







Tim Hunter在databricks博客发布博文,演示如何使用TensorFlow和Spark一起训练和应用深度学习模型。
两个use cases:
- 超参数调整:用Spark找到神经网络训练的最佳超参数,减少10倍的训练时间,降低34%的误差率。
- 大规模部署模型:利用Spark在大量数据上应用一个训练的神经网络模型。
训练的超参数,如每层的神经元、学习率,太多或者太少都不行。TensorFlow(开源版)本身并不是分布式的,超参数调优处理是“尴尬的并行”,可以通过Spark实现分布式,使用Spark广播常见元素如数据和模型描述,并通过支持容错的集群安排单个的重复计算。采用默认超参数设置,精度为99.2%,最好的结果为99.47%,误差率降低34%。
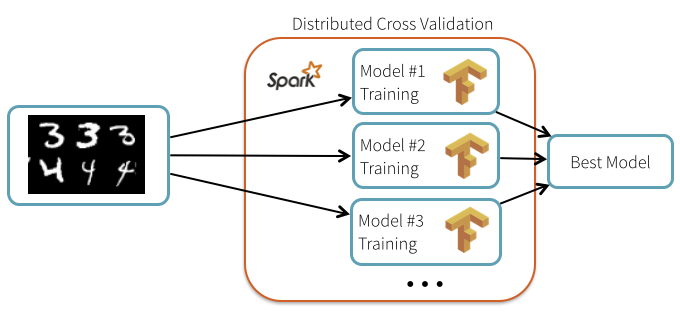
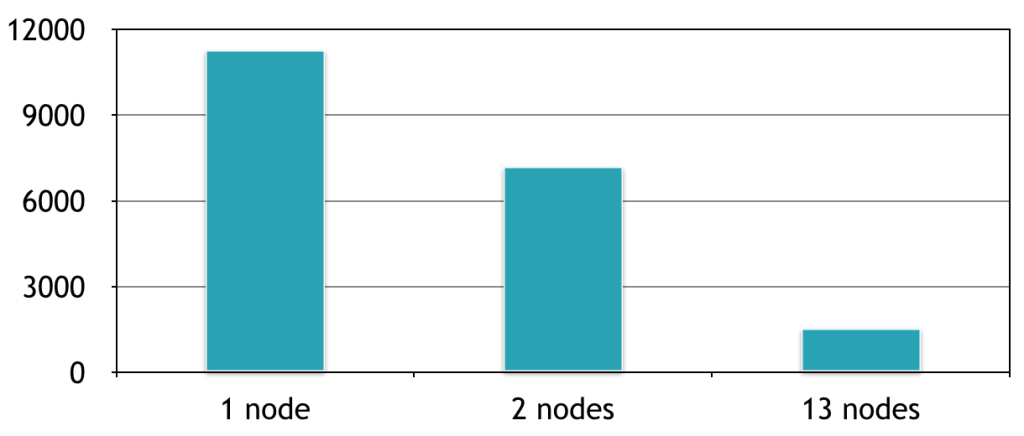
线性扩展能力,13节点的集群可以并行训练13个模型,相对于用一台机器每次训练一个模型提速7倍。
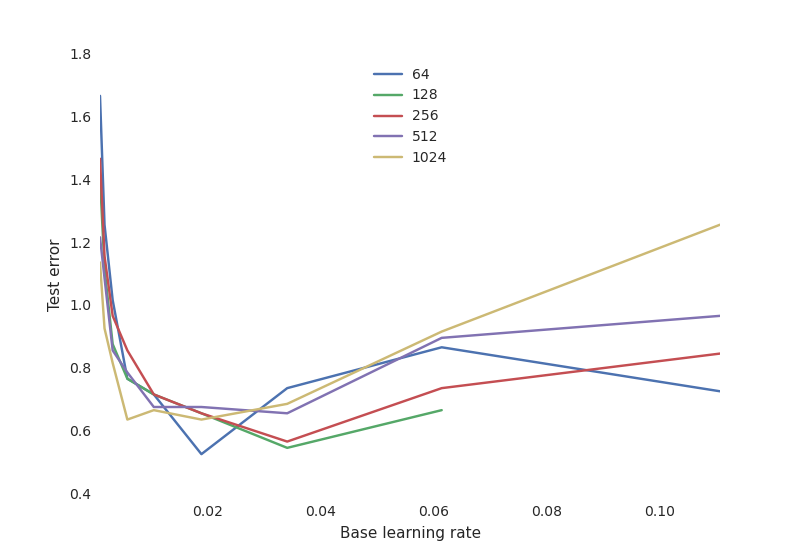
神经网络典型权衡曲线:
- 学习率非常关键,太低学不到东西(高测试误差),太高则训练过程可能随机振荡甚至在某些配置下发散。
- 神经元的数目对性能没那么重要,大量神经元的网络对学习率更敏感。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









