







 超级会员免费看
超级会员免费看
一、嵌入模型(Embedding Model)是什么?
1. 定义
-
嵌入模型是一种将文本、图像、音频等非结构化数据转化为**低维稠密向量(Dense Vector)**的算法模型,这些向量(通常几百到几千维)能够捕捉数据的语义信息。
-
核心目标:将抽象内容转化为计算机可理解的数值形式,同时保留其语义关联性。
2. 关键特性
-
语义保留:相似内容的向量在向量空间中距离相近(例如“猫”和“犬”的向量距离较近)。
-
跨模态对齐:部分模型可对齐不同模态(如文本与图片)的向量空间(CLIP模型)。
-
降维压缩:将高维稀疏数据(如One-Hot编码)压缩为低维稠密表示。
3. 常见类型
-
词嵌入(Word Embedding):如Word2Vec、GloVe,为单个词生成向量。
-
句嵌入(Sentence Embedding):如BERT、Sentence-BERT,为整句或段落生成向量。
-
多语言嵌入:如LASER、mBERT,支持跨语言语义对齐。
二、嵌入模型在本地知识库建设中的作用
本地知识库通常指企业或组织内部构建的结构化/半结构化数据仓库(如文档、FAQ、产品资料),嵌入模型是其实现智能化的核心技术之一,作用如下:
1. 知识库数据预处理
-
语义向量化:将知识库中的文档、段落、问答对转化为向量,构建向量数据库(如使用FAISS、Milvus存储)。
-
示例:
一篇技术文档 → 分割为段落 → 每个段落生成向量 → 存入向量库。
2. 语义搜索与检索
-
传统问题:关键词匹配无法处理同义词(如“笔记本” vs “笔记本电脑”)或语义泛化(如“如何开机” vs “启动设备的方法”)。
-
嵌入模型方案:
-
用户输入查询语句 → 转化为查询向量 → 与知识库向量比对(余弦相似度)→ 返回最相关结果。
-
优势:支持模糊语义匹配,提升搜索准确率。
-
3. 知识去重与聚类
-
去重:计算文档向量相似度,合并重复或高度相似内容(如不同版本的合同)。
-
聚类:将知识库内容按主题自动分组(如技术文档分类为“API指南”“故障排查”等)。
4. 问答系统与推荐
-
问答匹配:将用户问题与知识库问答对向量匹配,实现智能客服。
-
关联推荐:根据当前浏览内容推荐相关知识条目(如“阅读本产品文档的用户也查看了XXX”)。
5. 知识图谱补全
-
实体链接:将非结构化文本中的实体(如人名、产品名)链接到知识图谱中的节点。
-
关系推断:通过向量相似度推测实体间潜在关系。
三、本地知识库建设中嵌入模型的落地流程
1. 模型选型
-
需求场景:
-
中文场景:选BGE中文版、M3E、Ernie-3.0。
-
多语言场景:选mxbai-embed-large、E5。
-
轻量级部署:选all-MiniLM-L6-v2(仅80MB)。
-
-
开源 vs 商业API:
若数据敏感需本地化,选择开源模型(如Sentence Transformers);若追求效果且无隐私顾虑,可调用OpenAI/Cohere API。
2. 数据处理与向量化
-
数据清洗:去除噪声(HTML标签、乱码)、标准化文本格式。
-
分块策略:
-
短文本(QA对):直接整体向量化。
-
长文本(文档):按段落或滑动窗口分块(如每512 tokens一段)。
-
-
向量生成:调用嵌入模型批量处理文本,生成向量并存储。
3. 向量数据库构建
-
工具选择:
-
轻量级:FAISS(Facebook开源的向量检索库)。
-
分布式:Milvus、Elasticsearch(支持混合检索)。
-
-
优化技巧:
-
索引类型:HNSW(兼顾速度与精度)。
-
元数据关联:向量ID与原始文本路径绑定。
-
4. 检索与交互优化
-
混合搜索:结合向量相似度(语义)与BM25(关键词)加权得分。
-
重排序(Rerank):对初筛结果使用更精细的模型(如Cohere Rerank)二次排序。
-
反馈学习:记录用户点击数据,持续优化模型或检索策略。
四、挑战与解决方案
| 挑战 | 解决方案 |
|---|---|
| 长文本语义丢失 | 使用支持长上下文的模型(Jina Embeddings) |
| 多语言混合检索 | 采用多语言嵌入模型(mxbai-embed-large) |
| 高并发性能瓶颈 | 部署向量缓存层(Redis)或分布式检索 |
| 领域适配性差 | 微调嵌入模型(LoRA适配企业专有术语) |
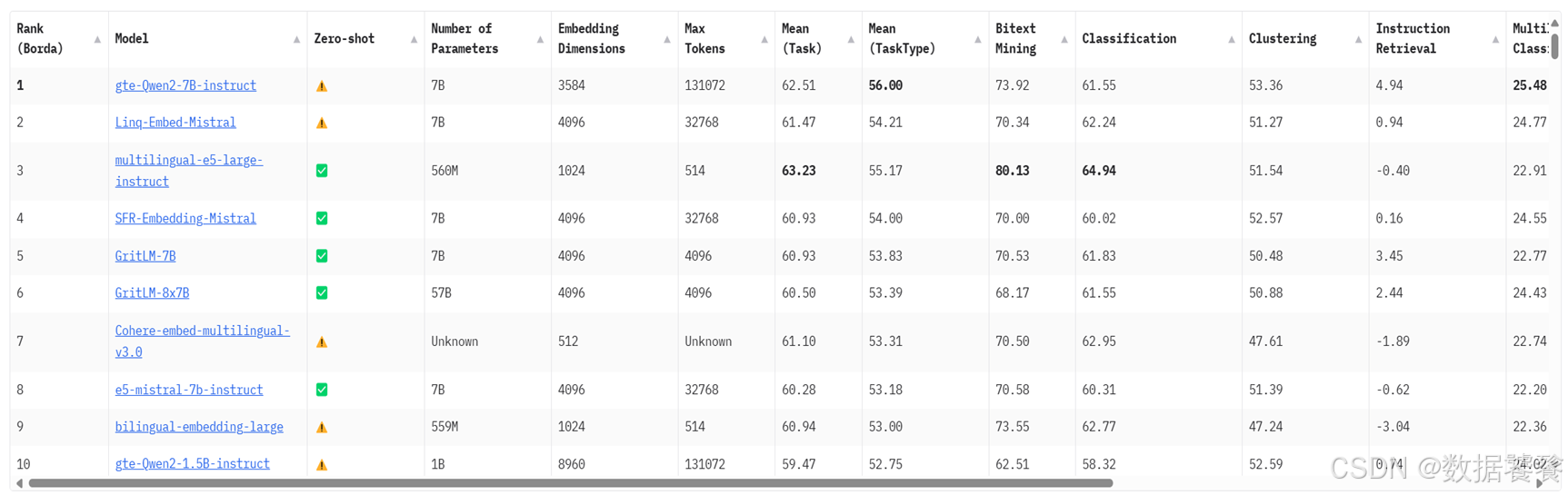
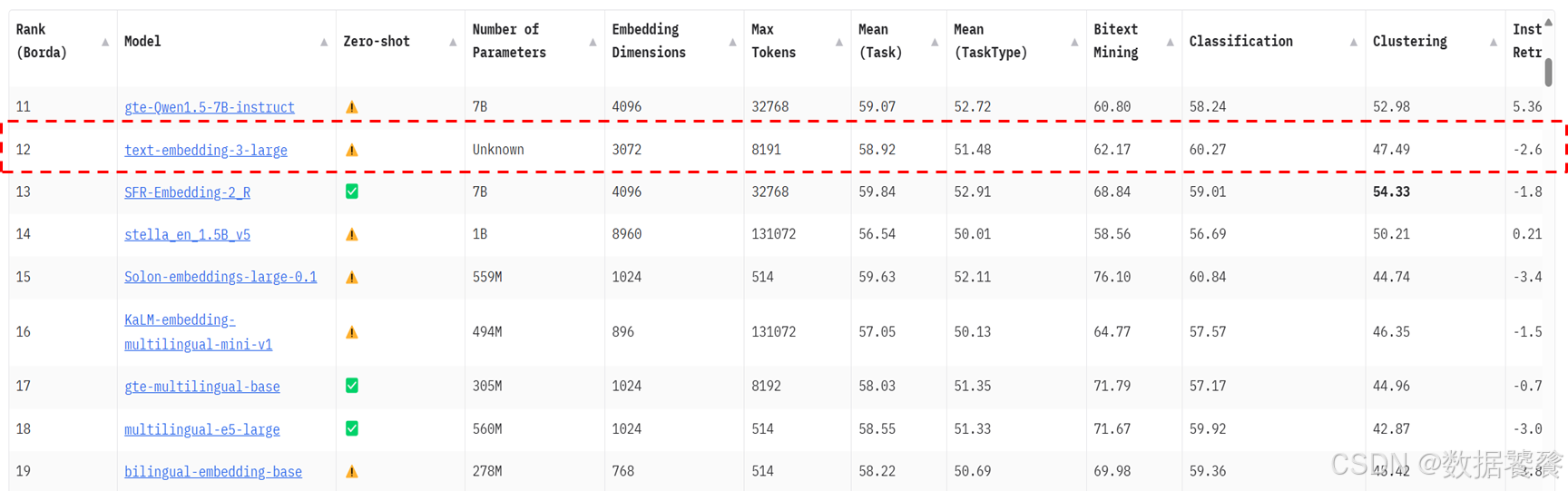
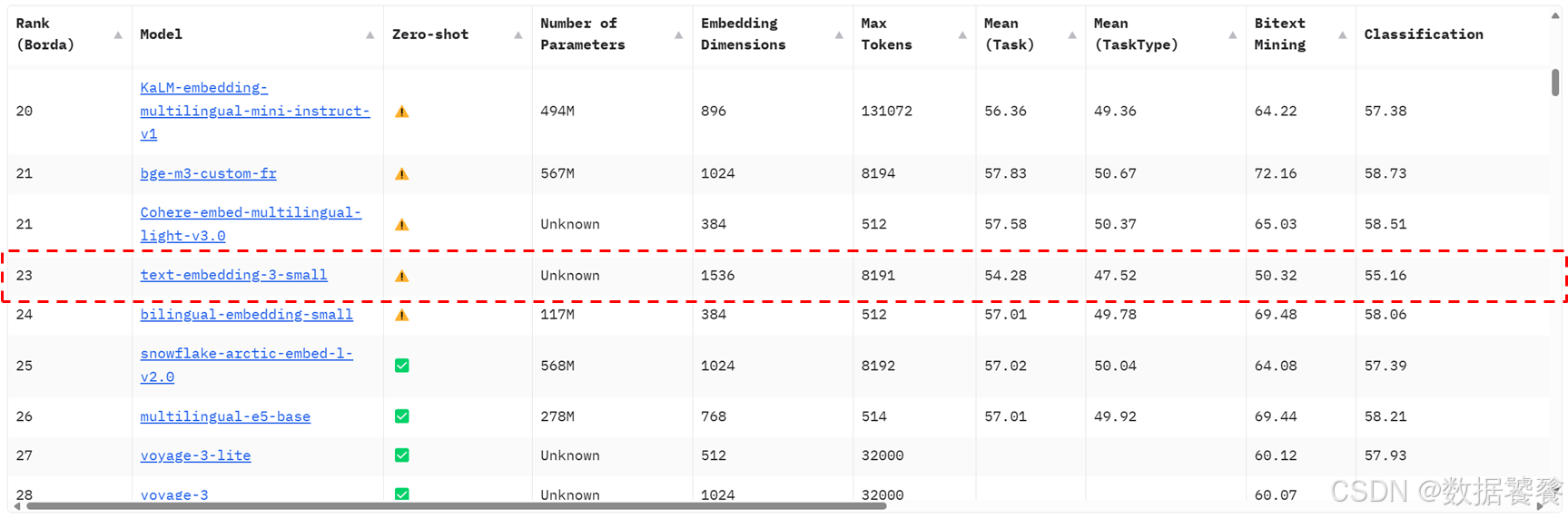
五、嵌入模型排行榜


















 3062
3062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











