







本文记录最成功的监督机器学习算法之一,支持向量机SVM(Support VectorMachines)之SMO(Sequential Minimal
Optimization)序列最小化算法算法。
过程中处了图书,参考了不少csdn博客,整理下整个过程记的理解,包括推理、迭代、代码等
1、SVM原理简述
如下图,两种类型数据点可以通过一条直线分开,叫做线性可分。如果数据点为二维分割线为一条直线,三维的一个
平面,更高维平面上就会是其他的分界表现形式,将这个分界称为超平面(hyper plane)。
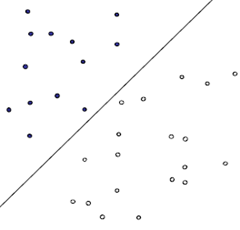
线性分类器的学习目标便是要在n维的数据空间中找到一个分界使得数据可以分成两类,即寻找最佳分隔超平面,找到离超
平面距离最近的那些点,这些点称作为支持向量,再从这些点到分隔面的距离最大化。就是寻找最佳分隔面。
分隔超平面表示为 Wtx+b=0( w为法向量,x为数据点,b为常数) 当Wtx+b >0 时对应数据类型1,Wt*x+b >0 时对应数据
类型-1,等于0时落再分隔面上不能区分了。
怎么确定最佳分隔超平面,下面以以二维平面为例,看看SVM的原理。如下图,不难发现能够实现分类的超平面(二维平面
上就是一条直线)会有很多条,如何确定哪个是最优超平面呢?直观而言,最优超平面应该是最适合分开两类数据的直线。而判定
“最适合”的标准就是这条直线距直线两边最近数据的间隔最大,也就是“使样本中离超平面最近的点到超平面的距离最远”–最大间隔。
所以,得寻找有着“最大间隔”的超平面。下面的问题是–如何求“最大间隔”

2、寻找最大间隔

在超平面wx+b=0确定的情况下,|wx+b|能够表示点x到距离超平面的远近,而通过观察w*x+b的符号与类标记y的符号是否一致
可判断分类是否正确(这是为什么类别标签采用+1和-1,而不是不是0和1的原因,除了这个下面会看到采用+1和-1后我们可以统一的
公式来表示数据点到分隔面的距离),所以,可以用(y*(w*x+b))的正负性来判定或表示分类的正确性。于此,我们便引出了函数间隔
(functional margin)的概念。
定义函数间隔为:
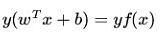
再假设
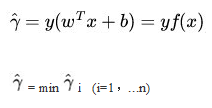
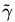 为T中所有样本点(xi,yi)中具有最小距离的数据点,而
为T中所有样本点(xi,yi)中具有最小距离的数据点,而
这些数据点也就是前面提到支持向量。为什么定义这个后面再讲。
但这样定义的函数间隔有问题,即如果成比例的改变w和b(如将它们改成2w和2b),则函数间隔的值f(x)却变成了原来的2倍(
虽然此时超平面没有改变),所以只有函数间隔还远远不够。
几何间隔
几何间隔可以|WtA +b|/||W||来表示,推导过程
假定对于一个点 x ,令其垂直投影到超平面上的对应点为 x0 ,w 是垂直于超平面的一个向量,为样本x到分类间隔的距离,如下图所示:
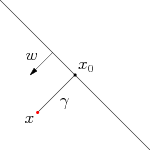
有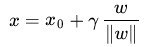 ,||w||^2=wT*w,是w的二阶泛数。
,||w||^2=wT*w,是w的二阶泛数。
又由于 x0是超平面上的点,满足 f(x0)=0 ,代入超平面的方程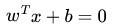 即可算出:
即可算出:
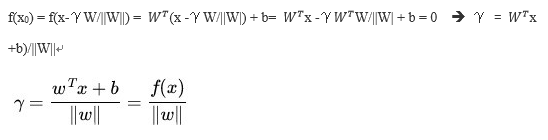
数据点到超平面的几何间隔定义为:
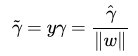
几何间隔就是函数间隔除以||w||,可以理解成函数间隔的归一化。
寻找最大间隔
找到描述超平面和数据点的间隔的公式(即几何间隔)后,我们来看寻找最大间隔优化问题。首先找到具有最小间隔的数据点,
即前面提到的支持向量,然后再这些点和超平面的间隔最大化。即:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3619
3619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









