







Advance CUDA编程基础 (C++ programming)
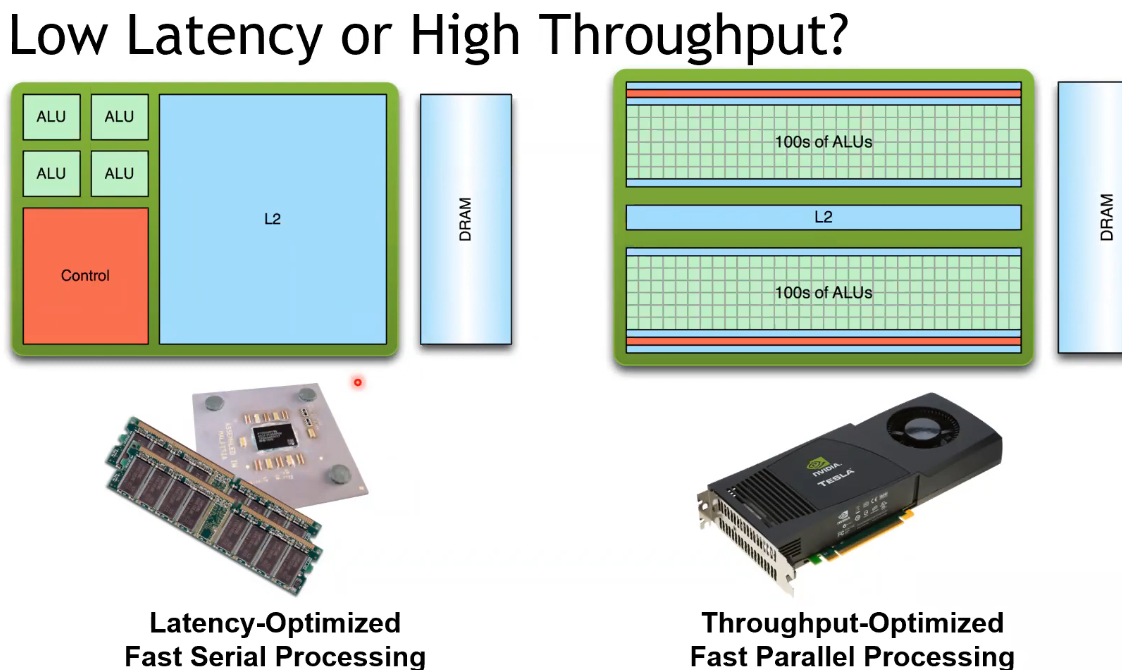
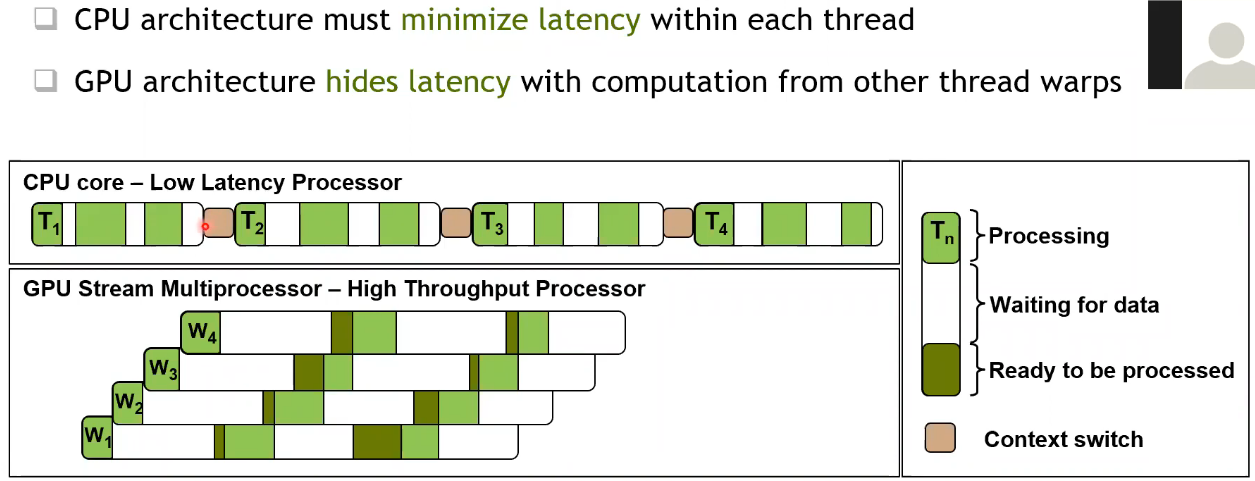
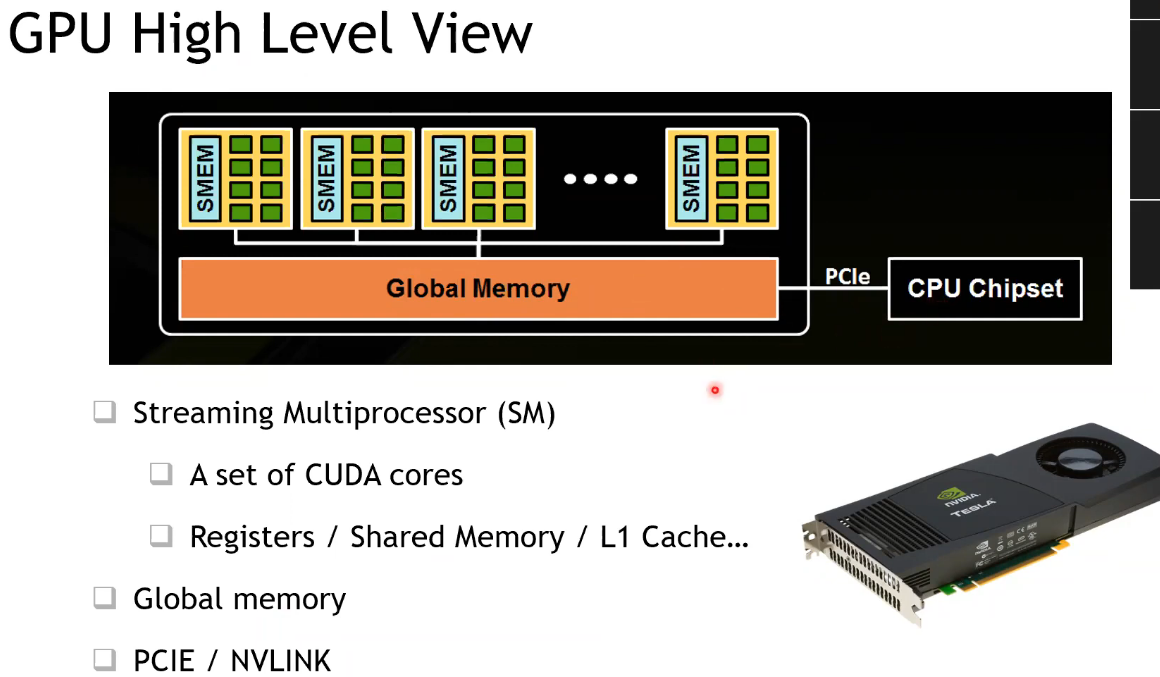
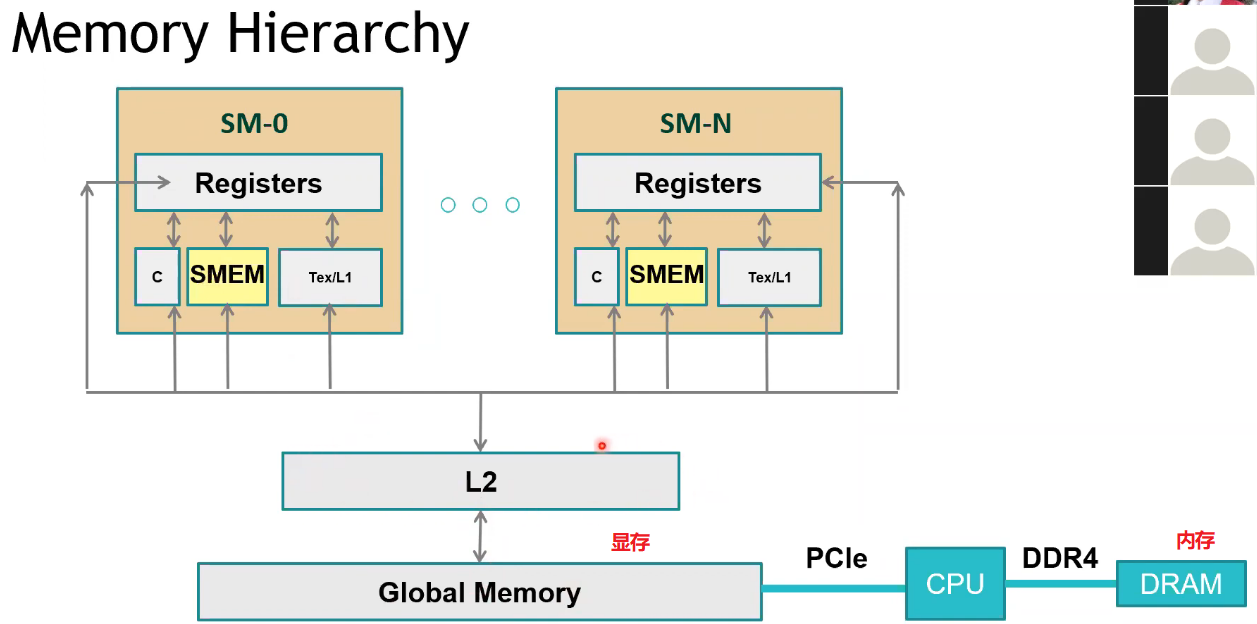
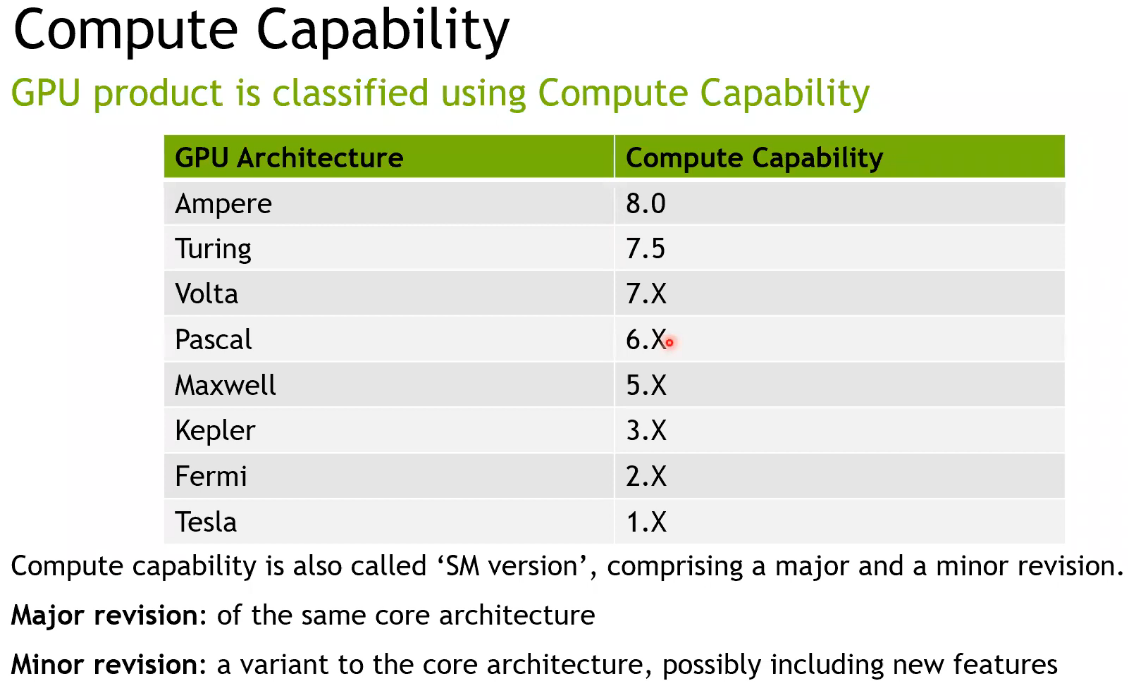
GPU 架构
CUDA 编程基础
基本代码框架
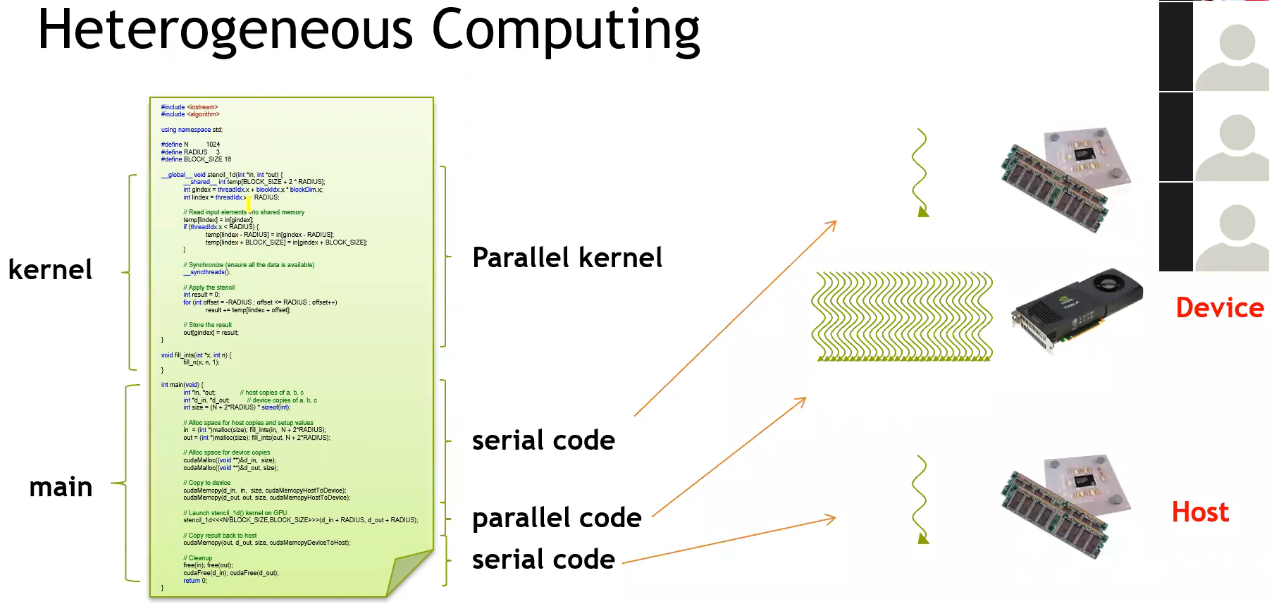
- 整个 GPU 执行 kernel 函数,多个线程执行相同代码;



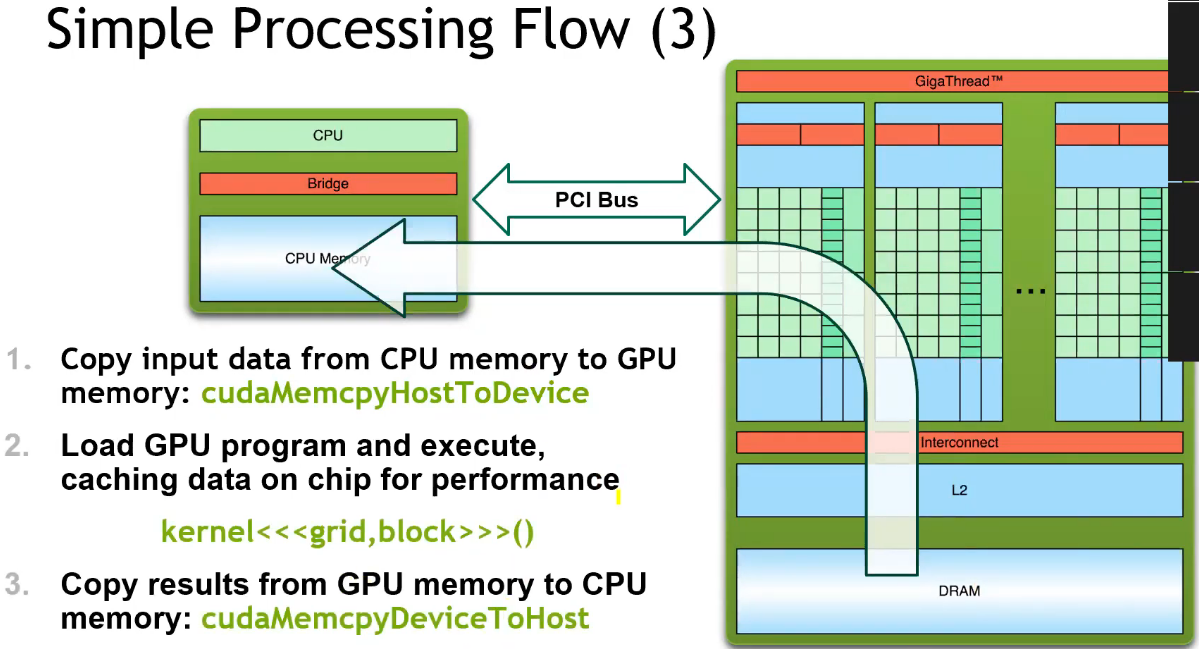
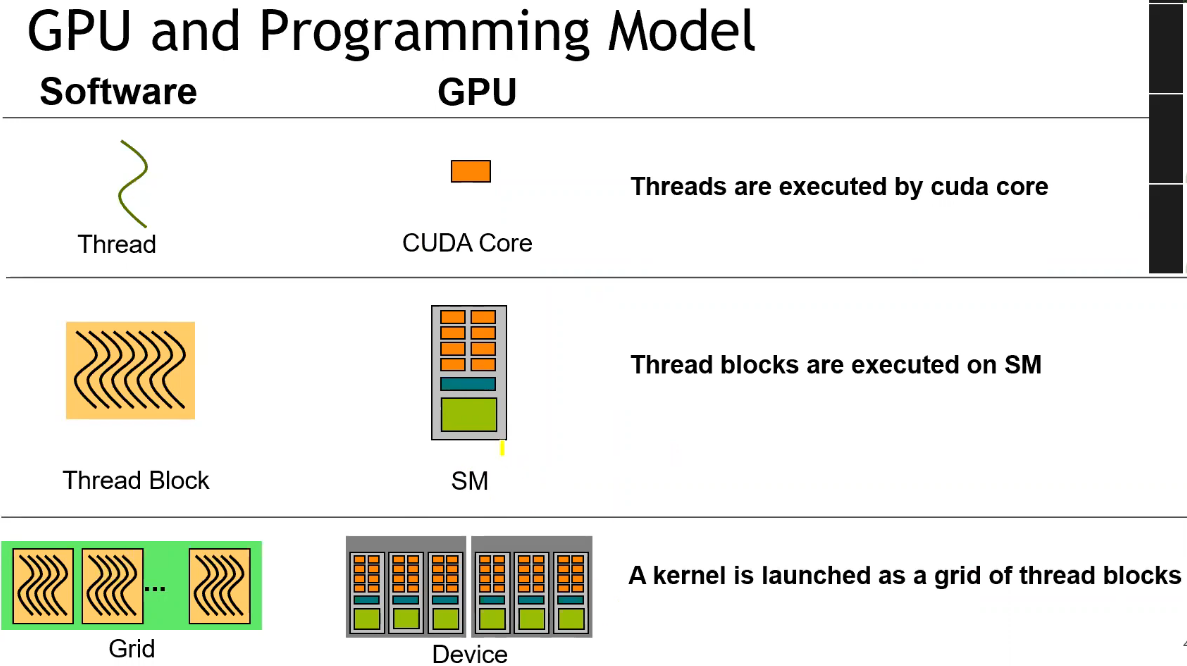
CUDA Execution Model

- 不同 Block 之间是完全异步执行的;
- 且需要通过全局的显存才能进行数据共享,因此开销较大;
- 单个 Block 内的所有线程共享单个 SM 上的共享内存,多个线程可以协作
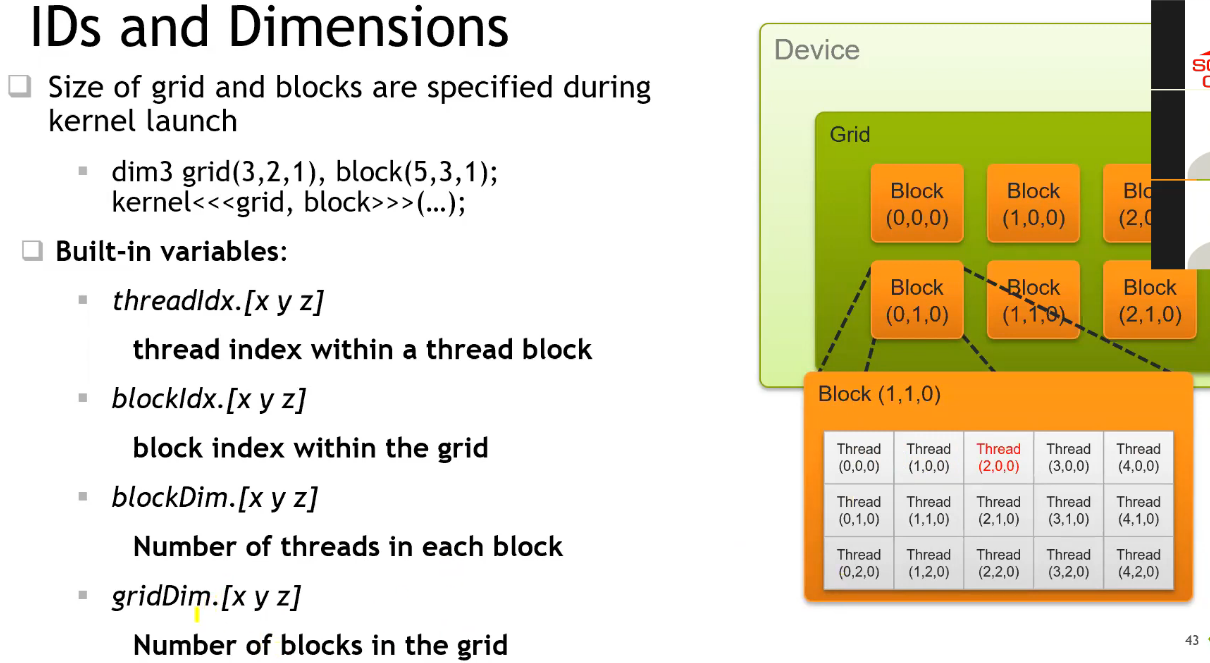
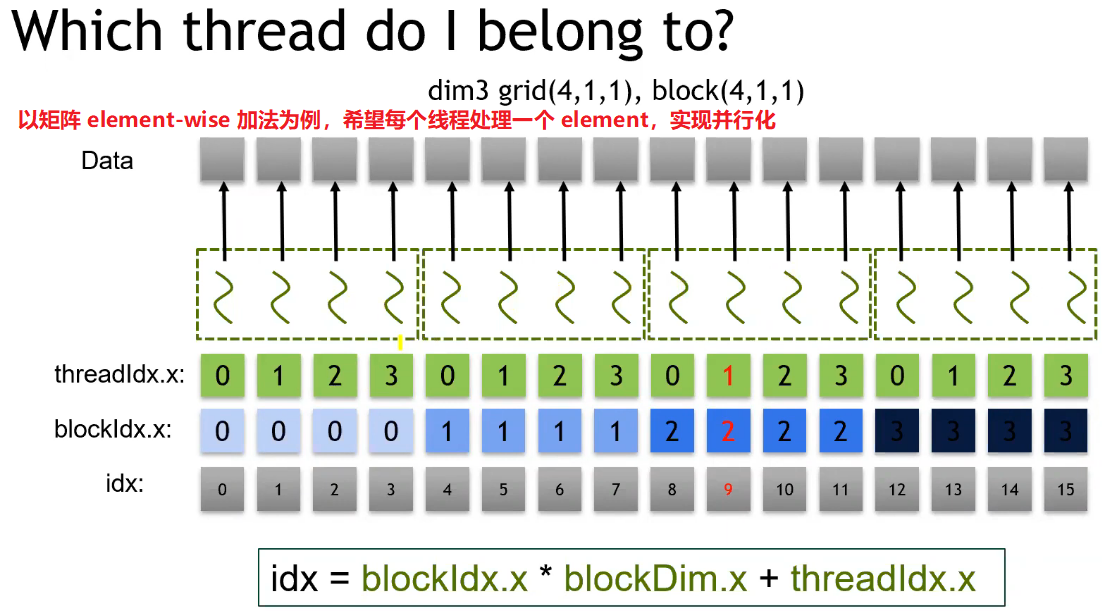
- 可通过预定义的变量获取当前线程的全局 ID;
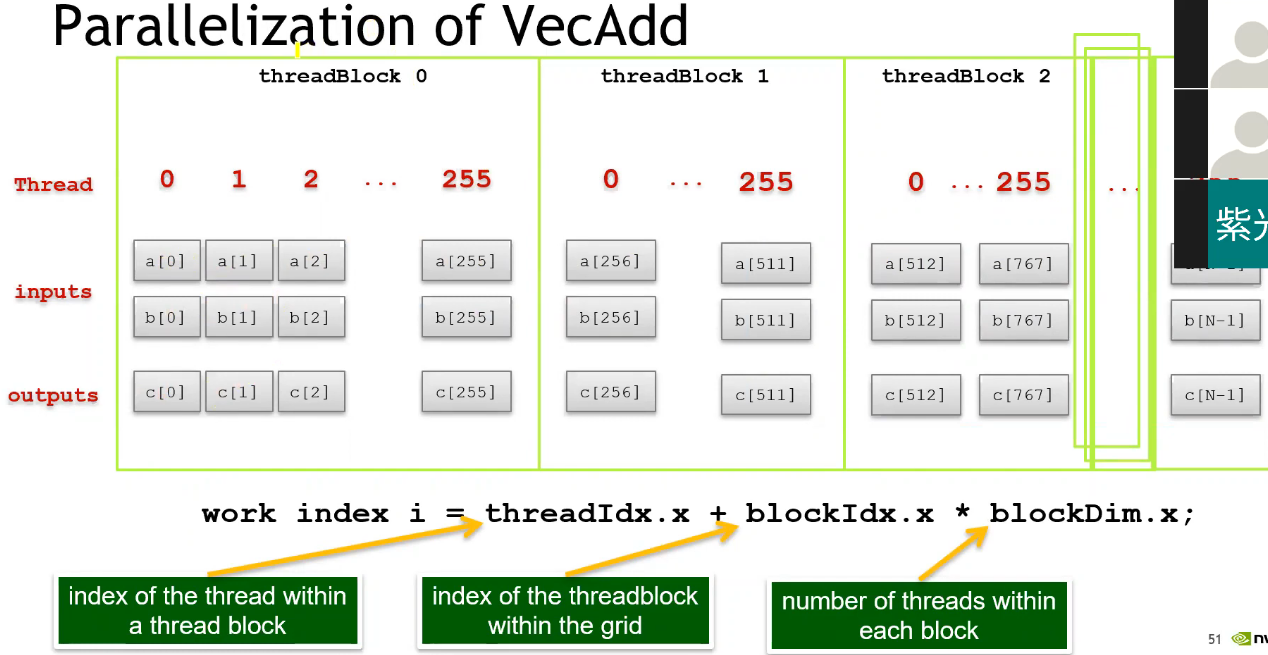
Case Study : Vector Add

- 最重要的一点是:找出程序中可以并行加速的地方!
// file: vecAdd.cu
#include <stdio.h>
// GPU kernel
// __global__ 表示:GPU 代码入口函数
__global__ void vecAdd(int N, int* lhs, int* rhs, int* out) {
int ind = blockIdx.x * blockDim.x + threadIdx.x; // 获取当前线程全局 ID
if (ind < N) // 避免多启动的线程出现内存越界
out[ind] = lhs[ind] + rhs[ind];
}
int main() {
// 初始化
const int N = 128;
int *h_lhs, *h_rhs, *h_out;
int *d_lhs, *d_rhs, *d_out;
h_lhs = (int*)malloc(N * sizeof(int));
h_rhs = (int*)malloc(N * sizeof(int));
h_out = (int*)malloc(N * sizeof(int));
memset(h_lhs, 0, N * sizeof(int));
for (int i = 0; i < N; ++i) h_rhs[i] = i;
// 分配内存
// 将修改指针的值,故为二级指针
cudaMalloc((void**)&d_lhs, N * sizeof(int));
cudaMalloc((void**)&d_rhs, N * sizeof(int));
cudaMalloc((void**)&d_out, N * sizeof(int));
// 数据拷贝至 GPU
cudaMemcpy(d_lhs, h_lhs, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_rhs, h_rhs, N * sizeof(int), cudaMemcpyHostToDevice);
// launch kernel
// <<<grid, block>>> 表示launch configuration,
// 即 grid 内的 thread blocks 数,和 thread block 内的 threads 数;
// vecAdd<<<(N + 255) / 256, 256>>>(N, d_lhs, d_rhs, d_out);
dim3 grid_conf{(N + 255) / 256, 1, 1}, block_conf{256, 1, 1};
vecAdd<<<grid_conf, block_conf>>>(N, d_lhs, d_rhs, d_out);
// 打印可能的错误信息
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess)
printf(cudaGetErrorString(err));
// 结果拷贝回 CPU
cudaMemcpy(h_out, d_out, N * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; ++i) printf("%d\n", h_out[i]);
return 0;
}
编译方法:
nvcc vecAdd.cu -o shared_memo.exe- 出现问题:
- GPU 计算结果全为 0;
- 报错:“CUDA Error:no kernel image is available for execution on device”,则说明 cuda 版本与 GPU 不匹配;
- 解决方法:
- 指定显卡架构
-arch参数:nvcc vecAdd.cu -o vecAdd.exe -arch=sm_50 -Wno-deprecated-gpu-targets
- 指定显卡架构
优化方法举例
SM 共享内存的使用
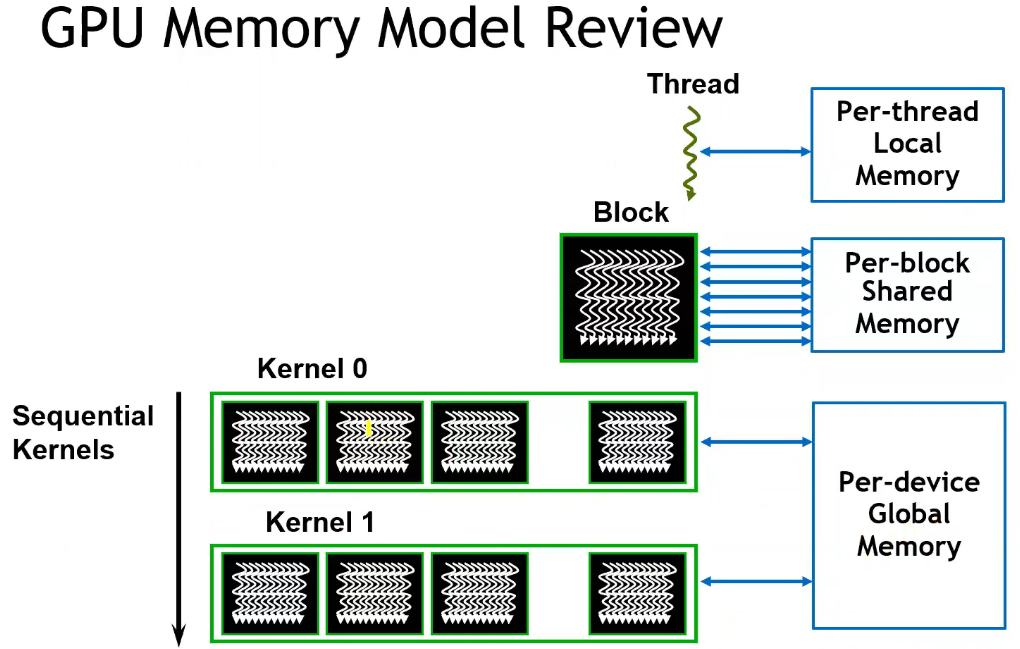
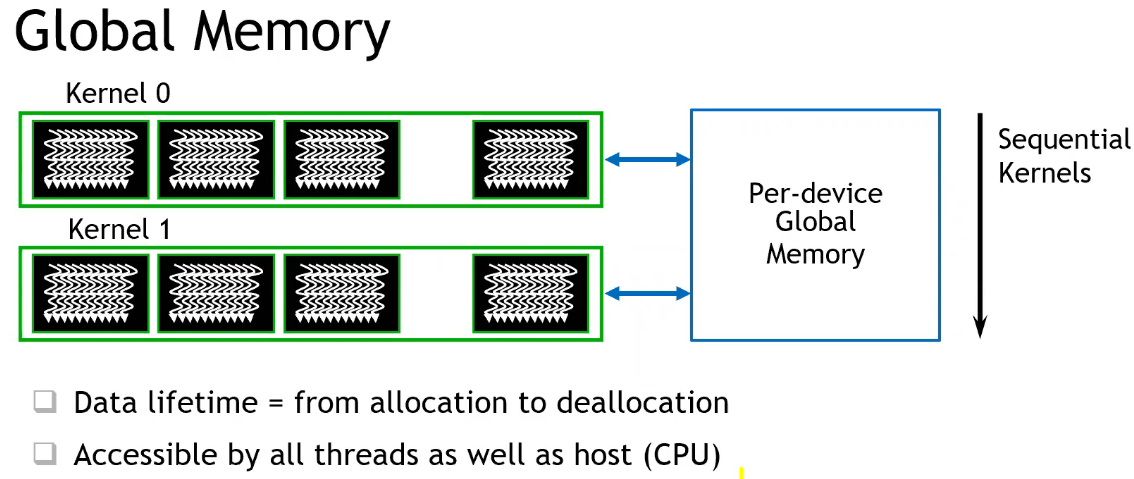
- cudaMalloc 申请在全局显存(global memory),而 Thread 的 Register 或 Block 内的共享内存,速度延迟远低于全局显存;
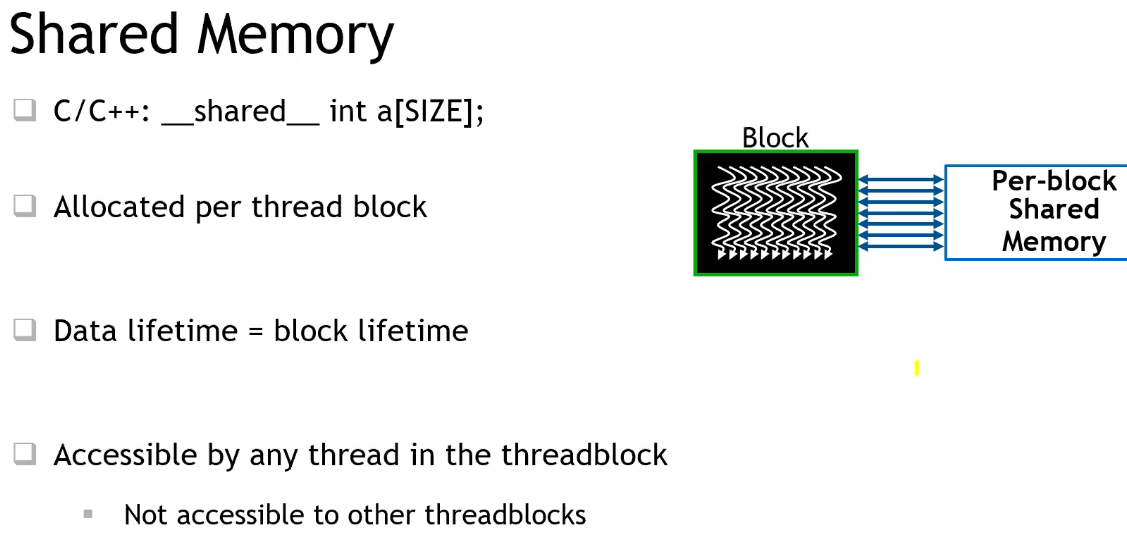
- 注意:线程块内所有线程,共享一个 shared 数组 a,而不会有多个 a;
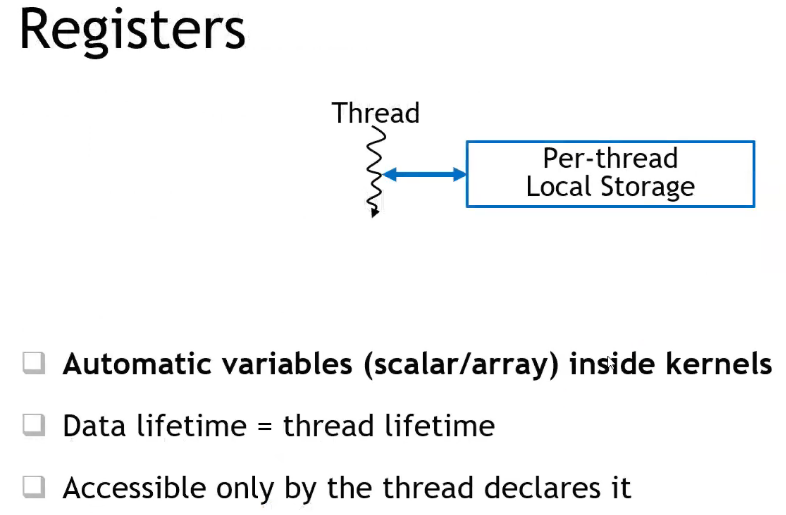
- 编译器尽可能将自动变量(标量)存储在寄存器内,而不是片外显存上的栈空间;
- 需要寻址(如索引等)的自动变量,也不能放在寄存器上;
case study :一维卷积计算
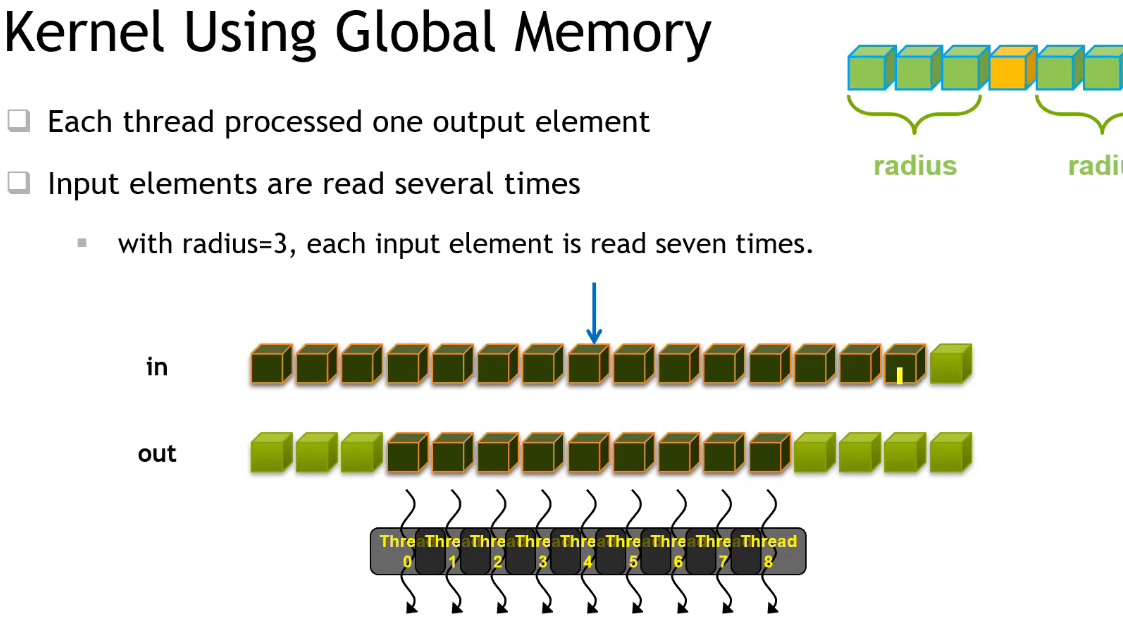
- 并行度:每个卷积结果是相互独立的,可以并行计算;
- 优化点:每个线程都需要从显存中读取 (2*radius + 1) 个数据,而所有被访问到的数据总共是 in 灰色部分,线程间存在重复读取的冗余;为提高访问速度,可以提前将单个 Block 用到的所有数据 cache 到 Block 内的共享内存中;

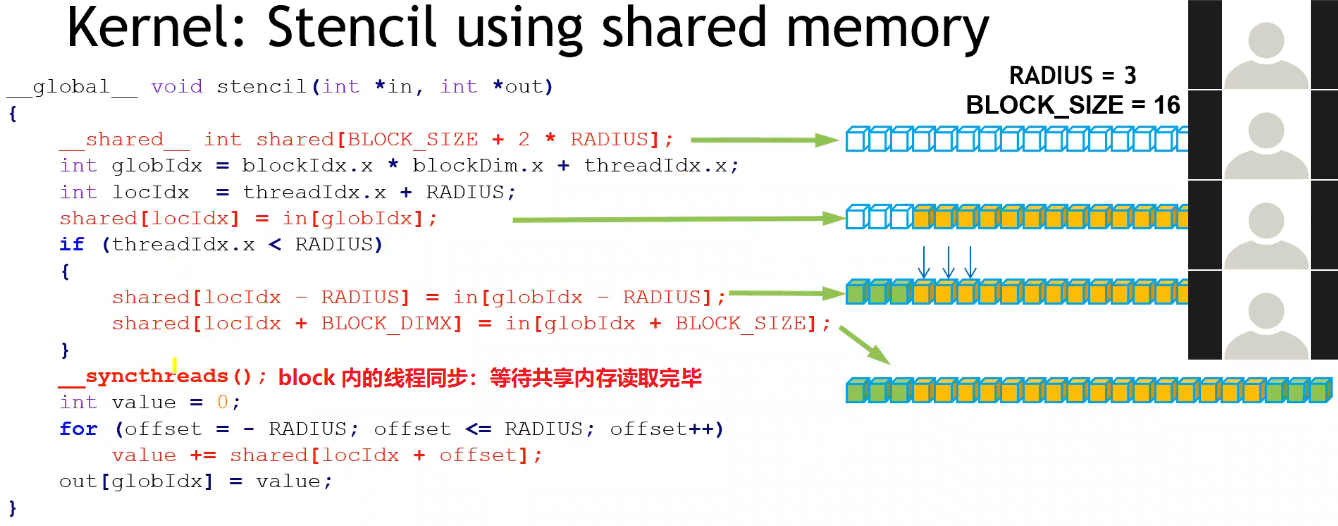

#include <stdio.h>
const int BLOCK_SIZE = 128, RADIUS = 5;
// GPU kernel
__global__ void conv_1d(int *in, int *out) {
// 单个 Block 共享内存里只有一个实例 shared,所有线程共享
__shared__ int shared[BLOCK_SIZE + 2 * RADIUS];
int global_ind =
blockIdx.x * blockDim.x + threadIdx.x; // 获取当前线程全局 ID
int local_ind = threadIdx.x + RADIUS;
shared[local_ind] = in[global_ind]; // 每个线程负责读取中心元素
// 部分线程负责读取 RADIUS 对应数据
if (threadIdx.x < RADIUS) {
shared[local_ind - RADIUS] = in[global_ind - RADIUS];
shared[local_ind + BLOCK_SIZE] = in[global_ind + BLOCK_SIZE];
}
// 需要等到 RADIUS 部分数据读完后,其它线程才能继续
__syncthreads(); // barrier,线程同步
// 计算卷积
int value = 0;
for (int offset = -RADIUS; offset <= RADIUS; ++offset)
value += shared[local_ind + offset];
out[global_ind] = value;
}
int main() {
// 初始化
const int N_VALID = 256;
const int N_TOTAL = N_VALID + 2 * RADIUS;
int *h_in, *h_out;
int *d_in, *d_out;
h_in = (int *)malloc(N_TOTAL * sizeof(int));
h_out = (int *)malloc(N_VALID * sizeof(int));
// memset(h_in, 10, N_TOTAL * sizeof(int));
// memset 逐字节赋值,只适用于 0 或 -1;
for (int i = 0; i < N_TOTAL; ++i) h_in[i] = 1;
// 分配内存
// 将修改指针的值,故为二级指针
cudaMalloc((void **)&d_in, N_TOTAL * sizeof(int));
cudaMalloc((void **)&d_out, N_VALID * sizeof(int));
// 数据拷贝至 GPU
cudaMemcpy(d_in, h_in, N_TOTAL * sizeof(int), cudaMemcpyHostToDevice);
// launch kernel
// <<<grid, block>>> 表示launch configuration,
// 即 grid 内的 thread blocks 数,和 thread block 内的 threads 数;
// 注意起始位置 d_in 偏移 RADIUS 个元素
conv_1d <<<(N_VALID + BLOCK_SIZE - 1) / BLOCK_SIZE, BLOCK_SIZE>>> (d_in + RADIUS, d_out);
// 打印可能的错误信息
cudaError_t err = cudaGetLastError();
if (err != cudaSuccess)
printf(cudaGetErrorString(err));
// 结果拷贝回 CPU
cudaMemcpy(h_out, d_out, N_VALID * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N_VALID; ++i) printf("%d ", h_out[i]);
return 0;
}
Summary
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









