







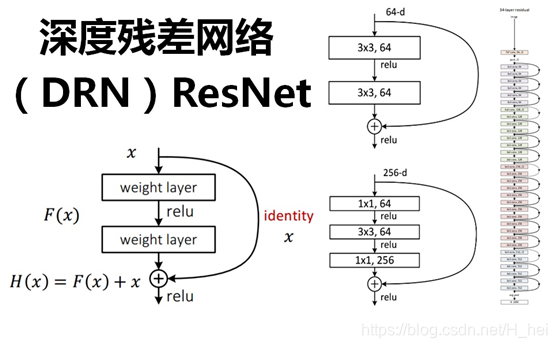
Deep Residual Learning for Image Recognition
1. 思想
作者根据输入将层表示为学习残差函数。实验表明,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率。
核心是解决了增加深度带来的副作用(退化问题),这样能够通过单纯地增加网络深度,来提高网络性能。
- 作者在ImageNet上实验了一个152层的残差网络,比VGG深8倍,取得了3.57%的错误率。
- 作者通过一系列实验证明了表示的深度(即网络的深度)对很多视觉识别任务都至关重要。仅仅由于使用了非常深的网络,作者就在COCO目标检测数据集上获得了28%的相对提升。
2. 一些问题
网络的深度为什么重要?
因为CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
为什么不能简单地增加网络层数?
① 对于原来的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。
- 对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。
② 虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。
退化问题说明了深度网络不能很简单地被很好地优化。
作者通过实验:通过浅层网络+ y=x 等同映射构造深层模型,结果深层模型并没有比浅层网络有等同或更低的错误率,推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。?
怎么解决退化问题?
深度残差网络。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
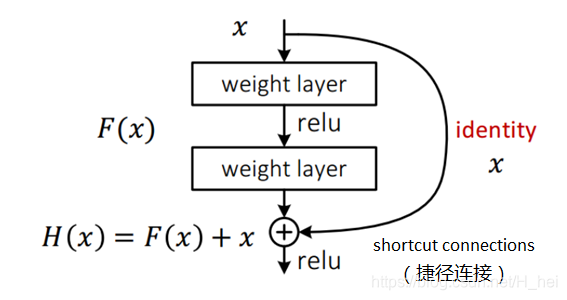
其他的参考解释
- F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F’(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F’和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F’的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器…详细地址。
- 至于为何shortcut的输入时X,而不是X/2或是其他形式。kaiming大神的另一篇文章[2]中探讨了这个问题,对以下6种结构的残差结构进行实验比较,shortcut是X/2的就是第二种,结果发现还是第一种效果好。
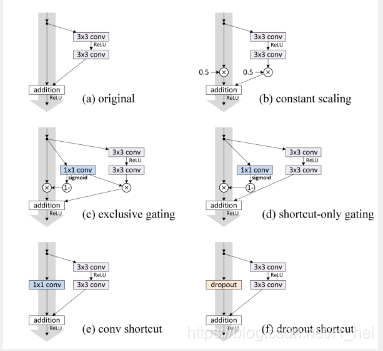
- 这种残差学习结构可以通过前向神经网络+shortcut连接实现,如结构图所示。而且shortcut连接相当于简单执行了同等映射,不会产生额外的参数,也不会增加计算复杂度。 而且,整个网络可以依旧通过端到端的反向传播训练。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









