







本文提出了一种简单而有效的基于LLMs的图数据增强策略,称为LLMRec,以增强基于内容的推荐系统。LLMRec包含三种数据增强策略和两种去噪策略。数据增强策略包括从文本自然语言的角度挖掘潜在的协同信号, 构建用户画像(LLM-based), 并强化item side information(LLM-based)。去噪则是分别针对增强的边和特征来进行drop和masked auto-encoder的操作。实验在真实的基于内容的推荐系统数据集上进行(Netflix, MovieLens),数据集与代码均已开源。目前LLMRec已经被WSDM2024录取接收为oral presentation.

论文题目:
LLMRec: Large Language Models with Graph Augmentation for Recommendation
论文链接:
01. 背景问题和解决思路
1.1 多模态推荐背景
多模态推荐系统引入多种辅助内容,有助于解决推荐系统中的数据稀疏性问题。当前主流的推荐系统(如亚马逊、Netflix)都采用了多种模态内容,例如文字标题、视觉图片和视频、背景音乐,以吸引用户并提升推荐结果的质量。通过提供吸引人的多模态内容,即使在冷启动和会话推荐场景下,也能够迅速捕捉到用户的真实个性化偏好。
1.2 基于内容的推荐存在的问题与解决方案
然而,辅助的多模态内容使用时不可避免地引入一些问题,如噪声和低质量内容。受到LLMs在知识储备和自然语言理解能力方面的启发,这篇工作提出了使用LLM来增强多模态内容,以解决上述问题。展开来讲,将大型语言模型(LLMs)应用于推荐系统已成为最近的研究热点,而如何有效地将LLMs应用于推荐系统一直是一个未解决的问题。
一方面,经典的协同过滤(CF)范式经过多年的发展,已经成为学术界和业界共同努力下最有效的范式。另一方面,LLMs存在幻觉问题(Hallucination),因此很难适应需要准确预测用户偏好的推荐系统。本研究提出一种将LLMs用于推荐系统的数据增强方法,即利用LLMs丰富的知识和卓越的自然语言理解能力基于文本模态来进行推荐系统的增强。具体而言,LLMRec利用LLM来增强两个方面的内容:用户与物品之间的交互和文本模态的信息,包括用户画像和物品属性。这种方法既能保证基本推荐系统的准确性,又充分利用数据集中的文本信息和大型语言模型的能力,强调了将LLMs用于增强推荐系统的意义。
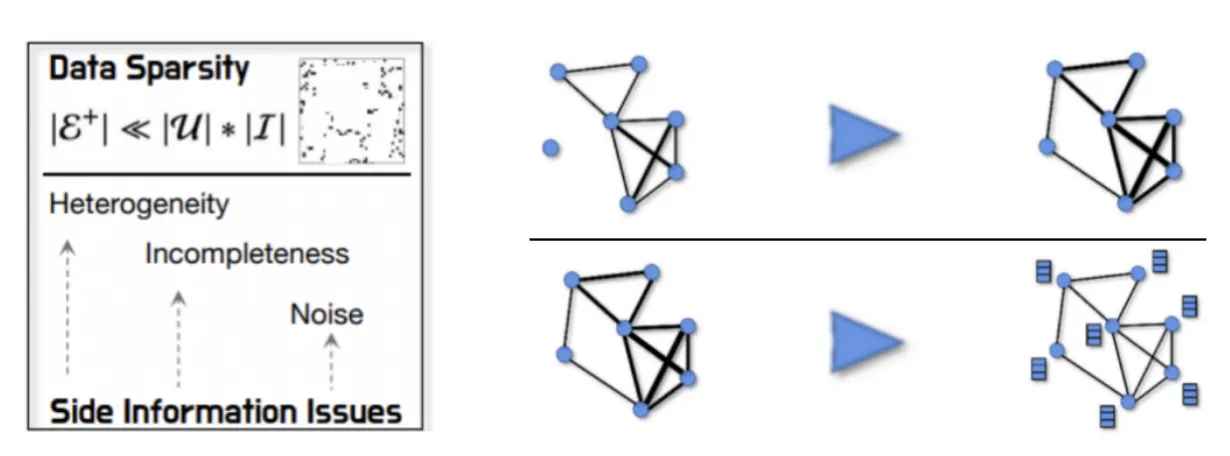
此外,为了确保增强数据的可靠性,LLMRec采取了以下措施针对上述两个方面:i) 设计了用户与物品交互的剪枝策略,以排除不可靠的交互信息;ii) 使用MAE(Masked Auto-Encoder,掩码自编码器)技术对物品特征进行处理,以使编码器更鲁棒能够不敏感于噪声和低质量内容的干扰。通过LLM增强多模态内容,这篇工作能够在约束噪声的情况下有效解决推荐系统中的噪声和低质量问题,提高推荐结果的准确性和个性化程度。这种方法不仅能够改善用户体验,还有助于推动推荐系统在各个应用领域的发展。
1.3 拥有辅助信息推荐系统的数据增强范式
普通的有基础模态信息内容的推荐系统输入:由模态信息编码的特征 F + 历史交互的隐式反馈。
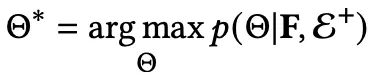
有数据增强
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3257
3257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









