







原文链接:https://www.techbeat.net/article-info?id=4204
作者:seven_
本文的重点研究对象是在视觉领域占据统治地位的残差神经网络(ResNets),ResNets以其精巧的残差结构可以胜任绝大多数视觉任务。本文假设Neural ODE可以模拟ResNets的连续变换,作者首先量化ResNets的隐藏层状态轨迹与其对应的Neural ODE的解之间的距离,随后发现使用梯度下降算法优化ResNets得到的平滑性,可以以一定的速率对Neural ODE进行正则化,并且其能达到的深度以及所需的优化时间与梯度下降算法一致。

论文链接:
https://arxiv.org/abs/2205.14612
以微分方程的概念来审视和解释神经网络是近年来兴起的一个新的研究方向,研究者们首先假设特定类型的神经网络可以看作是离散的微分方程,所以可以使用现成的微分方程求解器来进行计算,希望可以得到效果更好且具有强解释性的结果。神经常微分方程(Neural ODE)的核心操作是对网络隐藏层状态的导数进行参数化,进而建立起与隐藏层强相关的微分方程,如果可以使用某种手段直接将中间层的结果求解出来,Neural ODE有望可以避免复杂且大量重复的反向传播过程。
本文的重点研究对象是在视觉领域占据统治地位的残差神经网络(ResNets),ResNets以其精巧的残差结构可以胜任绝大多数视觉任务。本文假设Neural ODE可以模拟ResNets的连续变换,作者首先量化ResNets的隐藏层状态轨迹与其对应的Neural ODE的解之间的距离,随后发现使用梯度下降算法优化ResNets得到的平滑性,可以以一定的速率对Neural ODE进行正则化,并且其能达到的深度以及所需的优化时间与梯度下降算法一致。
基于该发现,作者提出可以使用无记忆(memory-free)的离散伴随方法(adjoint method)来训练ResNets,并且证明该方法在理论上可以支持较深层ResNets的训练,作者随后进行了实验,并对非常深层次的预训练ResNets进行微调,得到了更好的效果,并且网络不会在残差层中消耗显存。该文目前已经被人工智能领域顶级会议NeurIPS 2022接收。
一、 什么是神经常微分方程(Neural ODE)
目前较为常用的神经网络,例如残差网络都是通过堆叠一系列的转换块(transformations)或残差块来形成一个隐层状态以建立复杂的转换,
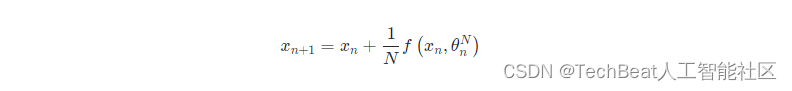
其中网络的深度为
N
N
N ,
f
f
f 为残差网络,当随着网络的层数不断加深,网络推理计算的每一步都足够小时,即接近极限时,我们对网络的隐藏层神经元的连续动态进行参数化,就可以得到对应的Neural ODE,
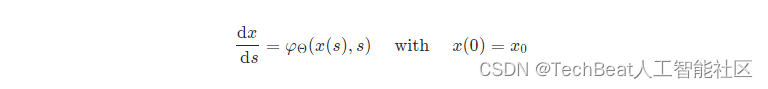
其中
φ
Θ
\varphi_{\Theta}
φΘ 是考虑时间
s
s
s 的神经网络,从输入层
x
(
0
)
x(0)
x(0) 开始我们可以将输出层
x
(
s
)
x(s)
x(s) 定义为在某时刻
s
s
s 上常微分方程(ODE)初值问题的解,这个值可以通过一个常微分方程求解器进行计算。
这样做有什么好处呢,其实无论是什么结构的神经网络,本质上都是在拟合一个复杂的非线性复合函数,其中复合的次数其实等价于神经网络的层数,要对网络进行求解,首先需要找到网络参数的梯度,这就涉及到链式法则,其要求在网络前向传播的过程中保留所有层的激活值,并且在反向传播的时候再利用这些激活值进行计算,这对设备内存或显存的占用非常大,因此一般情况下无法训练很深层数的网络。
而对于Neural ODE来说,可以直接通过方程求解器来计算网络梯度,但是当网络的层数较深时,计算的误差会逐渐累加,因此引入了一个伴随状态方法(Adjoint State Method)来计算ODE的梯度,该方法将网络梯度的计算转化为解一个ODE,随后可以将隐藏层状态的导数作为一个参数,这样参数就不是原本的离散序列,而是一个连续的向量场(vector field),因此就不需要前向传播去一一计算,也就不需要耗费大量空间来保存中间结果了。
综上所述,Neural ODE框架可以使用伴随状态方法在不存储激活值 x n ’s x_{n} \text {'s } xn’s 的情况下进行网络学习,因此显著减少了原本反向传播时的大量内存使用空间,同时也提供了一个理论框架,从ODE的连续视角来研究深度学习模型。
二、本文方法
本文详细研究了ResNets与Neural ODEs之间的联系,即ResNets可以被视为一组特定Neural ODE的离散化。作者首先为给定的ResNet网络定义了一组相关的Neural ODE,分别通过控制其离散轨迹和连续轨迹之间的误差,随后作者发现,如果不对ResNets网络的权重参数进行额外的规律性假设,仅靠常用的普通权重初始化方法,会导致残差函数随着网络深度加深而缺乏平滑性,进而无法得到最大深度限制下的Neural ODE。直观地说,如果网络权重被初始化为彼此接近的情况,如果使用梯度下降算法来更新它们,它们在训练期间仍然会保持彼此接近,因为两个连续层中的梯度计算是类似的,下面的ResNets损失函数
L
(
x
N
)
L\left(x_{N}\right)
L(xN) 的反向传播方程就表明了这一点:
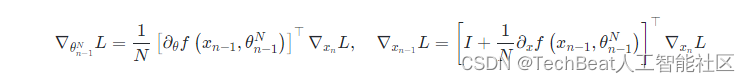
此外作者也观察到,如果
x
n
x_n
xn 与
x
n
+
1
x_{n+1}
xn+1 接近,则
∇
x
n
L
\nabla_{x_{n}}L
∇xnL 与
∇
x
n
+
1
L
\nabla_{x_{n+1}} L
∇xn+1L 也接近,如果
θ
n
N
\theta_{n}^{N}
θnN 与
θ
n
+
1
N
\theta_{n+1}^{N}
θn+1N 接近,则
∇
θ
n
N
L
\nabla_{\theta_{n}^{N}} L
∇θnNL 与
∇
θ
n
+
1
N
L
\nabla_{\theta_{n+1}^{N}} L
∇θn+1NL 也同样接近。基于这一观察,作者对ResNets的线性残差函数版本进行了研究,也作为对ResNets与Neural ODE之间理论联系的进一步探索。这时的残差函数可以写为
f
(
x
,
θ
)
=
θ
x
f(x, \theta)=\theta x
f(x,θ)=θx,其中
θ
∈
R
d
×
d
\theta \in \mathbb{R}^{d \times d}
θ∈Rd×d,其对应很多深度矩阵分解问题[1][2],但本文与之前的这些工作相反,作者重点研究的是这些线性ResNets的无限深度限制,以及在无限网络深度情况下的权重的学习。
2.1 最大深度限制的极限Neural ODE
作者进一步研究发现,如果给定一些假设,例如设置网络具有较小的初始化损失,并且当网络层数趋于无穷大时,ResNets可以直接收敛到Neural ODE,并且这种收敛与当前网络深度和优化时间保持一致。首先给定一个训练样本集合
(
x
k
,
y
k
)
k
∈
[
n
]
\left(x_{k}, y_{k}\right)k \in[n]
(xk,yk)k∈[n],作者使用线性ResNets来解决将
x
k
x_{k}
xk 映射到
y
k
y_{k}
yk 的回归问题,即
f
(
x
,
θ
)
=
θ
x
f(x, \theta)=\theta x
f(x,θ)=θx,其中网络的深度为
N
N
N,参数列表为
(
θ
1
N
,
…
,
θ
N
N
)
\left(\theta_{1}^{N}, \ldots, \theta_{N}^{N}\right)
(θ1N,…,θNN)。ResNets随后将
x
k
x_{k}
xk 转换到
Π
N
x
k
\Pi^{N} x_{k}
ΠNxk,
Π
N
:
=
∏
n
=
1
N
(
I
d
+
θ
n
N
N
)
=
(
I
d
+
θ
N
N
N
)
⋯
(
I
d
+
θ
1
N
N
)
\Pi^{N}:=\prod_{n=1}^{N}\left(I_{d}+\frac{\theta_{n}^{N}}{N}\right)=\left(I_{d}+\frac{\theta_{N}^{N}}{N}\right) \cdots\left(I_{d}+\frac{\theta_{1}^{N}}{N}\right)
ΠN:=∏n=1N(Id+NθnN)=(Id+NθNN)⋯(Id+Nθ1N),随后使用最小平均误差进行训练
∥
Π
N
x
k
−
y
k
∥
2
2
\left\|\Pi^{N} x_{k}-y_{k}\right\|_{2}^{2}
∥
∥ΠNxk−yk∥
∥22,此时问题等价于深度矩阵分解问题:
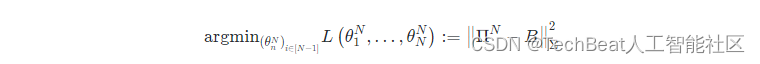
随后求梯度得:
∇
n
N
(
t
)
=
∇
θ
n
N
L
(
θ
1
N
(
t
)
,
.
.
θ
n
N
(
t
)
,
.
.
,
θ
N
N
(
t
)
)
\nabla_{n}^{N}(t)=\nabla_{\theta_{n}^{N}} L\left(\theta_{1}^{N}(t), . . \theta_{n}^{N}(t), . ., \theta_{N}^{N}(t)\right)
∇nN(t)=∇θnNL(θ1N(t),..θnN(t),..,θNN(t)),再根据链式法则得到
N
∇
n
N
=
Π
:
n
N
⊤
(
Π
N
−
B
)
Σ
Π
n
:
N
⊤
N \nabla_{n}^{N}=\Pi_{: n}^{N \top}\left(\Pi^{N}-B\right) \Sigma \Pi_{n:}^{N \top}
N∇nN=Π:nN⊤(ΠN−B)ΣΠn:N⊤,直观的讲,随着
N
N
N 趋于
+
∞
+\infty
+∞,
Π
N
,
Π
:
n
N
⊤
,
Π
n
:
N
⊤
\Pi^{N},\Pi_{: n}^{N \top},\Pi_{n:}^{N \top}
ΠN,Π:nN⊤,Πn:N⊤ 都应该收敛到某个极限,因此可以断定
N
∇
n
N
N \nabla_{n}^{N}
N∇nN 的尺度为1,随后就可以通过尺度缩放后的梯度流
d
θ
n
N
d
t
(
t
)
=
−
N
∇
n
N
(
t
)
\frac{d \theta_{n}^{N}}{d t}(t)=-N \nabla_{n}^{N}(t)
dtdθnN(t)=−N∇nN(t) 来优化
L
L
L 以训练网络
θ
n
N
\theta_{n}^{N}
θnN,并且定义
ℓ
N
(
t
)
=
L
(
θ
1
N
(
t
)
,
…
,
θ
N
N
(
t
)
)
\ell^{N}(t)=L\left(\theta_{1}^{N}(t), \ldots, \theta_{N}^{N}(t)\right)
ℓN(t)=L(θ1N(t),…,θNN(t)),其中涉及到两个连续变量,
s
∈
[
0
,
1
]
s \in[0,1]
s∈[0,1] 是极限网络的深度,对应于Neural ODE中的时间变量,而
t
∈
R
+
t \in \mathbb{R}_{+}
t∈R+ 对应于梯度流的时间变量,作为线性网络梯度下降收敛分析的标准,作者给出了如下假设:
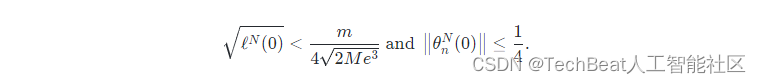
该假设是深度网络训练达到收敛的经典假设,用于证明损失函数的线性收敛情况
θ
n
N
(
t
)
\theta_{n}^{N}(t)
θnN(t)与
t
t
t 保持一致。如果在网络进行初始化时,能够保证两个连续参数之间的差异在
O
(
1
N
)
O\left(\frac{1}{N}\right)
O(N1) 内,其离散导数差异也保持在
O
(
1
N
)
O\left(\frac{1}{N}\right)
O(N1) 内,就可以将网络的权重收敛到一个函数域内,因而也就能得到上文提到的最大深度限制的极限Neural ODE。
2.2 为ResNets网络量身定制的伴随状态方法(Adjoint Method)
上文提到,在Neural ODE框架中引入了伴随状态方法来计算ODE的梯度,这其实也是Neural ODE的一个非常有用的特性并且对ResNets具有适用性,根据伴随方法的无记忆反向传播机制,可以尝试使用Neural ODE的反向离散化对ResNets进行任意平滑插值,这相当于直接定义
x
~
N
=
x
N
\tilde{x}_{N}=x_{N}
x~N=xN ,并且使其在
n
∈
{
N
−
1
,
…
0
}
n \in\{N-1, \ldots 0\}
n∈{N−1,…0} 范围内进行迭代
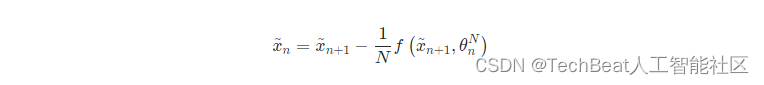
然后可以使用近似的激活值
(
x
~
n
)
n
∈
[
N
]
\left(\tilde{x}_{n}\right)_{n \in[N]}
(x~n)n∈[N] 作为真实激活
(
x
n
)
n
∈
[
N
]
\left(x_{n}\right)_{n \in[N]}
(xn)n∈[N] 的代理来在事先不存储激活值的情况下计算网络的梯度:
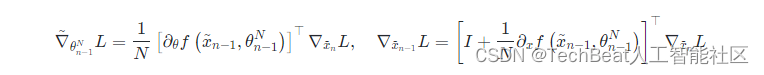
以这种方式对网络激活值进行恢复可以部署在任何结构的ResNet中,无需对特定架构和前向传播规则进行修改,唯一的缺点是其恢复的只是近似值,作者随后提出可以使用Heun方法[3]来减少其中的误差,Heun方法是一种二阶积分方案,其已被证实可以在网络深度的平滑度层面提高激活值恢复的能力,考虑一个深度为
N
N
N 的HeunNet,参数为
θ
1
N
,
…
,
θ
N
N
\theta_{1}^{N}, \ldots, \theta_{N}^{N}
θ1N,…,θNN,迭代
n
n
n 次可得到:

这一系列前向迭代计算
n
n
n次后,执行反向离散化近似得到:
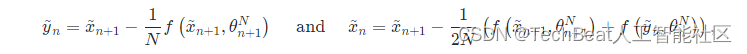
这种操作也可以在不存储激活值的情况下实现近似的反向传播,并且在离散ODE的情况下,Heun方法具有更好的
O
(
1
N
2
)
O\left(\frac{1}{N^{2}}\right)
O(N21) 误差。此外作者观察到当网络的权重与深度平滑保持一致时,Heun方法可以达到更好的梯度估计,等效的来看,当我们固定网络的深度时,HeunNets使用伴随方法相比ResNets会有更好的梯度估计,最终也可以通过这种无激活记忆的模型得到更好的训练效果和更佳的整体性能。
三、实验分析
本文的实验部分主要在CIFAR-10和ImageNet上进行,主要的实验结果如下图所示,
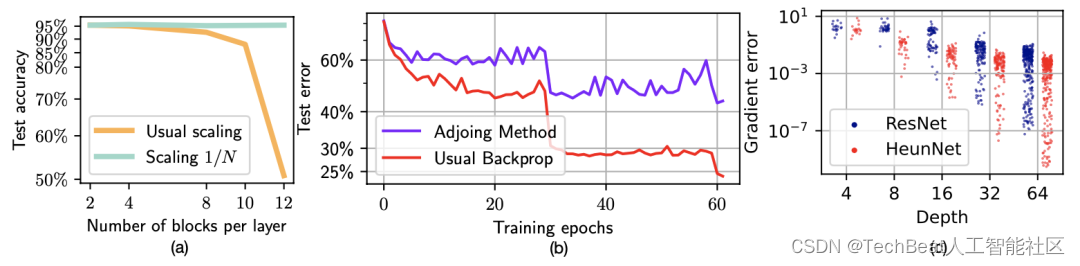
上图(a)表示对ResNet每一层中设置不同块数对整体测试准确度的影响,图(b)表示在ImageNet数据集上使用ResNet-101架构的伴随方法的失败性能,由于这里只对网络的第三层计算近似梯度,且其中包含了23个块。图(c)展示了使用伴随方法求得的近似梯度与真实梯度之间的相对误差,同时包含了ResNet和HeunNet的结果。

为了进一步研究本文提出的伴随方法在训练更深的ResNets中的适用性,作者在CIFAR数据集上训练了一个简单的ResNet模型,输入由16个输出通道的5 × 5卷积处理,图像被下采样到10×10大小,作者重点观察了深度
N
N
N对网络性能的影响,模型越深,其在测试准确性方面的表现就越好,然后,作者分别使用ResNet的前向规则和HeunNet的前向规则来比较模型的性能。并且使用经典反向传播或使用伴随方法的相应代理来训练网络。实验结果如上图所示,可以观察到近似梯度在小深度会导致较大的测试误差,但在大深度会提供相同的性能。此外对于HeunNet而言,在较大深度时预先得到的平滑度意味着HeunNet会比ResNet更快的收敛到真实梯度,这表明架构越深,梯度的近似值就越好,综合来看,HeunNet比ResNet更接近真实梯度,整体性能更好。
四、总结
本文提出了一种理论分析框架来分析ResNets与Neural ODE离散程度之间的关系,本文的理论证明在线性情况下得到了非常积极的预测结果,作者也在实际网络架构的实验中发现,使用所提出的ResNet专用伴随方法在CIFAR数据集上可以成功的训练的非常深的ResNets网络(甚至更高效的HeunNets)。此外本文的工作也为在小损失初始化情况下的线性设置中收敛到Neural ODE提供了理论保证,作者提到,对于本文而言,一个很自然的扩展就是研究非线性的情况。此外,由于目前的伴随方法比较耗时,可以在此基础上提出一种比反向离散化更加轻量的方法来近似恢复梯度。
参考文献
[1] Linnan Wang, Jinmian Ye, Yiyang Zhao, Wei Wu, Ang Li, Shuaiwen Leon Song, Zenglin Xu, and Tim Kraska. Superneurons: Dynamic gpu memory management for training deep neural networks. In Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, pages 41–53, 2018.
[2] Peter Bartlett, Dave Helmbold, and Philip Long. Gradient descent with identity initialization efficiently learns positive definite linear transformations by deep residual networks. In International conference on machine learning, pages 521–530. PMLR, 2018.
[3] Mehrdad Maleki, Mansura Habiba, and Barak A Pearlmutter. Heunnet: Extending resnet using heun’s method. In 2021 32nd Irish Signals and Systems Conference (ISSC), pages 1–6. IEEE, 2021.
Illustration by Delesign Graphics from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com















 3291
3291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









