







原文链接:https://www.techbeat.net/article-info?id=3698
作者:刘迎飞、wangeniusky
本文提出了一个统一的纯视觉3D感知框架PETRv2。基于PETR,PETRv2探究了利用历史帧的信息来进行时序建模,大幅度地提升了3D物体检测的性能。具体来说,我们扩展了PETR中所提出的3D position embedding (3D PE)来进行时序建模,证明3D PE能够实现不同帧物体空间位置的对齐。进一步地,我们引入了一个特征引导的位置编码器,来改善3D PE对于不同输入数据的适应性。为使PETR框架能够同时进行高质量的BEV分割,PETRv2提供了一个简单而又高效的解决方案。我们引入了一些分割查询向量,每个分割查询变量用于分割BEV图像中特定的块区域。PETRv2在3D物体检测和BEV分割任务上均有着先进的性能表现。基于PETR系列框架,本文也进行了详细的鲁棒性分析,我们希望PETRv2能够作为一个简单而又强大的基线框架。

:::
论文名称:
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
论文链接:
https://arxiv.org/pdf/2206.01256.pdf
代码链接:
https://github.com/megvii-research/PETR,支持2080ti等低端显卡训练。
一、研究动机
近期,基于纯视觉(多个摄像头图像)的3D感知受到广泛关注。如何结合输入数据流的时序信息,并将3D检测、BEV分割等多项感知任务整合到一个统一的框架中具有重大意义。BEVFormer1和BEVDet4D2是近期比较有代表性的两个方法,通过结合时序建模实现了出色的检测性能。然而,这些方法大都选择bird-eye-view(BEV)空间进行时序的特征对齐,并利用BEV特征进行分割。考虑到重建得到的BEV特征相比于range view(RV)特征可能有信息损失,且特征之间的对齐往往需要自定义算子不利于硬件部署。于是,我们考虑是否可以不依赖于BEV特征来实现时序对齐并支持BEV分割。
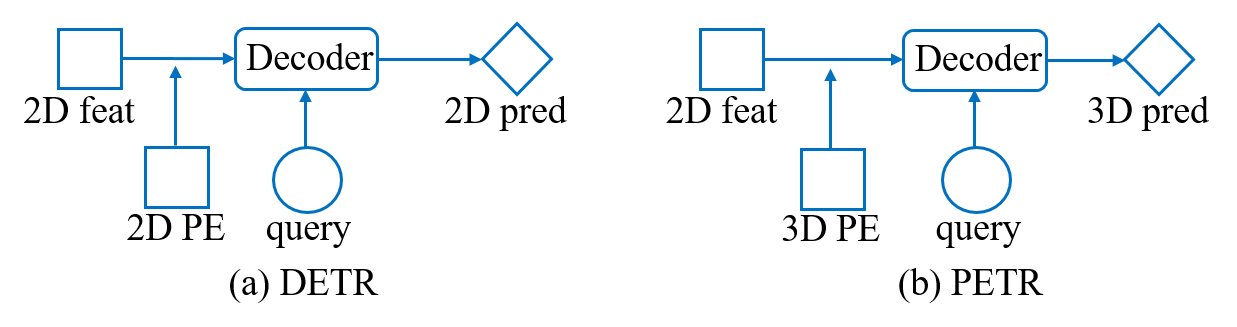
图一 DETR和PETR对比示意图,图来源于PETR。
:::
我们的方法主要启发于近期提出的PETR3框架。如图一所示,PETR基于DETR4框架,引入了3D position embeding(3D PE)的概念,将3D coordinates信息编码进2D RV特征使其对3D空间位置敏感,如此一来,query可以和RV特征直接在decoder中交互并预测3D检测结果,无需显式的空间变换。本文中,我们对PETR框架进行如下的几项改进:
-
我们将PETR中的3D PE扩展到时序版本,通过对生成的3D coordinates进行变换,实现了时序对齐。
-
PETR中,3D PE的生成是data-independent的,我们引入了一个特征引导的位置编码器,使得3D PE的生成和输入数据相关,隐式地从特征中获取到深度等信息。
-
我们引入了一个简单高效的方案来支持BEV分割。受SOLQ5启发,DETR框架中一个query足以表征一块区域内的掩码,为此我们定义若干个分割查询向量实现高质量的BEV分割。
二、方法
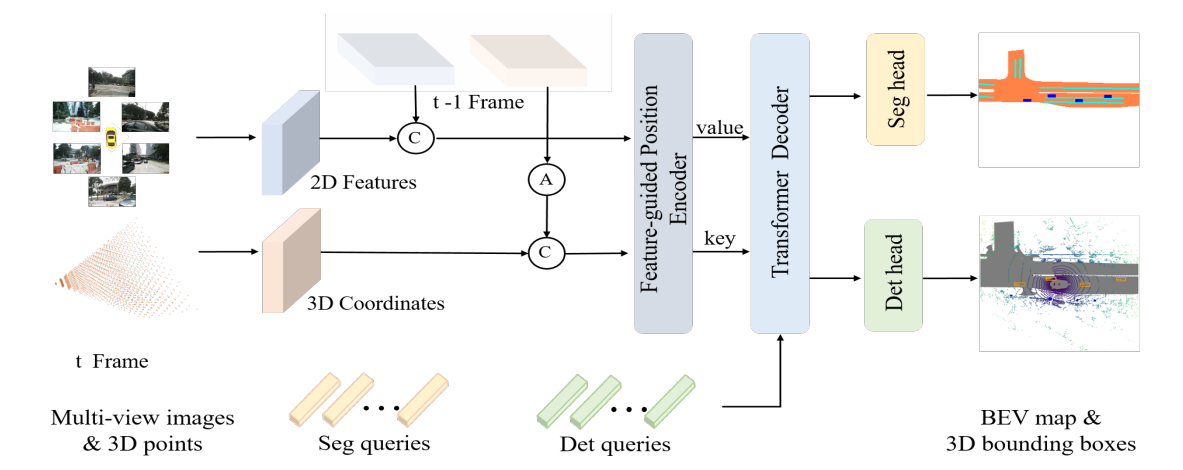
图二 PETRv2结构图。'A’表示时序对齐,'C’表示拼接操作。
:::
2.1 整体框架
如图二所示,PETRv2的框架主要基于PETR,其输入为前后两帧( t − 1 t-1 t−1 帧与 t t t 帧)的2D features和视锥空间中3D points所对应的3D coordinates。首先, t − 1 t-1 t−1 帧与 t t t 帧的3D Coordinates进行时序对齐(2.2节描述)并拼接到一起,两帧的特征则直接进行拼接。然后,2D features和3D coordinates输入到特征引导的位置编码器(2.3节描述)中,将对齐后的3D Coordinates转换为3D position embeding (3D PE),并与2D features相结合,生成后续Transformer解码器(2.4节描述)的key、value元素。之后,seg query、det query与前述生成的key、value在Transformer decoder中进行交互。最后,交互更新后的两类query送入两个任务的head,输出检测和分割结果。
2.2 时序对齐
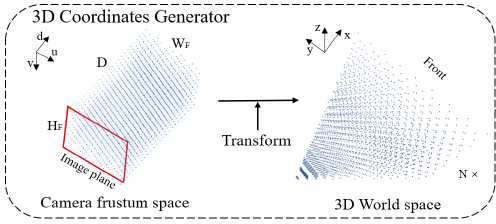
图三 PETR中3D Coordinates生成,图来源于PETR。
:::
我们选择Lidar坐标系 l ( t ) {l(t)} l(t) 作为3D检测空间,并使用 T s r c d s t T^{dst}_{src} Tsrcdst 表示从源坐标系到目的坐标系的变换。如图三所示,和PETR中类似,我们首先在视锥空间定义一组meshgrid点集 P m ( t ) {P^{m}(t)} Pm(t) , 并使用下面的公式将meshgrid点集根据每个视角的相机内外参转换到3D空间,得到对应的3D Coordinates。
P i l ( t ) ( t ) = T c i ( t ) l ( t ) K i − 1 P m ( t ) P^{l(t)}_i(t) = T^{l(t)}_{c_i(t)} K^{-1}_{i} P^{m}(t) Pil(t)(t)=Tci(t)l(t)Ki−1Pm(t)
其中 K i − 1 {K^{-1}_{i}} Ki−1 是第 i i i 个视角的相机内参, T c i ( t ) l ( t ) {T^{l(t)}_{c_i(t)}} Tci(t)l(t) 是第 i i i 个相机到3D空间 l ( t ) {l(t)} l(t) 的变换矩阵。考虑到由于自车的运动,前后两帧的坐标原点并不统一,因此需要将 t − 1 t-1 t−1 帧的3D Coordinates对齐到 t t t 帧的坐标系下,具体变换如下面公式所示:
P i l ( t ) ( t − 1 ) = T l ( t − 1 ) l ( t ) P i l ( t − 1 ) ( t − 1 ) P^{l(t)}_i(t-1) = T^{l(t)}_{l(t-1)} P^{l(t-1)}_i(t-1) Pil(t)(t−1)=Tl(t−1)l(t)Pil(t−1)(t−1)
其中 T l ( t − 1 ) l ( t ) {T^{l(t)}_{l(t-1)}} Tl(t−1)l(t) 是两帧之间坐标系的变换公式,由下式计算得到:
T l ( t − 1 ) l ( t ) = T e ( t ) l ( t ) T g e ( t ) T g e ( t − 1 ) − 1 T e ( t − 1 ) l ( t − 1 ) − 1 T^{l(t)}_{l(t-1)} = T^{l(t)}_{e(t)} T^{e(t)}_{g} {T^{e(t-1)}_{g}}^{-1} {T^{l(t-1)}_{e(t-1)}}^{-1} Tl(t−1)l(t)=Te(t)l(t)Tge(t)Tge(t−1)−1Te(t−1)l(t−1)−1
e ( t ) {e(t)} e(t) 和 e ( t − 1 ) {e(t-1)} e(t−1) 表示不同时刻的自车坐标系, g {g} g 表示全局的世界坐标系。
2.3 特征引导的位置编码器
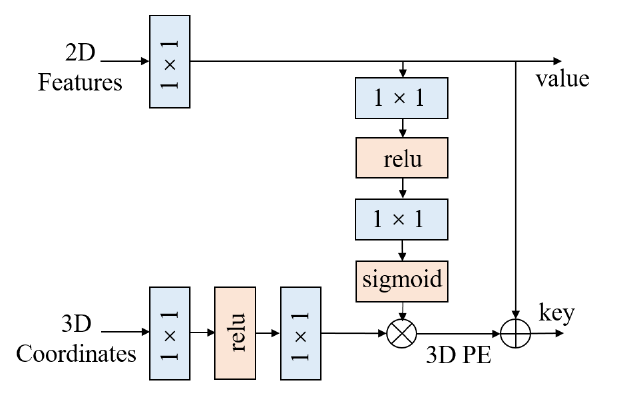
图四 特征引导的位置编码器
:::
在PETR中,所获得的3D Coordinates经过一个简单的多层感知机MLP映射得到位置特征,直接作为3D PE。如图四所示,我们对3D PE的生成方式进行了一个简单的改进。RV视角的2D feature经过一个多层感知机MLP和一个sigmoid层生成一组权重,对PETR中MLP转换后的位置特征加权,从而得到了data-dependent的3D PE。关于这一点改进,主要源于我们对3D PE的两点思考:
-
2D feature本身包含许多先验信息,比如depth信息等,有助于为RV的不同空间位置生成更有区分度的3D PE。
-
3D Coordinates的生成可能受到内外参噪声的影响,采用data-dependent的形式,在一定程度上是对3D PE的隐式修正,有助于提升网络对内外参扰动的鲁棒性。
2.4 Transformer解码器
为了便于部署,我们使用DETR中最原始的Transformer解码器。解码器的检测分支和PETR4类似,我们在3D空间下定义一组可学习的anchor points,通过MLP网络生成det queries,然后与前述的位置编码器生成的key、value元素进行交互。
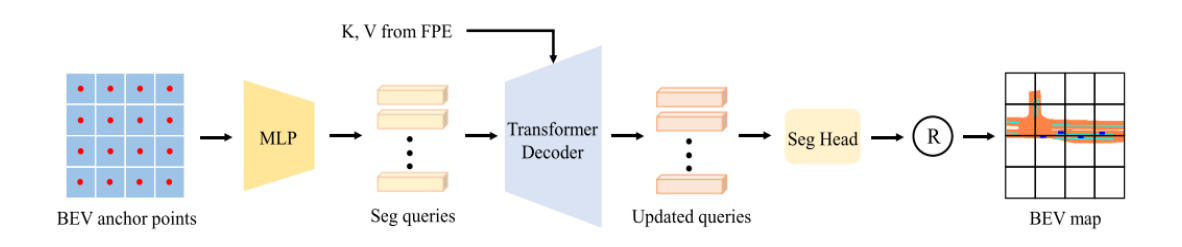
图五 分割分支
:::
分割分支的结构如图五所示。不同于检测分支,我们首先在BEV空间下定义一组固定的anchor points,每个anchor point负责 16 × 16 {16\times16} 16×16 大小patch的mask预测。anchor points的总数为 16 × 16 = 256 {16\times16=256} 16×16=256 ,通过一个MLP网络生成256个seg queries,并在Transformer解码器中和K、V元素进行交互。交互更新后的seg queries,输入到分割头网络(一个MLP网络),之后通过reshape和拼接操作,最终输出一个 256 × 256 {256\times256} 256×256 的分割结果。
2.5 鲁棒性分析

图六 典型的系统误差
:::
如上图所示,我们对以下几种典型的误差场景进行鲁棒性分析:(a)由路面不平整带来的外参扰动。(b)行驶过程中,摄像头被意外遮挡的情况。(c)相机曝光时间不准确导致的时延现象。
三、实验结果
3.1 SOTA比较
我们在广泛使用的nuScenes6数据集上测试了PETRv2的3D检测和BEV分割性能,并与其他方法进行了对比。具体结果如下:
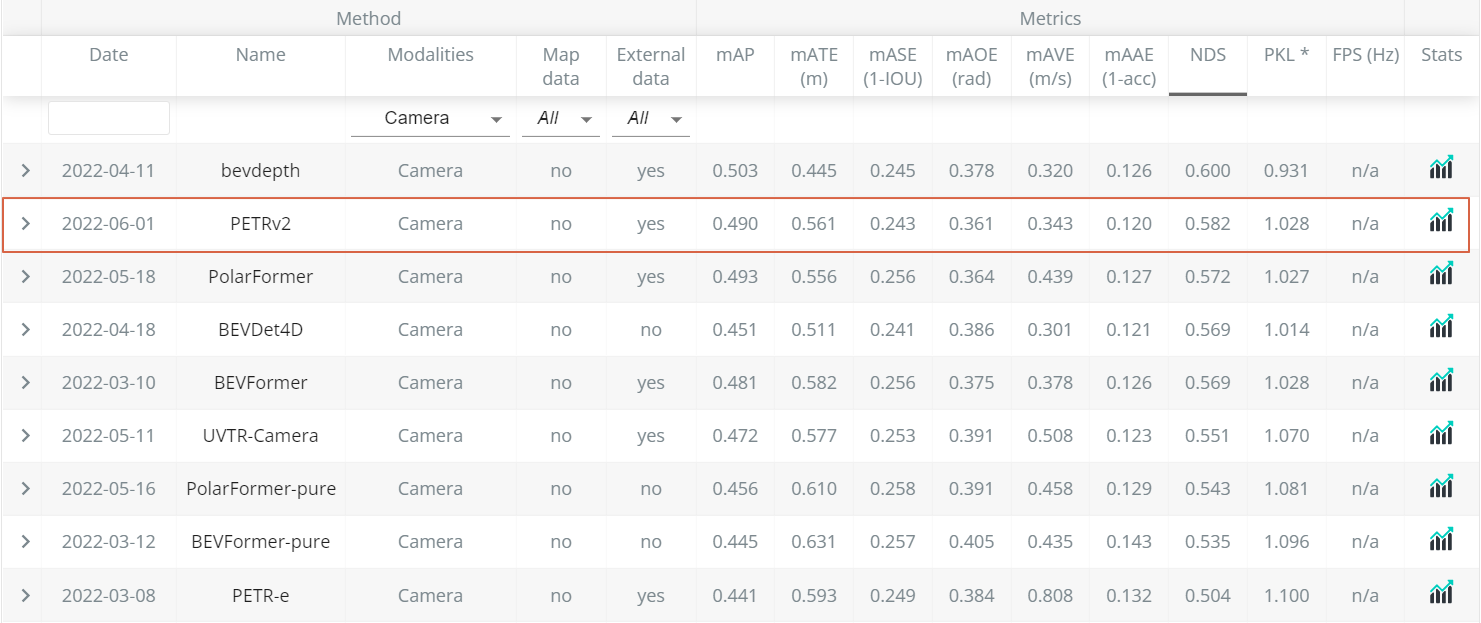
表一 nuScenes 纯视觉3D检测榜单
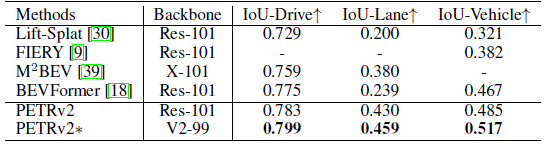
表二 nuScenes验证集的BEV分割结果
:::
可以看到PETRv2在3D检测、BEV分割任务上都取得了SOTA的性能。在纯视觉3D检测榜单上,在没有使用TTA的情况下,PETRv2超过了此前时序建模的BEVDet4D和BEVFormer。而在BEV分割任务上的性能也高于其他方法,尤其是在车道线分割方面取得了大幅领先。
3.2 Ablation 实验
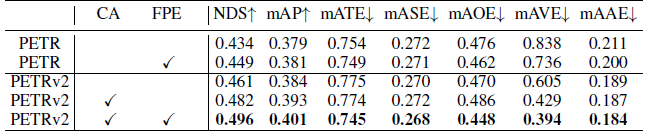
表三 时序对齐(CA)和特征引导的位置编码器(FPE)
:::
如表三所示,我们首先进行了时序对齐(CA)和特征引导的位置编码器(FPE)的对比实验。我们可以看到,PETRv2在不进行时序对齐的情况下,mAVE只能达到0.605,而在时序对齐之后,mAVE可以大幅度地减少到0.429。关于FPE,我们在PETRv1和PETRv2上均进行了对比实验,实验结果表明其在单帧和多帧的情况下,均可以取得性能的提升。
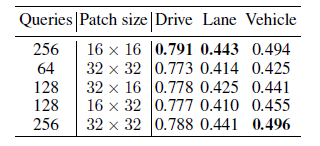
表四 seg query生成
:::
之后,我们对seg query的数量以及每个seg query所负责patch区域大小进行对比实验。如表四所示,实验发现当使用256个seg queries时,即每个query负责的patch大小为 16 × 16 {16\times16} 16×16 时效果最好。
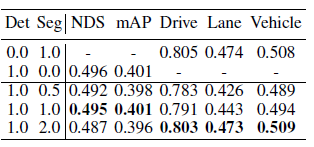
表五 检测和分割权重
:::
最后,对于检测和分割分支的权重,我们也进行了一定的分析(如表五所示)。实验表明,当两者权重都为1.0时,检测分支相比于只有检测分支来说几乎不掉点。当分割权重为2.0时,分割效果有一定的提高,但检测会轻微掉点。这说明3D检测和BEV分割两项任务存在一定的表征差距。在实际应用时,作为权衡,我们将两者权重设为1:1。
3.3 鲁棒性分析

表六 外参鲁棒性
:::
我们首先对外参鲁棒性进行分析,其中R表示测试时外参上旋转的度数,当旋转2度时PETRv2只会掉1%左右,当旋转角度达到8度时PETRv2会掉4.12%mAP和2.85%NDS,掉点幅度并不是很大。此外单帧的鲁棒性上,我们发现FPE模块可以增强模型的鲁棒性。
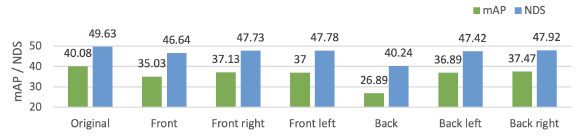
表七 摄像头鲁棒性
:::
我们对camera遮挡的情况也进行了分析,如上表所示。我们发现Back摄像头对结果的影响最大,这应该和Back摄像头FOV较大有关。

表八 时延鲁棒性
:::
对于时延,我们随机将一个摄像头当前帧的数据替换为sweep的数据,来模拟实验的结果。其中,一个T约表示0.083秒。我们发现,当发生1T的延时时,PETRv2掉点3.19%mAP。
四、结语
我们提出了PETRv2,一个统一的纯视觉3D感知框架。通过3D position embedding的对齐,实现多帧之间的时序对齐,不需要自定义的算子,大幅提升3D检测的性能;为实现3D检测与BEV分割的统一,我们仅添加少量的query便可实现高精度的分割性能。在3D目标检测和BEV分割上的实验验证了PETRv2的显著效果,超过了以往的先进方法。在未来的工作中,我们期待将PETRv2扩展到更多的3D感知任务。
五、参考文献
- [1] Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, andJifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. arXiv preprint arXiv:2203.17270, 2022.
- [2] Junjie Huang and Guan Huang. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. arXiv preprint arXiv:/2203.17054, 2021.
- [3] Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transformation for multi-view 3d object detection. arXiv preprint arXiv:2203.05625, 2022.
- [4] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. End-to-End Object Detection with Transformers. arXiv preprint arXiv:2005.12872, 2020.
- [5] Bin Dong, Fangao Zeng, Tiancai Wang, Xiangyu Zhang, and Yichen Wei. Solq: Segmenting objects by learning queries. Advances in Neural Information Processing Systems, 34, 2021.
- [6] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com















 2613
2613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









