







“ Shikra:解锁多模态语言模型参考对话的魔法”
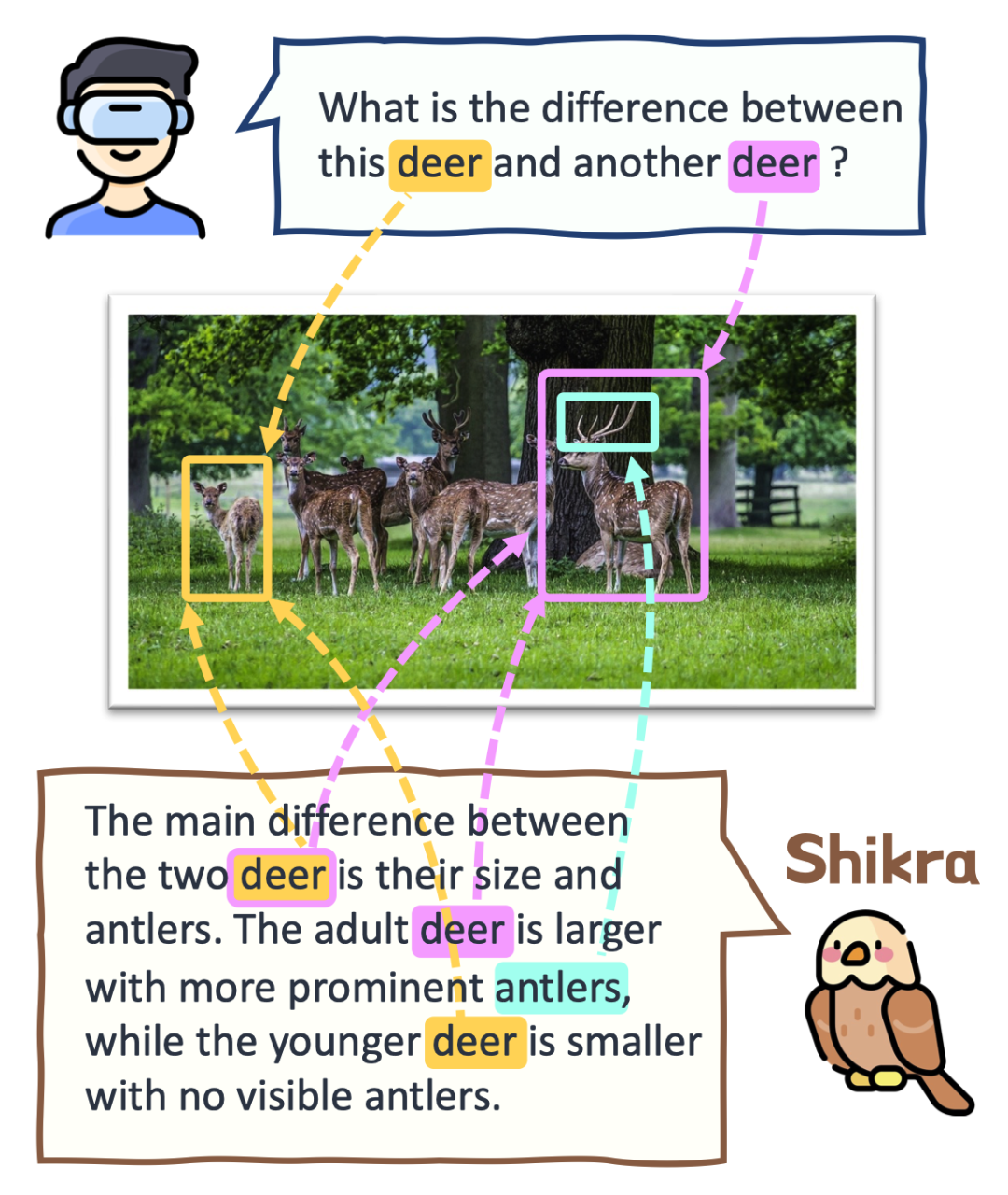
Shikra和用户的对话案例
在人类的日常交流中,经常会关注场景中的不同区域或物体,双方都可以通过说话并指向这些区域来进行高效的信息交换。我们将这种对话模式称为参考对话(Referential Dialogue)💬;
如果多模态大语言模型(MLLM) 擅长这项技能,它将带来许多令人兴奋的应用。例如,将其应用到 Apple Vision Pro 等混合现实 (XR) 眼镜中,用户可以使用视线注视指示任何内容与AI对话。同时AI也可以通过高亮等形式来提示某些区域,实现与用户的高效交流;
本工作提出了 Shikra 模型,赋予了MLLM这样的参考对话的魔法,既可以理解位置输入,也可以产生位置输出。

论文链接:http://arxiv.org/abs/2306.15195
代码链接:GitHub - shikras/shikra
01 工作亮点
-
Shikra 能够理解用户输入的 Point/Box,并支持 Point/Box 的输出,可以和人类无缝地进行参考对话;
-
Shikra 设计简单统一,采用非拼接式设计,直接使用数字表示坐标,不需要额外的位置编码器、前/后目标检测器或外部插件模块,甚至不需要额外的词汇表。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









