






ConvNeXt V2
Paper : ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Author : Sanghyun Woo, Shoubhik Debnath, Ronghang Hu,Xinlei Chen, Zhuang Liu,In So Kweon, Saining Xie
Affiliation :KAIST , Meta AI FAIR ,New York University
Publication :CVPR 2023
Code :https://github.com/facebookresearch/ConvNeXt-V2
在设计Mask自编码器时,将Mask输入视为一组稀疏块,并使用稀疏卷积仅处理可见部分。
添加一个 Global Response Normalization 全局响应归一化层来增强通道间特征竞争。
共同设计了 ConvNext V2 与 FCMAE
0 前景
神经网络架构设计的创新一直在表征学习领域发挥着重要作用。卷积神经网络架构 (ConvNets) 对计算机视觉研究产生了重大影响,因为它允许使用通用特征学习方法完成各种视觉识别任务 ,而不是依赖于手动特征工程。近年来,最初为自然语言处理开发的 Transformer 架构 也因其在模型和数据集大小方面的强大扩展行为而广受欢迎 。最近,ConvNeXt 架构对传统的 ConvNets 进行了现代化改造,并证明了纯卷积模型也可以是可扩展的架构。然而,探索神经网络架构设计空间的最常用方法仍然是通过对 ImageNet 上的监督学习性能进行基准测试。
在另一项研究中,视觉表征学习的重点已经从带标签的监督学习转向带借口目标的自监督预训练。在许多不同的自监督算法中,Mask自编码器 (MAE) 最近将Mask语言建模的成功带到了视觉领域,并迅速成为一种流行的视觉表征学习方法。然而,自监督学习的一种常见做法是使用为监督学习设计的预定架构,并假设该设计是固定的。
1 动机
简单地结合 ConvNeXt 和 MAE 这两种方法会导致性能不佳。
一个问题是 MAE 具有特定的编码解码器设计,该设计针对 Transformer 的序列处理能力进行了优化,这使得计算量大的编码器能够专注于可见的块,从而降低预训练成本。该设计可能与使用密集滑动窗口的标准 ConvNets 不兼容。此外,如果不考虑架构和训练目标之间的关系,可能不清楚是否能够实现最佳性能。事实上,先前的研究表明,使用基于 mask 的自监督学习训练 ConvNets 可能会很困难 ,并且经验证据表明,Transformer 和 ConvNets 可能具有不同的特征学习行为,从而影响表示质量。
2 方法(Fully Convolutional Masked Autoencoder)
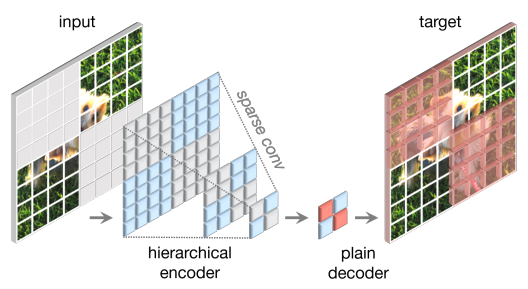
学习信号是通过以高Mask率随机Mask原始输入视觉效果并让模型根据剩余上下文预测缺失的部分来生成的。
作者引入了一个完全卷积Mask自动编码器 (FCMAE)。它由一个基于稀疏卷积的 ConvNeXt 编码器和一个轻量级 ConvNeXt 块解码器组成。总体而言,作者的自动编码器的架构是不对称的。编码器仅处理可见像素,解码器使用编码像素和掩码标记重建图像。仅在Mask区域上计算损失。
Masking
作者使用随机Mask策略,Mask率为 0.6。由于卷积模型具有分层设计,其中特征在不同阶段进行下采样,因此Mask在最后阶段生成并递归上采样直至最精细的分辨率。为了在实践中实现这一点,作者从原始输入图像中随机删除 60% 的 32×32 块。作者使用最少的数据增强,仅包括随机调整大小的裁剪。
Encoder design
在作者的方法中,作者使用 ConvNeXt 模型作为编码器。使 masked 图像建模有效的一个挑战是防止模型学习允许其从masked 区域复制和粘贴信息的捷径。这在基于 Transformer 的模型中相对容易防止,这可以将可见的补丁作为编码器的唯一输入。然而,使用 ConvNets 实现这一点更加困难,因为必须保留 2D 图像结构。虽然简单的解决方案涉及在输入端引入可学习的mask token,但这些方法降低了预训练的效率并导致训练和测试时间不一致,因为测试时没有mask标记。当mask 率很高时,这尤其成问题。 为了解决这个问题,作者的新见解是从“稀疏数据视角”查看mask图像,这是受到 3D 任务中对稀疏点云的学习的启发 。作者的主要观察是蒙版图像可以表示为 2D 稀疏像素阵列。基于这一见解,将稀疏卷积纳入作者的框架以促进Mask自动编码器的预训练是很自然的。在实践中,在预训练期间,作者建议用子流形稀疏卷积转换编码器中的标准卷积层,这使模型能够仅在可见数据点上运行。 作者注意到,稀疏卷积层可以在微调阶段转换回标准卷积,而无需额外处理。作为替代方案,也可以在密集卷积操作之前和之后应用二元Mask操作。此操作在数值上具有与稀疏卷积相同的效果,理论上计算量更大,但在TPU等AI加速器上更友好。
spcon (sparse convolution)
[稀疏卷积 Sparse Convolution Net-CSDN博客](https://blog.csdn.net/qq_39523365/article/details/123281523?ops_request_misc=&request_id=&biz_id=102&utm_term=the sparse convolution&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-123281523.142v100pc_search_result_base6&spm=1018.2226.3001.4187)
Decoder design.
作者使用轻量级、简单的 ConvNeXt 块作为解码器。这总体上形成了一个不对称的编码器解码器架构,因为编码器更具有层次结构。作者还考虑了更复杂的解码器,例如分层解码器 或 Transformer,但更简单的单个 ConvNeXt 块解码器在微调精度方面表现良好,并且大大减少了预训练时间,如表 1 所示。作者将解码器的维度设置为 512。

Reconstruction target.
作者计算重建图像和目标图像之间的均方误差 (MSE)。 与 MAE 类似,目标是原始输入的逐块归一化图像,损失仅适用于被遮盖的块。
Global Response Normalization
作者引入了一种新的全局响应归一化 (GRN) 技术,使 FCMAE 预训练与 ConvNeXt 架构结合更有效。作者首先通过定性和定量特征分析来激发作者的方法。
特征崩溃
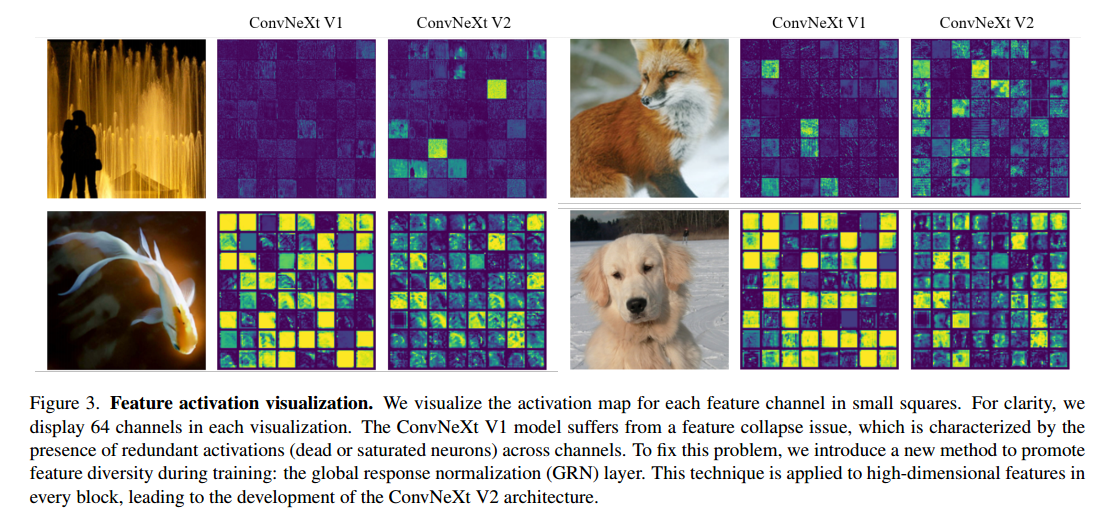
为了更深入地了解学习行为,作者首先在特征空间中进行定性分析。作者将 FCMAE 预训练的 ConvNeXt-Base 模型的激活可视化,并注意到一个有趣的“特征崩溃”现象:有许多死的或饱和的特征图,并且激活在各个通道之间变得冗余。作者在图 3 中展示了一些可视化效果。这种行为主要在 ConvNeXt 块中的维度扩展 MLP 层中观察到 。
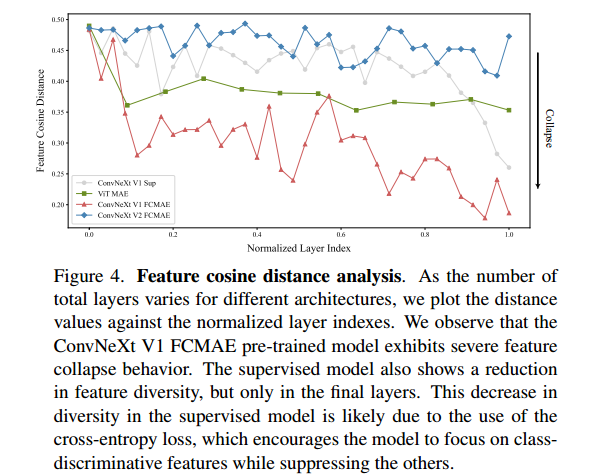
Feature cosine distance analysis.
给定激活张量 X ∈ R H × W × C , X i ∈ R H × W X \in R^{H×W×C},X_i \in R^{H×W} X∈RH×W×C,Xi∈RH×W 是第 i 个通道的特征图。作者将其重塑为 HW 维向量,并计算各通道间平均成对余弦距离

距离值越大,表示特征越多样化,距离值越低,表示特征冗余。
Approach
大脑中有许多机制可以促进神经元的多样性。例如,侧向抑制可以帮助增强激活神经元的反应,增加单个神经元对刺激的对比度和选择性,同时增加整个神经元群体的反应多样性。在深度学习中,这种形式的侧向抑制可以通过响应归一化来实现 。在这项工作中,作者引入了一个新的响应归一化层,称为全局响应归一化 (GRN),旨在增加通道的对比度和选择性。给定一个输入特征 X ∈ R H × W × C X \in R^{H×W×C} X∈RH×W×C ,提出的 GRN 单元包括三个步骤:1)全局特征聚合,2)特征归一化,3)特征校准

提供的伪代码描述了一种使用类似PyTorch风格的全局响应归一化(GRN)方法。以下是对每一步的详细解释:
- 计算输入张量
X在空间维度(高度和宽度)上的L2范数(gx):gx = torch.norm(X, p=2, dim=(1,2), keepdim=True)- 这行代码计算了每个通道在高度和宽度维度上的L2范数,结果是一个形状为
(N, 1, 1, C)的张量gx,其中N是批量大小,C是通道数。
- 对
gx进行归一化,得到nx:nx = gx / (gx.mean(dim=-1, keepdim=True) + 1e-6)- 这行代码首先计算
gx在通道维度上的平均值,然后将其加到gx上进行归一化。1e-6是一个小常数,用于防止除零错误。归一化后的结果是一个形状为(N, 1, 1, C)的张量nx。
- 应用可学习的仿射变换参数
gamma和beta,并对输入张量X进行缩放和偏移:return gamma * (X * nx) + beta + X- 这行代码首先将输入张量
X与归一化后的张量nx相乘,然后乘以可学习的参数gamma,再加上可学习的参数beta和原始输入张量X。最终返回处理后的张量。
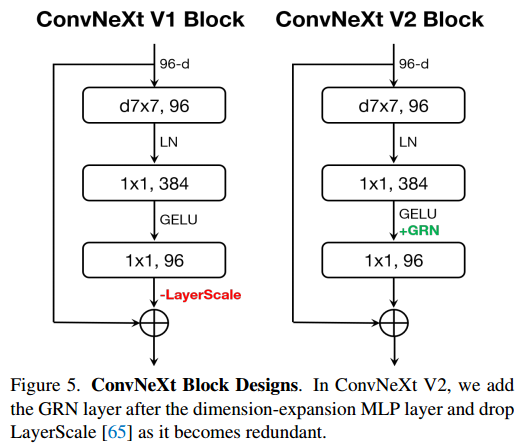
总结来说,这个GRN方法通过计算每个通道的全局响应并进行归一化,然后应用可学习的缩放和偏移参数,来增强模型的表达能力。这种方法在某些情况下可以提高模型的性能,特别是在处理图像数据时。作者将 GRN 层合并到原始 ConvNeXt 块中,如图 5 所示。作者通过经验发现,当应用 GRN 时,LayerScale [65] 变得不必要,可以将其删除。
配备 GRN 后,FCMAE 预训练模型的表现可显著优于 300 个 epoch 监督模型。GRN 通过增强特征多样性来提高表示质量,而这在 V1 模型中是不存在的,但已被证明对于基于掩码的预训练至关重要。请注意,这种改进是在不增加额外参数开销或增加 FLOPS 的情况下实现的。
3 实验
作者展示了这些设计可以很好地协同工作,并为将模型扩展到各种尺寸提供了坚实的基础。此外,作者通过实验将作者的方法与以前的掩码图像建模方法进行了比较。此外,作者展示了作者最大的 ConvNeXt V2 Huge 模型,该模型已使用 FCMAE 框架进行预训练并在 ImageNet-22K 数据集上进行了微调,仅使用公开可用的数据,就可以在 ImageNet-1K 数据集上实现 88.9% 的 top-1 准确率的新最高水平。
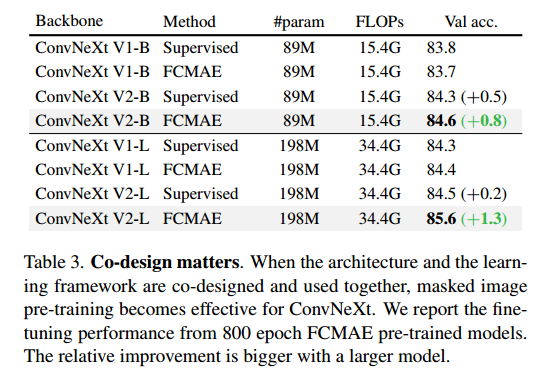
Co-design matters.
在本文中,作者进行了一项独特的研究,通过对自监督学习框架 (FCMAE) 和模型架构改进 (GRN 层) 的学习行为进行实证研究,共同设计了自监督学习框架 (FCMAE) 和模型架构改进 (GRN 层)。表 3 中显示的结果证明了这种方法的重要性。 作者发现,在不修改模型架构的情况下使用 FCMAE 框架对表示学习质量的影响有限。同样,新的 GRN 层对监督设置下的性能影响相当小。然而,两者的结合导致微调性能显着改善。这支持了这样一种观点:应该同时考虑模型和学习框架,特别是在自我监督学习方面。
对比
作者将作者的方法与以前的Mask自动编码器方法 进行了比较,这些方法都是为基于Trasformer的模型设计的。结果总结在表 4 中。作者的框架在所有模型大小上都优于使用 SimMIM 预训练的 Swin Trasformer。与使用 MAE 预训练的普通 ViT 相比,作者的方法在大型模型范围内的表现相似,尽管使用的参数要少得多(198M vs 307M)。然而,在巨大的模型范围内,作者的方法略有落后。这可能是因为巨大的 ViT 模型可以从自监督预训练中受益更多。正如作者接下来将看到的,通过额外的中间微调可能会缩小差距。
微调
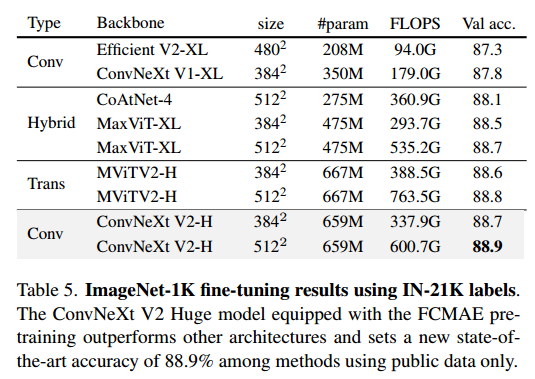
作者还展示了 ImageNet-22K 中期微调结果 。训练过程包括三个步骤:1)FCMAE 预训练,2)ImageNet-22K 微调,3)ImageNet1K 微调。作者使用 38 4 2 384^2 3842 分辨率图像进行预训练和微调 。作者将结果与最先进的架构设计进行比较,包括基于卷积的 、基于Transformer的和混合设计 。所有这些结果都是用 ImageNet22K 监督标签训练的。结果总结在表 5 中。作者的方法使用基于卷积的架构,仅使用公开可用的数据(即 ImageNet-1K 和 ImageNet-22K)就创下了新的最先进的准确率。
消融
解码器消融实验如表1所示。
GRN消融如表2所示。在表 2d 中,作者将 GRN 与三个广泛使用的规范化层进行了比较:局部响应规范化 (LRN) 、批量规范化 (BN) 和层规范化 (LN) 。作者观察到只有 GRN 的表现可以显着优于监督基线。LRN 缺乏全局上下文,因为它仅对比附近邻居内的通道。BN 沿批处理轴在空间上进行规范化,这不适合掩码输入。 LN 通过全局均值和方差标准化隐式地鼓励特征竞争,但效果不如 GRN。
增强神经元间竞争的另一种方法是使用动态特征门控方法。在表 2e 中,作者将 GRN 与两个经典门控层进行了比较:squeeze-andexcite (SE) 和卷积块注意模块 (CBAM) 。SE 专注于通道门控,而 CBAM 专注于空间门控。这两个模块都可以增加各个通道的对比,类似于 GRN 所做的。 GRN 更简单、更高效,因为它不需要额外的参数层(例如 MLP)。
最后,作者研究了 GRN 在预训练和微调中的重要性。作者在表 2f 中展示了结果,其中作者要么从微调中移除 GRN,要么仅在微调时添加新初始化的 GRN。无论哪种方式,作者都观察到显着的性能下降,这表明在预训练和微调中保留 GRN 很重要。

迁移学习
作者现在对迁移学习性能进行基准测试。 首先,作者评估共同设计的影响,即比较 ConvNeXt V1 + 监督与 ConvNeXt V2 + FCMAE。作者还直接将作者的方法与使用 SimMIM 预训练的 Swin Transformer 模型进行比较。
COCO 上的对象检测和分割
作者在 COCO 数据集上微调 Mask R-CNN ,并在 COCO val2017 集上报告检测 mAPbox 和分割 mAPmask。结果如表 6 所示。随着作者的提案的应用,作者看到了逐步的改进。从 V1 到 V2,GRN 层是新引入的并提高了性能。在此基础上,当从监督学习转向基于 FCMAE 的自监督学习时,模型进一步受益于更好的初始化。当两者一起应用时,性能最佳。 此外,作者最终的方案 ConvNeXt V2 在 FCMAE 上进行了预训练,在所有模型大小上都优于 Swin transformer 同类产品,在大型模型中差距最大。
ADE20K 上的语义分割
总而言之,作者使用 UperNet 框架 对 ADE20K 语义分割任务进行了实验。作者的结果显示出与物体检测实验相似的趋势,作者的最终模型比 V1 监督同类产品有显著改进。它的表现也与 Backbo 相当在基础和大型模型中优于 Swin Transformer,但在巨型模型中优于 Swin
总结
在本文中,作者介绍了一种新的 ConvNet 模型系列,称为 ConvNeXt V2,它涵盖了更广泛的复杂性。虽然架构变化很小,但它专门设计为更适合自监督学习。使用作者的全卷积Mask自动编码器预训练,作者可以显著提高纯 ConvNets 在各种下游任务中的性能,包括 ImageNet 分类、COCO 对象检测和 ADE20K 分割。
onvNet 模型系列,称为 ConvNeXt V2,它涵盖了更广泛的复杂性。虽然架构变化很小,但它专门设计为更适合自监督学习。使用作者的全卷积Mask自动编码器预训练,作者可以显著提高纯 ConvNets 在各种下游任务中的性能,包括 ImageNet 分类、COCO 对象检测和 ADE20K 分割。


















 4486
4486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











