







TD-MPC2简介
TD-MPC2(Temporal Difference Model Predictive Control 2)是由Nicklas Hansen、Hao Su和Xiaolong Wang等研究人员提出的一种新型模型基强化学习(Model-Based Reinforcement Learning, MBRL)算法。它在原有TD-MPC算法的基础上进行了一系列改进,旨在解决连续控制任务中的挑战。
TD-MPC2的核心思想是在学习的隐式(无解码器)世界模型的潜在空间中执行局部轨迹优化。这种方法结合了模型预测控制(MPC)的优势和强化学习的自适应性,能够有效处理复杂的连续控制问题。
TD-MPC2的主要特点
-
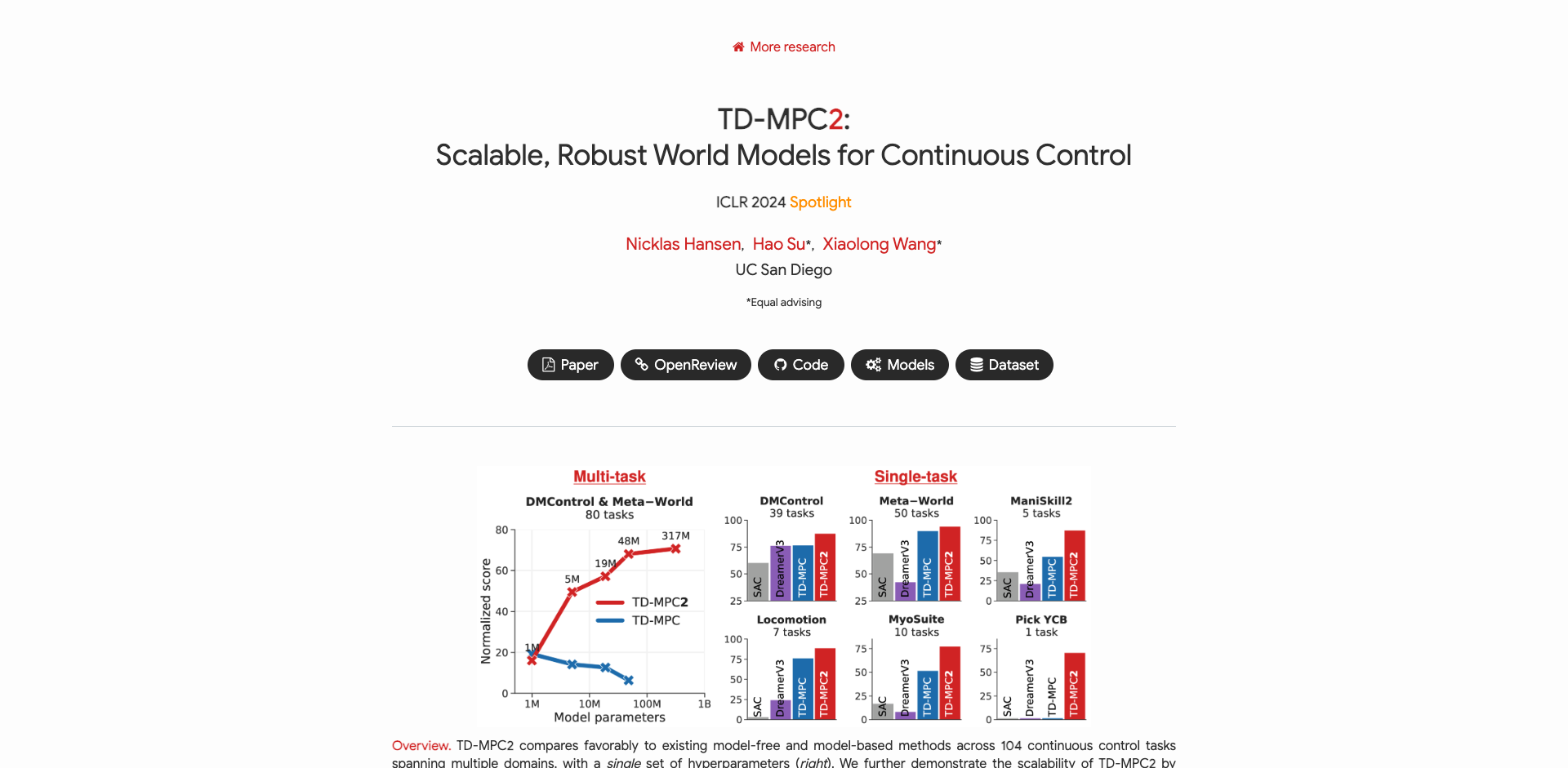
可扩展性: TD-MPC2在不同规模的任务中表现出色,从简单的控制问题到复杂的多任务场景都能应用。
-
稳健性: 该算法在多个领域的104个在线强化学习任务中均取得了显著的改进,无需针对特定任务进行超参数调整。
-
多领域适用: TD-MPC2成功训练了一个317M参数的单一模型,能够执行跨越多个领域、实体和动作空间的80个任务。
-
高效学习: 通过在潜在空间中进行轨迹优化,TD-MPC2能够更高效地学习和适应新的任务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









