






决策树的选取规则就是使得不纯度降低,或降低混乱程度的过程
信息熵的定义:
一个事件的信息量随着其发生概率儿减小,且不能为负
对于两个不相关的事件x,y。那么观察到两个事件同事发生获取的信息量等于观察各自发生得到的信息量。
h(x,y) = h(x) + h(y)
如果x,y是互不相关事件,那么满足p(x,y) = p(x) * p(y)
从上面的推到可以看出h(x),p(x)之间是对数关系。
因为获取到的信息不能为负,所以要加负号。底数只是遵循普通传统。
熵是对可能产生信息量的期望,所以有:
![]()
目前有三种算法
ID3算法—信息增益:
信息增益 = 花分前信息熵 - 划分后信息熵
C4.5算法—信息增益比(类似惩罚项):
信息增益比 = 信息增益 * 1/系数 * 。系数定义如下:
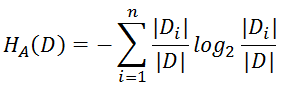
CART算法(分类树)—基尼系数:
基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
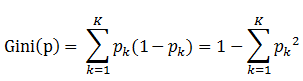















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









