







一、策略评价指标
设计了一个策略后,需要通过回测来评价其效果如何。常用的评价指标包括:
1.年化收益率
年化收益率是为了将不同策略的收益结果转换到同一个体系下,方便进行效果比较和评价。计算公式为:
年化收益率=(策略当前净值/策略初始净值)^(年交易日天数/回测期间总天数)-1
其中,年交易日天数是指A股市场一年的交易日天数。由于节假日的原因每年的天数是不同的,大概在230~250天之间,可以取平均值244。
给大家几个参考数据让大家要心里有个数:
(1)从1965年至2021年,巴菲特旗下的伯克希尔哈撒韦公司的年化收益率高达20.1%,而同期标普500指数的年化收益率10.5%。
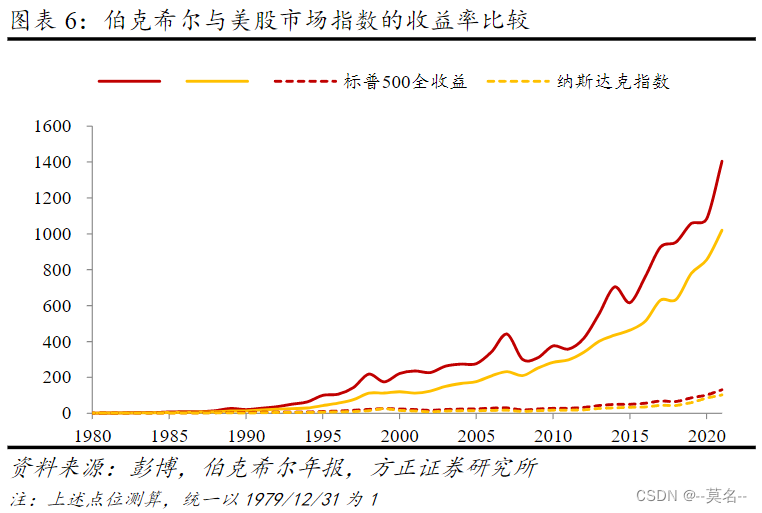
(2)大卫·西格尔在《股市长线法宝》一书中,对美国股市过去200多年的数据进行测算,扣除通货膨胀因素得到年化收益率是6.6%,如果不扣除通货膨胀因素的年化收益率是10%左右。
(3)上证指数从1990年12月19日到2021年6月24日,指数从100点涨到3566.65点,在约30.5年时间上涨了34倍多,年化收益率约12.43%。
(4)整个A股从开市到现在的年化收益率差不多也是10%左右。
以上数据均来自网上,有兴趣的朋友可以自己编程去算一下。如果你的策略跑出来的年化收益率动辄翻倍甚至几倍,好吧,你将赢得全世界!!!~~~做完梦记得好好检查下策略哪里写错了:)
2.最大回撤
最大回撤是指账户净值从上一个最高点到当前计算时间点的最大下跌幅度,在这些最大下跌幅度中取最小值(下跌幅度为负)作为最大回撤。用来描述策略可能出现的最糟糕情况,即衡量最极端情况下的亏损百分比。计算公式为:
最大回撤=min(账户当日净值 / 当日之前账户最高净值-1)。
注意,每当净值到达新的最高点时,回撤归零,需要更新计算公式中的账户最高净值。
如果一个策略的年化收益为30%,最大回撤是70%,那么你使用这个策略之前就要想想,是否能扛得住70%的下跌。打个比方,如果净值是1,下跌70%意味着后续净值要翻3.3倍才能回到1,能够让你深刻的体会到什么叫生不如死,这么坑的策略还是不要用了~~~~
3.贝塔值(beta)
根据资本资产定价理论(CAPM模型),beta系数衡量策略的回报率对市场变动的敏感程度,代表了该策略的结构性和系统性风险,表示策略与基准的相关性。简单点说就是策略的收益相对于业绩评价基准收益的总体波动性,或者叫做承担市场风险带来的投资收益。
计算公式为:
beta=策略日收益与基准日收益的协方差 / 基准日收益的方差。
比如策略采用的评价基准为沪深300指数,计算得到的beta如下:
beta=1说明策略和沪深300指数的收益变化一致。
beta=1.1说明沪深300指数上涨10%时,策略上涨11%;沪深300指数下跌10%时,策略下跌11%。
beta=0.9说沪深300指数上涨10%时,策略上涨9%;沪深300指数跌10%时,策略下跌9%。
那么现在问题来了,这个beta值到底怎么看好呢?不能一概而论。如果是牛市,个股、大盘上涨概率很大,应该选择beta值大的策略,从而获取高收益(这就是研报中常常提到的高beta系数策略);如果是熊市,大盘下跌可能性更大,就应该选择beta值小的策略,以降低回撤,确保资金的安全。
4.阿尔法值(alpha)
alpha值表示实际收益和平均预期收益的差额,衡量策略的非系统性风险。简单点说就是策略跑赢比较基准获得的超额收益大小。计算公式为:
alpha=(账户年化收益-无风险收益)-beta*(基准年化收益-无风险收益)
评价所设计的策略获得超额收益的能力大小。
5.账户收益波动率(Volatility)
账户收益波动率用来测量资产的风险性,波动越大代表策略风险越高。计算公式如下:
账户收益波动率=收益标准差*年交易日天数的平方根
6.夏普比率(Sharpe ratio)
夏普比率是一个可以同时对收益与风险加以综合考虑的经典指标,表示每承受一单位风险,会产生多少的超额回报。计算公式为:
夏普比率=(策略年化收益率-无风险利率)/ 策略收益波动率。
其中的无风险利率通常采用10年期国债年化收益率,可参考这个网站。
由于夏普比率代表单位风险所获得的超额回报率。该比率越高,策略承担单位风险得到的超额回报率越高,所以说夏普比率是越高越好。需要注意的是,夏普比率没有基准点,因此其绝对大小本身没有意义,只有在与其他策略的比较中才有价值。
7.最大连续上涨和下跌天数、最大连续盈利和亏损笔数、单笔最大盈利和亏损、单笔持仓最长和最短时间
最大连续下跌天数:衡量策略连续亏损的最大天数。
最大连续亏损笔数:衡量策略连续亏损的最大次数,或者说策略连续失效的次数。
单笔最大亏损:单笔交易造成的最大损失。
这些指标都是对交易中最极端的情况的描述,投资者需要对交易中可能出现的极端情况有心理准备,否则会导致策略无法正常执行。单笔最大亏损、单笔持仓最长时间,或者最大连续亏损笔数这些指标在实盘中很重要,若亏损过大或者连续失败的次数过多,会打击投资者的信心,出现人为干预甚至终止策略运行。因此,如果策略跑出来的这些指标远远超出了你的承受范围,那就应该考虑改变参数。
二、计算实例
1.年化收益率
计算年化收益率需要资金净值数据df['capital']。
rng = pd.period_range(df['date'].iloc[0], df['date'].iloc[-1], freq='D') # 创建时间范围,用于计算回测天数
capital_annual = (df['capital'].iloc[-1] / df['capital'].iloc[0]) ** (trade_day / len(rng)) – 1这里需要需要注意几点:
(1)计算年化收益需要知道回测区间的时间长度,一般以天计算。这里使用period_range()来建立回测日期的时间序列,这样就可以用len()来获得回测的实际天数。你可能会奇怪为啥不用len(dft),实际上股票提供的交易数据是交易日的时间序列,不是回测区间的实际天数。如果用这个来计算年化收益率会得到很高的数值,大家可以试一下~~~
(2)iloc[-1]指的是时间序列的最后一个数据,iloc[0]指的是第一个数据。注意时间序列数据需要按照'date'列来排序,否则可能会取到错误数据。
2.最大回撤
最大回撤需要资金净值数据df['capital'],然后使用DataFrame的cummax()函数很方便的计算,美中不足的是无法同时记录出现时间。
df = pd.DataFrame({'date': date_list, 'capital': capital_list})
previos_max = df['capital'].cummax() # 计算上一个最高点
drawdowns = (df['capital'] - previos_max) / previos_max # 计算回撤
tt = drawdowns.min() # 找出最大回撤3.贝塔值(beta)
贝塔值计算需要资金收益数据df['capital_rtn']、参考基准收益数据dft['index_rtn']。
b = dft['capital_rtn'].cov(dft['index_rtn']) / dft['index_rtn'].var()4.阿尔法值(alpha)
阿尔法值计算需要资金净值数据df['capital']、资金收益数据df['capital_rtn']、参考基准净值数据dft['index']、参考基准收益数据dft['index_rtn']。其中无风险利率采用的是10年期国债的到期年化收益率。
rng = pd.period_range(dft['date'].iloc[0], dft['date'].iloc[-1], freq='D') # 创建时间范围,用于计算回测天数
rf = 0.0269 # 无风险利率取10年期国债的到期年化收益率(2022-9-16)
annual_stock = (dft['capital'].iloc[-1] / dft['capital'].iloc[0]) ** (trade_day / len(rng)) - 1 # 账户年化收益
annual_index = (dft['index'].iloc[-1] / dft['index'].iloc[0]) ** (trade_day / len(rng)) - 1 # 基准年化收益
beta = dft['capital_rtn'].cov(dft['index_rtn']) / dft['index_rtn'].var() # 计算beta值
a = (annual_stock - rf) - beta * (annual_index - rf) # 计算alpha值5.账户收益波动率(Volatility)
账户收益波动率是根据资金收益数据df['capital_rtn']的标准差来计算,其中trade_day为每年的交易日天数,本文中取平均值244天。
volatility = dft['capital_rtn'].std() * sqrt(trade_day)6.夏普比率(Sharpe ratio)
夏普比率计算需要资金净值数据df['capital']、资金收益数据df['capital_rtn']。
rf = 0.0269 # 无风险利率取10年期国债的到期年化收益率(2022-9-16)
annual_stock = (dft['capital'].iloc[-1] / dft['capital'].iloc[0]) ** (trade_day / len(rng)) - 1 # 账户年化收益
sharpe = (annual_stock - rf) / volatility # 计算夏普比率7.最大连续上涨和下跌天数、最大连续盈利和亏损笔数、单笔最大盈利和亏损、单笔持仓最长和最短时间
这几个指标需要根据具体的交易记录数据来统计,这里不详细说明,请参考后续的实例。
三、回测计算实例
下面以为一个简单的双均线策略回测为例来演示以上指标的计算。双均线策略就是两根均线:短期均线和长期均线,买卖点确定方式如下:
(1)短线均线上穿长期均线(金叉)时买入。
(2)短期均线下穿长期均线(死叉)时卖出。
代码如下图所示:
import matplotlib.pyplot as plt
import pandas as pd
import akshare as ak
from math import sqrt
import warnings
warnings.filterwarnings("ignore")
# 计算双均线策略并得到买卖信号和仓位
def simple_ma(stock_data, sn=5, ln=60):
stock_data['short'] = stock_data.close.rolling(sn).mean()
stock_data['long'] = stock_data.close.rolling(ln).mean()
stock_data['MA60'] = stock_data.close.rolling(60).mean()
stock_data.loc[(stock_data['short'] > stock_data['long']) & (
stock_data['short'].shift(1) <= stock_data['long'].shift(1)), 'OP_SIG'] = 1 # 买入
stock_data.loc[(stock_data['short'] < stock_data['long']) & (
stock_data['short'].shift(1) >= stock_data['long'].shift(1)), 'OP_SIG'] = 2 # 卖出
stock_data.index = range(len(stock_data))
stock_data['position'] = 0
old_position = 0
i = 0
while i < len(stock_data):
if stock_data.loc[i, 'OP_SIG'] == 1: # 买入
# print(i,stock_data.loc[i, 'position'])
if stock_data.loc[i, 'position'] == 0:
stock_data.loc[i + 1, 'position'] = 1000
old_position = 1000
i = i + 2
else:
stock_data.loc[i, 'position'] = old_position
i = i + 1
elif stock_data.loc[i, 'OP_SIG'] == 2: # 卖出
# print(i,stock_data.loc[i, 'position'],oldPosition)
stock_data.loc[i, 'position'] = old_position
if stock_data.loc[i, 'position'] > 0:
stock_data.loc[i + 1, 'position'] = 0
old_position = 0
i = i + 2
else:
stock_data.loc[i, 'position'] = old_position
i = i + 1
else:
stock_data.loc[i, 'position'] = old_position
i = i + 1
# stock_data.loc[stock_data['OP_SIG']==1,'position'].shift(-1)=1000
# stock_data.loc[stock_data['OP_SIG']==2,'position'].shift(-1)=0
return stock_data
# 计算最大回撤
def max_drawdown(date_list, capital_list):
df = pd.DataFrame({'date': date_list, 'capital': capital_list})
df['max2here'] = df['capital'].expanding().max() # 计算当日之前的账户最大价值
df['dd2here'] = df['capital'] / df['max2here'] - 1 # 计算当日的回撤
# 计算最大回撤和结束时间
temp = df.sort_values(by='dd2here').iloc[0][['date', 'dd2here']]
max_dd = temp['dd2here']
end_date = temp['date']
# 计算开始时间
df = df[df['date'] <= end_date]
start_date = df.sort_values(by='capital', ascending=False).iloc[0]['date']
# df.to_excel("dropdown.xlsx", sheet_name='capital', index=False)
# print('最大回撤为:%f,开始日期:%s,结束日期:%s' % (max_dd, start_date, end_date))
return max_dd, start_date, end_date
def drawdown(date_list, capital_list): # 计算最大回撤,但无法记录出现日期
df = pd.DataFrame({'date': date_list, 'capital': capital_list})
# df['capital'] = (1 + df['capital_rtn']).cumprod() # 计算净值
previos_max = df['capital'].cummax() # 计算上一个最高点
drawdowns = (df['capital'] - previos_max) / previos_max # 计算回撤
tt = drawdowns.min() # 找出最大回撤
return tt
# ====读取股票数据
code = '600036'
data = ak.stock_zh_a_hist(symbol=code, start_date='19940101', end_date='20220916', adjust="hfq")#.iloc[:, :6]
data.to_excel(code + '.xlsx', sheet_name=code, index=False)
# df = pd.read_excel(code+'.xlsx', sheet_name=code)
# 列名改为英文方便下面操作
data.columns = ['date', 'open', 'close', 'high', 'low', 'volume', 'money', 'amp', 'change', 'chg', 'turnover']
data.index = pd.to_datetime(data.date)
data.index = data.index.strftime('%Y%m%d')
data = data.sort_index()
data['ret'] = data['close'].pct_change() # 计算涨跌幅=change
# ====设置回测参数
trade_day = 244 # 每年平均交易日天数
n_short = 10 # 双均线短周期
n_long = 30 # 双均线长周期
s_date = '20100101' # 回测开始日期
slippage_rate = 0.1 / 1000 # 滑点率
commis_rate = 0.2 / 1000 # 交易费率
# ====根据策略,计算仓位,资金曲线等
# 计算买卖信号
start_date=pd.to_datetime(s_date)
df = data[data['date'] >= start_date.strftime('%Y-%m-%d')] # 从指定时间开始
df = simple_ma(df, n_short, n_long)
# 计算测量每天涨幅
df['capital_rtn'] = 0
# 买入时,计算当天资金曲线涨幅capital_rtn=今天开盘新买入的position在今天的涨幅(扣除手续费)
df.loc[df['position'] > df['position'].shift(1), 'capital_rtn'] = \
(df['close'] / df['open'] - 1) * (1 - slippage_rate - commis_rate)
# 卖出时,计算当天资金曲线涨幅capital_rtn=今天开盘卖出的position在今天的涨幅(扣除手续费)
df.loc[df['position'] < df['position'].shift(1), 'capital_rtn'] = \
(df['open'] / df['close'].shift(1) - 1) * (1 - slippage_rate - commis_rate)
# 仓位不变时,当天的capital_rtn=当天的涨幅change
cond1 = df['position'] == df['position'].shift(1)
cond2 = df['position'] > 0
df.loc[cond1 & cond2, 'capital_rtn'] = df['change']
# 注意:capital_rtn值的单位为 %,计算累积收益需要转换为小数
df['capital_rtn'] = df['capital_rtn'] / 100
df['change'] = df['change'] / 100
df['capital'] = (df['capital_rtn'] + 1).cumprod() # 计算累积收益率
df['stock'] = (df['change'] + 1).cumprod() # 计算累积收益率
# ====根据策略结果,计算评价指标
# 计算股票和策略年收益
dft = df[['date', 'change', 'capital_rtn']]
dft['date'] = pd.to_datetime(dft['date']) # 将str类型改为时间戳格式
# 计算每一年股票、资金曲线的收益
year_rtn = dft.set_index('date')[['change', 'capital_rtn']].resample('A').apply(lambda x: (x + 1.0).prod() - 1.0)
year_rtn.dropna(inplace=True)
# 计算策略和股票的年胜率
yearly_win_rate = len(year_rtn[year_rtn['capital_rtn'] > 0]) / len(year_rtn[year_rtn['capital_rtn'] != 0])
yearly_win_rates = len(year_rtn[year_rtn['change'] > 0]) / len(year_rtn[year_rtn['change'] != 0])
date_list = list(df['date'])
capital_list = list(df['capital'])
index_list = list(df['close'])
dft = pd.DataFrame({'date': date_list, 'capital': capital_list, 'close': index_list})
dft.sort_values(by='date', inplace=True)
dft.reset_index(drop=True, inplace=True)
rng = pd.period_range(dft['date'].iloc[0], dft['date'].iloc[-1], freq='D') # 创建时间范围,用于计算回测天数
capital_cum = dft['capital'].iloc[-1] / dft['capital'].iloc[0]
stock_cum = dft['close'].iloc[-1] / dft['close'].iloc[0]
capital_annual = (dft['capital'].iloc[-1] / dft['capital'].iloc[0]) ** (trade_day / len(rng)) - 1
stock_annual = (dft['close'].iloc[-1] / dft['close'].iloc[0]) ** (trade_day / len(rng)) - 1
capital_drawdown = max_drawdown(date_list, capital_list)
stock_drawdown = max_drawdown(date_list, index_list)
tt = drawdown(date_list, capital_list)
print('策略累积收益:%f 股票累积收益:%f' % (capital_cum, stock_cum))
print('策略年化收益:%f 股票年化收益:%f' % (capital_annual, stock_annual))
print('策略年胜率:%f 股票年胜率:%f' % (yearly_win_rate, yearly_win_rates))
print('策略最大回撤:%f,开始日期:%s,结束日期:%s' % capital_drawdown)
print('股票最大回撤:%f,开始日期:%s,结束日期:%s' % stock_drawdown)
# 将数据序列合并为一个datafame并按日期排序
capitalrtn_list = list(df['capital_rtn'])
indexrtn_list = list(df['change'])
dft = pd.DataFrame({'date': date_list, 'capital': capital_list, 'index': index_list, 'capital_rtn': capitalrtn_list,
'index_rtn': indexrtn_list})
dft.sort_values(by='date', inplace=True)
dft.reset_index(drop=True, inplace=True)
volatility = dft['capital_rtn'].std() * sqrt(trade_day) # 计算收益波动率
b = dft['capital_rtn'].cov(dft['index_rtn']) / dft['index_rtn'].var() # 计算beta值
rng = pd.period_range(dft['date'].iloc[0], dft['date'].iloc[-1], freq='D') # 创建时间范围,用于计算回测天数
# print(len(rng),len(df))
rf = 0.0269 # 无风险利率取10年期国债的到期年化收益率(2022-9-16)
annual_stock = (dft['capital'].iloc[-1] / dft['capital'].iloc[0]) ** (trade_day / len(rng)) - 1 # 账户年化收益
annual_index = (dft['index'].iloc[-1] / dft['index'].iloc[0]) ** (trade_day / len(rng)) - 1 # 基准年化收益
beta = dft['capital_rtn'].cov(dft['index_rtn']) / dft['index_rtn'].var() # 计算beta值
a = (annual_stock - rf) - beta * (annual_index - rf) # 计算alpha值
sharpe = (annual_stock - rf) / volatility # 计算夏普比率
dft['diff'] = dft['capital_rtn'] - dft['index_rtn']
annual_mean = dft['diff'].mean() * trade_day
annual_std = dft['diff'].std() * sqrt(trade_day)
info = annual_mean / annual_std # 计算信息比率
print('收益波动率:%f' % volatility)
print('阿尔法:%f 贝塔:%f 夏普比率:%f 信息比率:%f' % (a, b, sharpe, info))
# ====根据每次买卖的结果,计算相关指标
# 记录买入或者加仓时的日期和初始资产
df.loc[df['position'] > df['position'].shift(1), 'start_date'] = df['date']
df.loc[df['position'] > df['position'].shift(1), 'start_capital'] = df['capital'].shift(1)
df.loc[df['position'] > df['position'].shift(1), 'start_stock'] = df['close'].shift(1)
# 记录卖出时的日期和当天的资产
df.loc[df['position'] < df['position'].shift(1), 'end_date'] = df['date']
df.loc[df['position'] < df['position'].shift(1), 'end_capital'] = df['capital']
df.loc[df['position'] < df['position'].shift(1), 'end_stock'] = df['close']
# df.to_excel("tt.xlsx", sheet_name='trade', index=False)
# 将买卖当天的信息合并成一个DataFrame
df_temp = df[df['start_date'].notnull() | df['end_date'].notnull()]
df_temp['end_date'] = df_temp['end_date'].shift(-1)
df_temp['end_capital'] = df_temp['end_capital'].shift(-1)
df_temp['end_stock'] = df_temp['end_stock'].shift(-1)
# 构建账户交易情况DataFrame:'hold_time'持有天数,'trade_return'该次交易盈亏,'stock_return'同期股票涨跌幅
trade = df_temp.loc[df_temp['end_date'].notnull(),
['start_date', 'start_capital', 'start_stock', 'end_date', 'end_capital', 'end_stock']]
trade.reset_index(drop=True, inplace=True)
trade['start_date'] = pd.to_datetime(trade['start_date']).dt.date
trade['end_date'] = pd.to_datetime(trade['end_date']).dt.date
trade['hold_time'] = (trade['end_date'] - trade['start_date'])
trade['trade_return'] = trade['end_capital'] / trade['start_capital'] - 1
trade['stock_return'] = trade['end_stock'] / trade['start_stock'] - 1
trade_num = len(trade) # 交易次数
max_holdtime = trade['hold_time'].max().days # 最长持有天数
average_change = trade['trade_return'].mean() # 每次平均涨幅
max_gain = trade['trade_return'].max() # 单笔最大盈利
max_loss = trade['trade_return'].min() # 单笔最大亏损
total_years = (trade['end_date'].iloc[-1] - trade['start_date'].iloc[0]).days / 365
trade_per_year = trade_num / total_years # 年均买卖次数
# 计算连续盈利亏损次数
trade.loc[trade['trade_return'] > 0, 'gain'] = 1
trade.loc[trade['trade_return'] < 0, 'gain'] = 0
trade['gain'].fillna(method='ffill', inplace=True)
# trade.to_excel("trade.xlsx", sheet_name='trade', index=False)
# 计算连续盈利亏损的次数
rtn_list = list(trade['gain'])
gain_list = []
num = 1
for i in range(len(rtn_list)):
if i == 0:
gain_list.append(num)
else:
if (rtn_list[i] == rtn_list[i - 1] == 1) or (rtn_list[i] == rtn_list[i - 1] == 0):
num += 1
else:
num = 1
gain_list.append(num)
trade['successive_gain'] = gain_list
# 获取盈利和亏损最大次数
max_successive_gain = \
trade[trade['gain'] == 1].sort_values(by='successive_gain', ascending=False)['successive_gain'].iloc[0]
max_successive_loss = \
trade[trade['gain'] == 0].sort_values(by='successive_gain', ascending=False)['successive_gain'].iloc[0]
# 输出账户交易各项指标
print('\n==============账户交易的各项指标================')
print('交易次数:%d 最长持有天数:%d' % (trade_num, max_holdtime))
print('每次平均涨幅:%f' % average_change)
print('单次最大盈利:%f 单次最大亏损为:%f' % (max_gain, max_loss))
print('年均买卖次数:%f' % trade_per_year)
print('最大连续盈利次数:%d 最大连续亏损次数:%d' % (max_successive_gain, max_successive_loss))
# df.to_excel("test.xlsx", sheet_name='600036', index=False)
# 绘图显示结果
plt.plot(df['date'], df['stock'], label='600036')
plt.plot(df['date'], df['capital'], label='双均线策略')
plt.ylabel("y轴", fontproperties="SimSun")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("双均线策略回测")
plt.legend(loc='best')
plt.show()双均线策略的参数设置如下图所示:

收益曲线如下图所示:

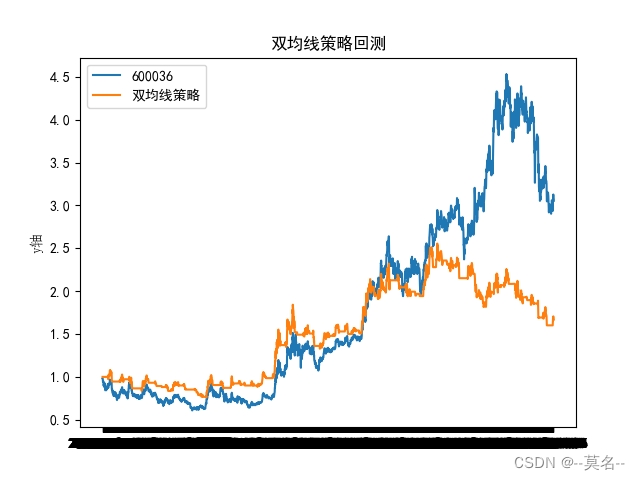
这里采用的是招商银行600036的后复权日K线数据,回测起始时间是2010年1月1日,结束时间是2022年9月16日。从图中可以看出10-30日双均线策略的效果相当差,策略的胜率较低,年化收益率也只有2.7%,还不如买了一直持股不动的收益高。
本文中为了省事直接用招商银行同期的涨跌幅度作为对比基准,也可以采用沪深300指数或其它指数作为基准对比,来看下策略与大盘的相关情况。
因为这里只是为了举例说明如何计算策略评价指标,大家就不要纠结策略效果如何了,有兴趣的可以根据评价指标的结果去对策略进行优化。
-----------------------------------
原创不易,请多支持!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









