






论文:https://arxiv.org/abs/2003.08934
TensorFlow代码:GitHub - bmild/nerf: Code release for NeRF (Neural Radiance Fields)
PyToch代码:GitHub - yenchenlin/nerf-pytorch: A PyTorch implementation of NeRF (Neural Radiance Fields) that reproduces the results.
一、文章概述
1.问题导向
从新视点生成照片级真实感输出需要正确处理复杂的几何体和材质反射比属性。目前还没有一种方法可以生成照片级的场景渲染,传统的Sfm重建质量不够高且仅仅将照片颜色投影到模型。
2.目标
利用稀疏输入图片实现从任何视点高质量渲染场景。NeRF是一种使用神经网络来隐式表达3D场景的技术。
3D场景表征可分别为:
显式 (explicit representaion):Mesh、Point Cloud、Voxel、Volume
隐式(implicit representation):使用函数来对场景集合进行描述。

3.摘要
我们提出了一种方法,通过使用稀疏的输入视图集优化底层连续体积场景函数,实现合成复杂场景的新颖视图的最先进的结果。我们的算法使用全连接(非卷积)深度网络表示场景,其输入是单个连续 5D 坐标(空间位置 (x, y, z) 和观察方向 (θ, φ)),其输出是体积密度和该空间位置处与视图相关的发射辐射率。我们通过查询沿相机光线的5D坐标来合成视图,并使用经典的体积渲染技术将输出颜色和密度投影到图像中。由于体积渲染本质上是可微分的,因此优化表示所需的唯一输入是一组具有已知相机姿势的图像。我们描述了如何有效地优化神经辐射场,以渲染具有复杂几何和外观的场景的逼真新颖视图,并展示了优于神经渲染和视图合成先前工作的结果。
4.贡献
- NeRF首次利用5D隐式表示来最小化渲染图像和真实图像的误差
- 使用连续的5D函数(神经辐射场)表达静态场景
- 基于经典的volume rendering技术提出了一种可微渲染的过程
- 提出了位置编码(positional encoding)将5D输入映射到高维空间
5.不足
- 计算速度慢
- 只针对静态场景
- 泛化性差
- 需要大量视角
二、方法解析
2.1 系统pipeline
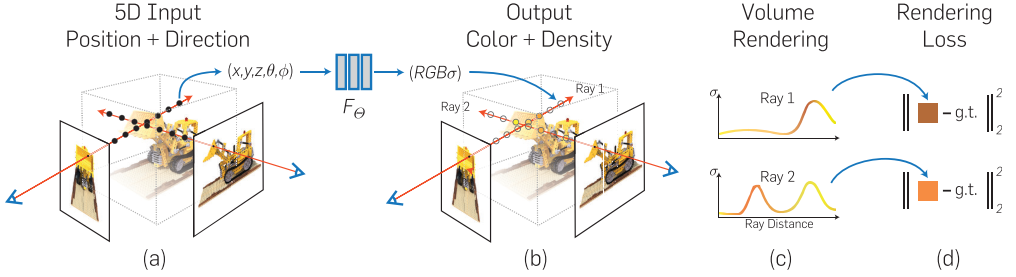
输入:(x,y,z,θ,ϕ) 3D空间位置x,y,z与2D观测方向θ,ϕ
网络:MLP
损失函数:渲染函数是可微的,最小化合成和真实观察图像之间的残差
输出:(R,G,B,σ) 预测颜色值RGB与体密度(透明度)σ
系统的详细流程如下
2.2 使用5D辐射场体渲染
朗伯定律是光学中的一个基本原理,它描述了当光线照射在理想的散射表面或者完全漫反射表面上时,出射光强度只与入射光强度和入射角有关,与观察角无关。然而,在现实生活中,许多物体并不符合这一规律。例如,镜子、金属等具有镜面反射特性的物体就会产生非朗伯效应。这也是为什么作者要构建5D的辐射场。使用经典的立体渲染方法来渲染一个光线 ray 穿过场景得到的颜色,2D视图上每一个像素颜色值都是3D场景上在该观测方向的射线上一组采样点的加权叠加。单一新视角的视图中每一个像素点的RGB值需要这一条射线上所有的采样点的(R,G,B,σ)来决定,体渲染的数学表达如下C(r)为预期颜色。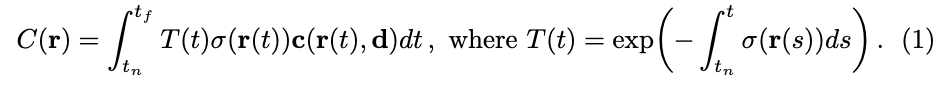



点击【文献解析】NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis——古月居可查看全文















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









