









1. Learning Distinct and Representative Modes for Image Captioning
- 2022 NeurIPS
- image captioning:给定图像生成自然描述
即一张图片可以生成多个caption,希望这样可以从不同的角度去描述图片中的内容。
1.1 当前存在的问题
- 现有工作生成的image captions偏向于
"average" catpion,专注于常见单词、短语,导致找特别通用的方式来生成image captions,会在diversity方面受到限制,(即mode collapse问题)。

其实本身这种train-test就存在问题,train阶段一张图片学习多个文本,但是在test阶段生成一条文本。
- 对于现有的 controllable image captioning 方法,常常是用隐式的控制信号,比如 CVAE-based or GAN-based models. 这种隐式控制的方式不具有可解释性。另外也有一些显式控制信号的工作,比如控制情感,句子长度等。但是这些显示的控制信号一般很难收集。
1.2 本文
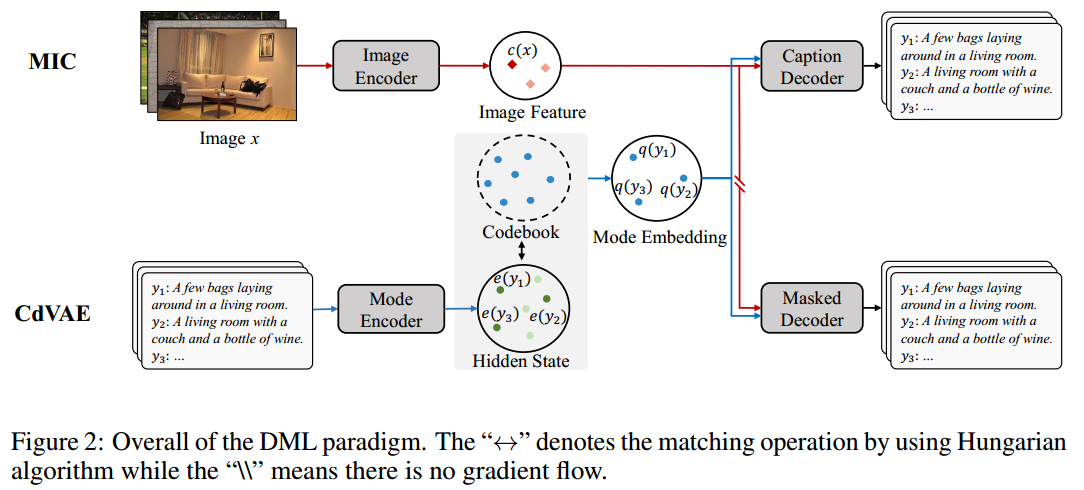
探索training captions语料库中的丰富模式,学习一组“模式嵌入”,并进一步使用“模式嵌入”来控制现有image captions models生成captions的模式。设计了一个Discrete Model Learning(DML)双塔结构
- image-conditioned discrete variational autoencoder (CdVAE):将每个image caption 映射到存储在学习codebook中的一个模式嵌入,并使用纯非自回归生成目标进行训练,使模式不同且具有代表性
- mode Encoder E m \mathcal{E}_m Em
- masked Decoder D m \mathcal{D}_m Dm
- mode-conditioned image captioning (MIC) :从现有的image captioning model简单地修改,其中模式嵌入被添加到原始单词嵌入作为控制信号
- image Encoder E c \mathcal{E}_c Ec
- caption Decoder D c \mathcal{D}_c Dc
- Codebook
Ω
∈
R
k
×
d
\Omega \in \mathbb{R}^{k \times d}
Ω∈Rk×d:包含一系列通过DML范式学习的模式嵌入
- k k k是一个超参数,表示多少种模式
训练损失:
−
log
p
(
y
i
∣
q
(
y
i
)
,
x
)
+
∥
sg
[
e
(
y
i
)
]
−
q
(
y
i
)
∥
2
2
+
β
∥
e
(
y
i
)
−
sg
[
q
(
y
i
)
]
∥
2
2
-\log p\left(y_{i} \mid q\left(y_{i}\right), x\right)+\left\|\operatorname{sg}\left[e\left(y_{i}\right)\right]-q\left(y_{i}\right)\right\|_{2}^{2}+\beta\left\|e\left(y_{i}\right)-\operatorname{sg}\left[q\left(y_{i}\right)\right]\right\|_{2}^{2}
−logp(yi∣q(yi),x)+∥sg[e(yi)]−q(yi)∥22+β∥e(yi)−sg[q(yi)]∥22
1.3 准备知识
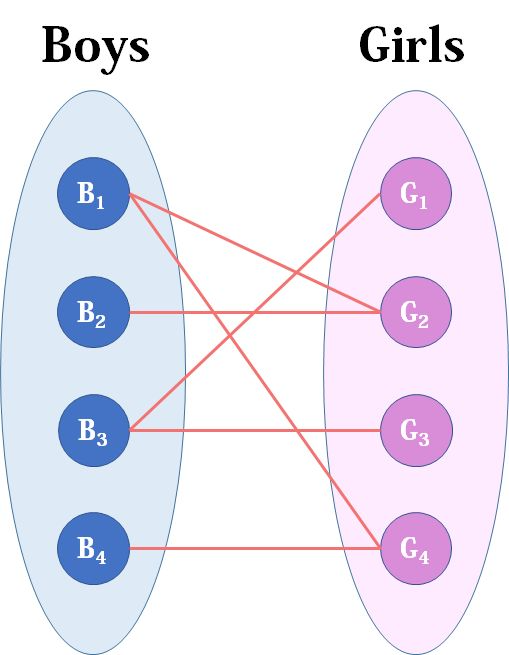
匈牙利算法:解决一些与二分图匹配有关的问题
- 最大匹配问题:(例如下图,红娘匹配)
- 最小点覆盖问题:我们想找到最少的一些点,使二分图所有的边都至少有一个端点在这些点之中。倒过来说就是,删除包含这些点的边,可以删掉所有边。
VQ-VAE:
log
p
(
x
)
−
D
K
L
[
q
(
z
∣
x
)
,
p
(
z
∣
x
)
]
=
E
q
(
z
∣
x
)
[
log
p
(
x
∣
z
)
]
−
D
K
L
[
q
(
z
∣
x
)
,
p
(
z
)
]
log
p
θ
(
x
∣
c
)
≥
E
q
ϕ
(
z
∣
x
,
c
)
[
log
p
θ
(
x
∣
z
,
c
)
]
−
D
K
L
[
q
ϕ
(
z
∣
x
,
c
)
,
p
(
z
∣
c
)
]
\begin{array}{c} \log p(x)-D_{\mathrm{KL}}[q(z \mid x), p(z \mid x)]=\mathbb{E}_{q(z \mid x)}[\log p(x \mid z)]-D_{\mathrm{KL}}[q(z \mid x), p(z)] \\ \log p_{\theta}(x \mid c) \geq \mathbb{E}_{q_{\phi}(z \mid x, c)}\left[\log p_{\theta}(x \mid z, c)\right]-D_{\mathrm{KL}}\left[q_{\phi}(z \mid x, c), p(z \mid c)\right] \end{array}
logp(x)−DKL[q(z∣x),p(z∣x)]=Eq(z∣x)[logp(x∣z)]−DKL[q(z∣x),p(z)]logpθ(x∣c)≥Eqϕ(z∣x,c)[logpθ(x∣z,c)]−DKL[qϕ(z∣x,c),p(z∣c)]
2. MultiViz: Towards Visualizing and Understanding Multimodal Models
2.1 当前工作的问题
现代多模态模型通常是黑箱神经网络,这使得理解其内部机制具有挑战性。
- multimodal transformers
- pretrained models
2.2 本文
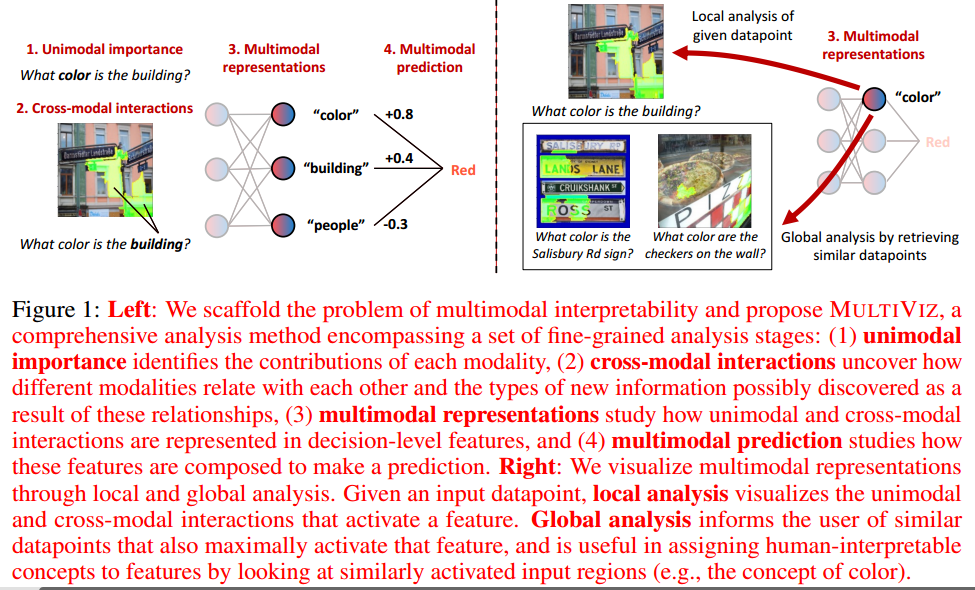
可解释性问题分为4个阶段来分析多模态模型行为的方法:
- unimodal importance:每个模态如何有助于下游建模和预测
- 目的:了解每种模态对建模和预测的贡献
- 单模态特征贡献方法 UNI ( f θ , y , x ) \text{UNI}\left(f_{\theta}, y, \mathbf{x}\right) UNI(fθ,y,x)
- 返回模态 x \mathbf{x} x的原子 x x x的重要性权重。
- cross-modal interactions:不同模态之间的相互关系
- 定义1:(统计非加性相互作用)。函数 f f f学习2个unimodal原子 x 1 x_1 x1和 x 2 x_2 x2之间的特征相互作用 I \mathcal{I} I,当且仅当 f f f不能分解为unimodal函数 g 1 g_1 g1, g 2 g_2 g2的和,使得 f ( x 1 , x 2 ) = g 1 ( x 1 ) + g 2 ( x 2 ) f(x_1,x_2)=g_1(x_1)+g_2(x_2) f(x1,x2)=g1(x1)+g2(x2)
- 定义2:(统计非加性相互作用的梯度定义)。如果 E x 1 , x 2 [ ∂ 2 f ( x 1 , x 2 ) ∂ x 1 ∂ x 2 ] 2 > 0 \mathbf{E}_{x_{1}, x_{2}}\left[\frac{\partial^{2} f\left(x_{1}, x_{2}\right)}{\partial x_{1} \partial x_{2}}\right]^{2}>0 Ex1,x2[∂x1∂x2∂2f(x1,x2)]2>0,则函数 f f f在2个unimodal原子 x 1 x_1 x1和 x 2 x_2 x2之间表现出非加性相互作用
- 对多种模态求二阶导数,若为0则为不存在相互关系,若>0则存在相互关系

- multimodal representations:在决策层如何表示单模态和跨模态交互特征
- 给定训练的多模态模型 f f f,将矩阵 M z ∈ R N × d M_{z} \in \mathbb{R}^{N \times d} Mz∈RN×d定义为 f f f的倒数第二层,矩阵 M M M展示了隐含地包含来自unimodal和cross-modal交互的信息的深度特征表示。对于第 i i i个数据点, z = M z ( i ) z=M_z(i) z=Mz(i)收集一组单独的特征表示 z 1 , z 2 , ⋯ , z d ∈ R z_1, z_2,\cdots, z_d \in R z1,z2,⋯,zd∈R。目标是通过局部和全局分析来解释这些特征表示(参见图1(右)的示例)
- Local representation analysis R ℓ R_{\ell} Rℓ:通知用户激活特征 z j z_j zj的原始数据点的部分。
- Global representation analysis R g R_g Rg:向用户提供前 k k k个数据点 D k ( z j ) = { ( x 1 , x 2 , y ) i = 1 k } \mathcal{D}_k(z_j) = \{ (\mathbf{x}_1, \mathbf{x}_2, y )_{i=1}^k \} Dk(zj)={(x1,x2,y)i=1k},其也最大程度地激活特征 z j z_j zj
- multimodal prediction:决策级特征如何组合来进行预测
- 将稀疏线性预测模型与神经网络特征相结合,用倒数第二层特征的线性组合来近似预测过程
- 多模态数据集: D = { ( x 1 , x 2 , y ) i = 1 n } = { ( x 1 ( 1 ) , x 1 ( 2 ) , … , x 2 ( 1 ) , x 2 ( 2 ) , … , y ) i = 1 n } \mathcal{D}=\left\{\left(\mathbf{x}_{1}, \mathbf{x}_{2}, y\right)_{i=1}^{n}\right\}=\left\{\left(x_{1}^{(1)}, x_{1}^{(2)}, \ldots, x_{2}^{(1)}, x_{2}^{(2)}, \ldots, y\right)_{i=1}^{n}\right\} D={(x1,x2,y)i=1n}={(x1(1),x1(2),…,x2(1),x2(2),…,y)i=1n}
- 多模态目标: y ^ = f ( x 1 , x 2 ; θ ) \hat{y}=f\left(\mathbf{x}_{1}, \mathbf{x}_{2} ; \theta\right) y^=f(x1,x2;θ)
3. Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
本文工作:为图像生成段落caption

3.1 准备知识
**zero-shot learning:**指的是一种特定类型的任务:在一组数据上训练一个分类器,然后让分类器预测另一组没见过的、不同源的数据。但是尤其在NLP领域,它是广义上的让模型执行它没学习过的任务。GPT-2论文[1]就是一个例子,论文中作者在一些没有直接微调过的下游任务(比如机器翻译)中评估语言模型。ZSL有各种方式的应用十分重要,我们也应该在比较不同的方法时注意理解它们的实验条件。举个例子,传统的零样本学习为了让模型能够预测没有训练数据的类别,需要为没见过的类别提供某种描述信息(descriptor)[2](比如一组视觉属性或者简单的类名)。所以交流各种方法的时候,我们需要了解,不同的ZSL会采用不同的规则来定义哪些类别描述信息来表示上下文。
[1]GPT-2:https://pdfs.semanticscholar.org/9405/cc0d6169988371b2755e573cc28650d14dfe.pdf
[2]《An embarrassingly simple approach to zero-shot learning》http://proceedings.mlr.press/v37/romera-paredes15.pdf
3.2 当前工作的问题
以object为中心的工作仍然是最终task或application的代理,这些task或application需要对视觉内容的整体视图,涉及对象之外的概念:动作、属性和关系等等
3.3 本文
visual clues:使用视觉基础模型将图像的丰富语义表示(如image tags, object attributes/locations, captions)构建为结构化文本提示
contribution
- 提出了一个语义视觉表示的通用framework,并展示了它在图像段落captioning中的应用。该框架简单但高度可扩展,允许新组件成为插件,并支持其他需要视觉内容整体视图的使用场景。
- 提出的模型的有效性基于其表示视觉概念(例如,场景图)的能力,并设置新的最先进的结果。

- 通用framework分为三个阶段:
- 用包含丰富视觉信息的visual clues S S S表示 image I I I
- 将visual clues feed到语言模型中以生成K个候选段落 { T i } i = 1 K \{T_i\}_{i=1}^K {Ti}i=1K
- 从候选段落 { T i } i = 1 K \{T_i\}_{i=1}^K {Ti}i=1K中选择最佳段落 T ∗ T^* T∗
3.3.1 visual clues 抽取
- Concise tags:使用经过对比训练的视觉语言模型,例如CLIP、Florence
- L = − 1 ∣ B ∣ ∑ x i , y i ∈ B ( exp ( ⟨ f v ( x i ) , f t ( y i ) ⟩ / τ ) ∑ y j ∈ B , j ≠ i exp ( ⟨ f v ( x i ) , f t ( y j ) ⟩ / τ ) + exp ( ⟨ f v ( x i ) , f t ( y i ) ⟩ / τ ) ∑ x j ∈ B , j ≠ i exp ( ⟨ f v ( x j ) , f t ( y i ) ⟩ / τ ) ) \mathcal{L}=-\frac{1}{|\mathcal{B}|} \sum_{x_{i}, y_{i} \in \mathcal{B}}\left(\frac{\exp \left(\left\langle f_{\mathrm{v}}\left(x_{i}\right), f_{\mathrm{t}}\left(y_{i}\right)\right\rangle / \tau\right)}{\sum_{y_{j} \in \mathcal{B}, j \neq i} \exp \left(\left\langle f_{\mathrm{v}}\left(x_{i}\right), f_{\mathrm{t}}\left(y_{j}\right)\right\rangle / \tau\right)}+\frac{\exp \left(\left\langle f_{\mathrm{v}}\left(x_{i}\right), f_{\mathrm{t}}\left(y_{i}\right)\right\rangle / \tau\right)}{\sum_{x_{j} \in \mathcal{B}, j \neq i} \exp \left(\left\langle f_{\mathrm{v}}\left(x_{j}\right), f_{\mathrm{t}}\left(y_{i}\right)\right\rangle / \tau\right)}\right) L=−∣B∣1∑xi,yi∈B(∑yj∈B,j=iexp(⟨fv(xi),ft(yj)⟩/τ)exp(⟨fv(xi),ft(yi)⟩/τ)+∑xj∈B,j=iexp(⟨fv(xj),ft(yi)⟩/τ)exp(⟨fv(xi),ft(yi)⟩/τ))
- Short captions:caption model
- Local descriptions:object detection model。采用训练好的的目标检测器,以边界框的形式为我们提供可能物体的位置。
3.3.2 Candidate Synthesis
收集的视觉信息形式化为结构化的visual clues,可以直接用作语言模型的提示。
3.3.3 Candidate Selection
再次使用视觉语言模型,以选择最符合图像的candidate
S
=
argmax
T
i
,
i
=
1
,
⋯
,
K
⟨
f
v
(
I
)
,
f
t
(
T
i
)
⟩
.
S=\underset{T_{i}, i=1, \cdots, K}{\operatorname{argmax}}\left\langle f_{\mathrm{v}}(I), f_{\mathrm{t}}\left(T_{i}\right)\right\rangle .
S=Ti,i=1,⋯,Kargmax⟨fv(I),ft(Ti)⟩.
为了进一步排除
S
S
S中不相关的概念,在句子级再次过滤输出。这是因为大语言模型有时会出现hallucination 问题,即可能会在段落中生成不相关的句子。因此将其分成句子
(
s
1
,
s
2
,
⋯
,
s
U
)
(s_1, s_2, \cdots, s_U )
(s1,s2,⋯,sU),并使用阈值
γ
\gamma
γ来删除相似度较低的句子。
T
∗
=
(
s
i
∣
⟨
f
v
(
I
)
,
f
t
(
s
i
)
⟩
>
γ
,
i
=
1
,
⋯
,
U
)
T^{*}=\left(s_{i} \mid\left\langle f_{\mathrm{v}}(I), f_{\mathrm{t}}\left(s_{i}\right)\right\rangle>\gamma, i=1, \cdots, U\right)
T∗=(si∣⟨fv(I),ft(si)⟩>γ,i=1,⋯,U)
3.4 评估指标:SPIPE
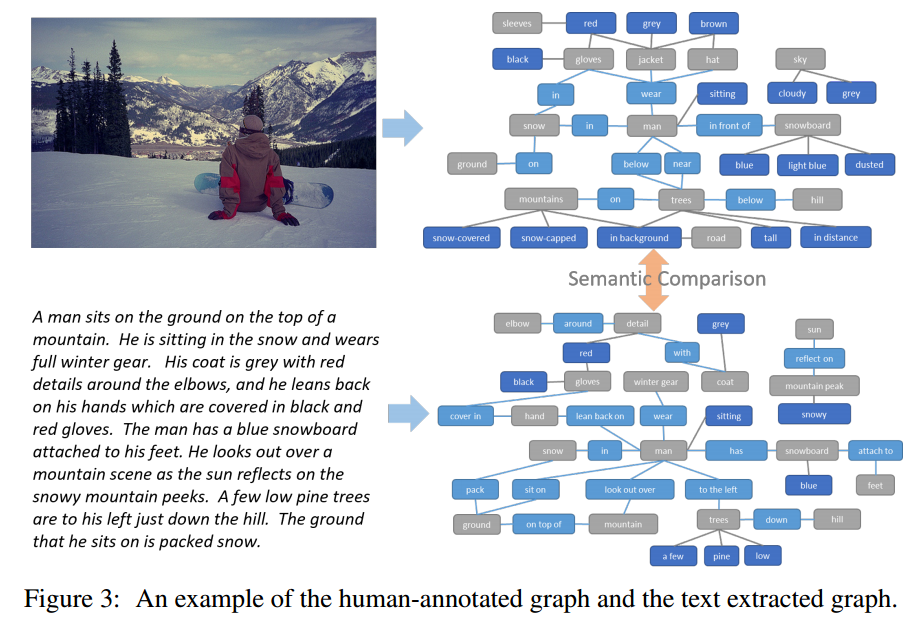
- 使用预训练的依赖性解析器来建立单词之间的合成依赖性。
- 使用基于规则的系统将依赖树映射到场景图
给定从文本和人类注释图中提取的场景图,指标基于三组概念的连接中两个图之间的同义词匹配来计算F分数(object), (object, attribute), and (object, relationship, subject)。
四一五学习笔记















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









