入到工程项目中。
1. 输出的可解释性
大模型是一个“黑盒”,人们目前还没有真正弄清楚,大模型何以出现“涌现”的能力。
在企业级应用中,我们应提高整个系统的可解释性,将数据来源、分析、工具调用与输出的步骤,展示给用户,以增强用户对输出结果的信任。
2. 提升用户使用体验
即使是企业级应用系统,我们也应该按照互联网产品思维,从产品原型和MVP开始,注重UI/UE,对系统的每一个细节,进行精心设计。
我们要提供有设计感和不言自明的用户操作界面,以符合用户的期望和习惯,从而打造让用户喜爱的系统。
5
如何有效地推动AI落地
生成式人工智能,已经是确定的方向!
企业不能再踌躇不前,而是应该积极投入、敢于投入。
面对大模型应用的复杂性,企业需要采取一种阶段性的方法论来指导实践。
红杉中国在《2024年企业数字化年度指南》中提出,企业落地AIGC应用的“AGILE五步方法论”,可以作为我们可以参考的框架。
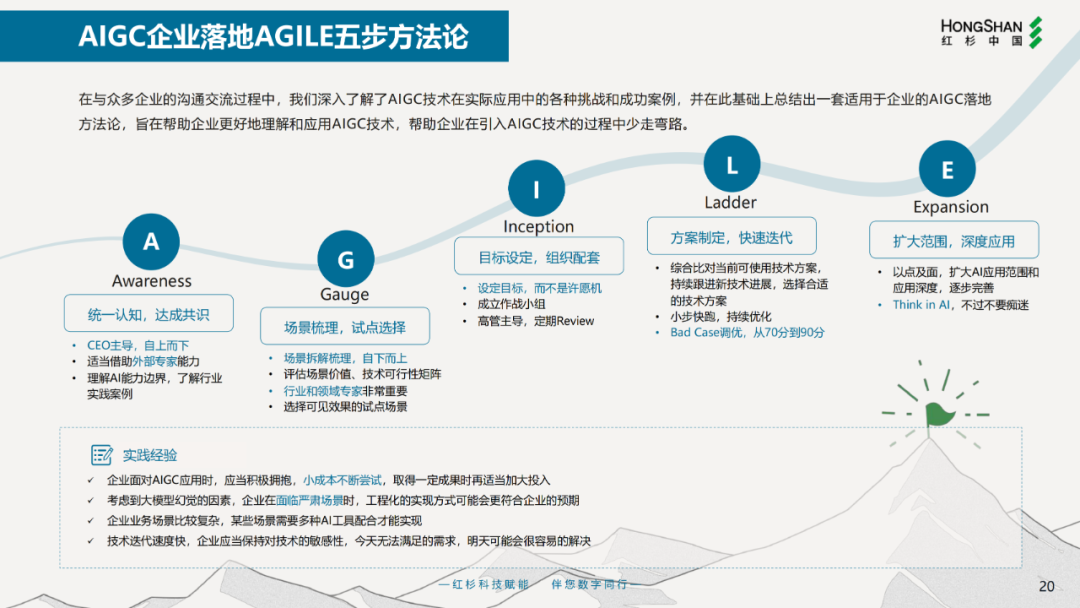 来源:红杉中国《2024企业数字化年度指南》
来源:红杉中国《2024企业数字化年度指南》
1. 认知(Awareness)
在AI技术引入的初期,要自上而下形成统一认知和达成共识,尤其是企业CEO和高级管理层,需要对AI能力的边界和行业实践案例有所了解。
建议企业借助外部咨询专家的协助,开展AI应用相关培训和规划设计。
2. 评估(Gauge)
达成共识后,企业需要进一步评估,哪些业务场景适合应用AI技术,以及应用该技术可带来哪些价值。
企业可参考上文提到的“业务相关性、技术成熟度、使用频次”三个因素对每一个场景进行评估,并邀请行业和领域专家参与,全面评估其价值潜力和技术可行性。
3. 开动(Inception)
构想不能停留在纸面上,而是必须选择试点项目,推动落地。
试点项目应有较好的投资回报率ROI,形成示范效应,为未来持续的投入奠定基础。对于创新型项目,企业需要设定合理的目标预期,做好相应的组织配套,如组建专门的“作战小组”,负责统筹规划与执行。
4. 阶梯(Ladder)
进入实操阶段后,企业要根据业务场景特点,比对评估当下可采用的各种AI大模型应用方案,持续跟进最新技术发展,选取最优解决方案。
同时,企业还要注意,在实施过程中,不能期望一蹴而就,而是要**小步快跑、**快速迭代。
5. 扩大(Expansion)
在试点项目落地获得成功后,就要进一步“以点及面”,不断扩大AI应用的范围和深度。
企业要把“Think in AI”的理念,融入到业务发展的各个环节和更多的场景中去。同时,还要保持清醒。毕竟,AI应用并非企业数字化转型的全部。
6
结束语
总结而言,企业数字化转型已经在向智能化转型迈进。以大模型为代表的生成式人工智能技术的应用,已经成为企业的一道“必答题”。
生成式人工智能,无疑是未来十年最有潜力的生产力工具。
企业在应用大模型时,应选择合适的场景,平衡投入与回报,并制定全面的应对策略以实现真正的价值落地。
通过工程化应用、阶段性方法论,企业可以更好地推动AI技术落地,实现业务效率的提升。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









