








FreeSpace相关论文翻译,2023年最新论文。翻译,码字不易,喜欢的点个收藏,谢谢!!!!!!!
相关论文:
【freespace】YOLOP: You Only Look Once for Panoptic Driving Perception论文解读_莫克_Cheney的博客-CSDN博客
复现全纪录详见:【车道线】TwinLiteNet 复现过程全纪录_莫克_Cheney的博客-CSDN博客
目录
Abstract
语义分割是自动驾驶中理解周围环境的常见任务。可驾驶区域分割和车道线检测对于安全高效的道路导航尤为重要。然而,原始的语义分割模型计算成本高,需要高端硬件,这在自动驾驶汽车的嵌入式系统中是不可行的。提出一种可驾驶区域和车道线分割的轻量化模型。TwinLiteNet的设计成本较低,但能获得准确高效的分割结果。在BDD100K数据集上评估了TwinLiteNet,并将其与现代模型进行了比较。实验结果表明,TwinLiteNet的性能与现有方法类似,所需的计算资源明显减少。具体而言,TwinLiteNet仅用40万个参数就在可驾驶区域任务中取得了91.3%的mIoU分数,在车道检测任务中取得了31.08%的IoU分数,并在GPU RTX A5000上实现了415 FPS。
此外,TwinLiteNet可以在计算能力有限的嵌入式设备上实时运行,特别是在Jetson Xavier NX上达到60FPS,使其成为自动驾驶汽车的理想解决方案。代码:https://github.com/chequanghuy/
TwinLiteNet。
Index Terms—Segmentation, Self Driving Car, Computer vision, Light Weight model, Edge Computing
I. 简介
近年来,自动驾驶汽车已成为一个有前途的领域,可能彻底改变交通和道路发展。自动驾驶的一个重要组成部分是准确高效地感知环境。深度学习已应用于现实世界的驾驶控制任务 [1] [2]。语义分割是其中的一项基本任务,涉及为图像中的每个像素标记相应的语义类,如道路、车辆、行人等。这些信息可以帮助自动驾驶汽车安全行驶并避开障碍物。具体来说,准确检测可驾驶区域和车道标记为系统做出转向和换道决策提供了关键信息。然而,像UNet [3], SegNet [4], ERNet [5]这样的模型用于语义分割;用于车道线检测的LaneNet [6]和SCNN[7]、ENet-SAD [8];YOLOP [9], yoloopv2 [10], HybridNets[11], DLT-Net [12], Multinet [13]用于多任务问题往往具有较高的计算成本,需要高端硬件,这并不适合用于低计算功率自动驾驶汽车的嵌入式系统。
本 文 介 绍 了 一 种 轻 量 级 架 构 , 可 以 很 容 易 地 部 署在 无 人 驾 驶 汽 车 系 统 上 。 该 报 告 的 主 要 贡 献 是:(1)可驾 驶区域分割和车道检测的计算高效架构。(2)我们提出 的 基 于ESPNet [14]的 架 构 是 一 个 可 扩 展 的 卷 积 分 割网 络 , 具 有 深 度 可 分 离 卷 积 与 双 注 意 力 网 络 [15], 但我 们 的TwinLiteNet使 用 两 个 解 码 器 块 , 类 似 于YOLOP[9]。yoloopv2 [10]对 于 每 个 任 务(3)我 们 的 实 验 结 果 表明,TwinLiteNet在各种图像分割任务中以较少的参数取得了相当的性能。
本文的其余部分按以下顺序列出:我们在II部分评估了相关模型,以掌握现代模型的优点和缺点,如可驾驶区域分割、车道检测和多任务方法,以便我们可以从它们的优点中受益,并最大限度地减少我们模型的缺点。在上述分析的基础上,本文提出的TwinLiteNet在III部分中提出了一种架构,其中包含提高模型性能的方法。我们提出的模型力求在嵌入式计算机上实现快速和简单。在IV节中,我们评估了TwinLiteNet,并将其与执行相同任务的其他模型进行对比,以确定它的表现如何。最后给出了一些结论和未来的发展方向.
II. 相关工作
A. 可行驶区域分割
语义分割在计算机视觉中得到了广泛的研究,许多高效的模型已被开发用于自动驾驶或目标分割任务中的语义分割。具体来说,对于可驾驶区域的分割,最近的工作提出了高效的模型,可以以低计算成本获得准确的结果。ENet [5]是一个轻量级的CNN模型,可以在资源有限的嵌入式设备上实时运行。在研究 [16]中,作者发现使用混合扩张卷积模块可以从输入图像中提取更好的特征表
示,用于分割任务。Zhao等人 [17]设计了PSPNet模型,该模型利用金字塔池化模块(PPM)应用多个不同bin尺度的全局平均池化来提取特征。除了复杂的计算模型,Mehta等人 [14] [18]提出了低计算成本的ESPNet,使用扩张卷积来构建高效的空间金字塔(ESP)模块。除了开发和提出新的
模型外,还提出了双注意力模块 [15]以增强特征融合。
B. 车道检测
基于深度学习的车道线分割是一种实用的车道线检测方法。结合双分支特征对车道线版本进行分割。尽管耗时,SCNN [7]的卷积切片允许信息沿层内的行和列跨像素传播。另一方面,Enet-SAD [8]利用一种自注意力引导的过滤方法来辅助低级特征图从高级特征图中学习。除了细分,近年来道路标识 [19] [20]也引起了社会的广泛关注。
C. 多任务方法
多任务学习是一种同时处理多个任务的流行方法,允许模型学习共享表示并利用不同任务的共性。多任务学习的一个标准方法是使用共享的骨干网,并为每个任务单独的头。例如,Mask R-CNN [21]是一个结合了目标检测和实例分割的模型,它使用共享的骨干网并为每个任务提供不同的费用。类似地,LaneNet [6]是一种结合车道检测和车道分割的模型,使用共享骨干网和为每个任务单独的头。MultiNet [13]同时完成三项任务:自动驾驶的图像分类、目标识别和区域分割。为了促进任务之间的信息交换,DLT-Net [12]继承了编码器-解码器结构,并在特定任务的解码器模块之间建立跨模态注意力图。 [22]提出了车道区域分割和车道边界检测之间相互连接的子结构。
此外,提出了一种独特的最小化函数来约束车道边界与车道区域的几何重叠。可驾驶区域分割和车道检测都是由Hybridnets [11]使用共享编码器和三个单独的解码器完成的任务。最近,yoloopv2 [10]提出使用免费赠品袋的方法来实现高精度和快速的处理速度.
III. 所提方法
在本节中,我们将详细开发轻量级模型。首先,我们提出设计一个模型,其输入和输出如图1;TwinLiteNet由一个输入和两个输出组成,因此模型可以学习两个不同任务的表示。推荐双注意力模块来提高模型性能。此外,本节还提出了一些用于训练模型的损失函数。本文还介绍了所使用的训练和推理机制。下一节详细演示了我们提出的方法。
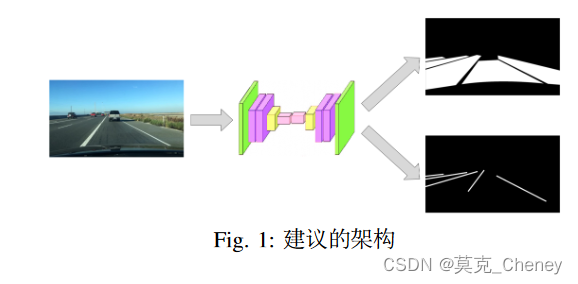
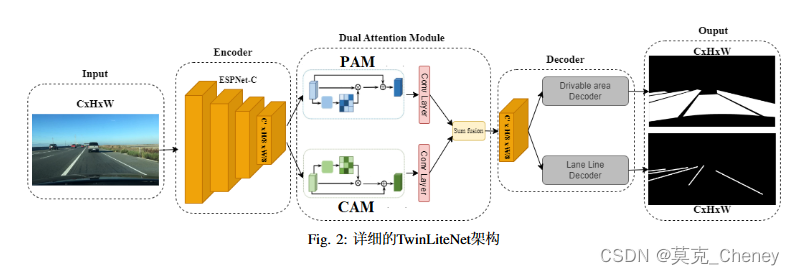
A. 模型架构
本文提出了一种为任务分割设计的低成本体系结构,称为TwinLiteNet,如图2所示。该方法利用ESPNNet-C作为信息编码块,实现了高效的特征图生成。将双重注意力模块纳入网络中,以捕获空间和通道维度的全局依赖关系。这些模块增强了网络感知上下文信息的能力。然后,将得到的特征图通过两个专用于执行两个特定任务的编码器块进行输入:可驾驶区域分割和车道检测。通过采用这种架构,旨在以较低的成本为这些任务实现准确和高效的分割结果。
首 先 , 与 使 用 骨 干 和 高 计 算 成 本 的 方 法 不 同 , 我们 利 用ESPNet的 能 力 , 具 有 低 计 算 成 本 但 高 精 度 。 我们使用ESPNet-C作为编码器,从输入图像中提取特征。在ESPNNet-C中,除了通过特征映射在ESP模块之间共享信息外,还在架构中整合模块之间不同维度的输入信息。从ESPNet-C获得特征图A ∈ RC′× H8 × W8 后,我们通过双注意力模块传递提取的特征,我们通过双注意力模块 [15]传递提取的特征。双注意力模块由位置注意力模块(PAM)和
通道注意力模块(CAM)组成。PAM模块旨在将更广泛的上下文信息合并到局部特征中,增强其表示能力。另一方面,CAM模块利用通道图之间的相互依赖关系,突出特征图之间的相互依赖关系,加强特定语义的表示。通过卷积层转换两个注意力模块的输出,并采用元素求和操作来实现特征融合B ∈ RC′× H8 × W8 。本文提出了一种用于可驾驶区域和车道分割任务的多输出设计。采用两个解码器块来处理特征图并获得每个任务的最终结果,而不是对需要分割的所有对象类型使用一个输出。我们推荐这种多输出设计的原因如下:
• 独立的性能优化:通过两个专用的输出块,我们可以独立地优化每个类的分割性能。该方法能够在不受其他类别影响的情况下,分别对可驾驶区域和车道线的分割结果进行微调和改进。 • 提高精度:使用两个输出块作为单独的层也提高了分割精度。通过独立关注每一层,该模型可以更好地学习和调整可驾驶区域和车道特有的特征,为每个类别带来更准确的分割结果。
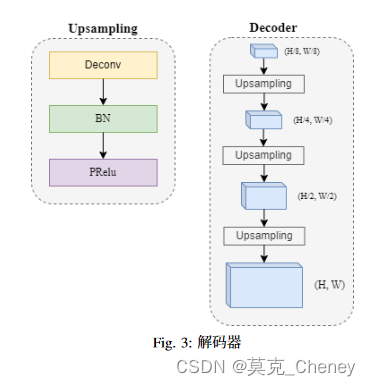
通过对可驾驶区域和车道分割任务采用两个独立输出的多输出设计,实现了每个类的独立性能优化和提高分割精度。我们的解码器模块被设计为简单但确保效率,依赖于ConvTranspose层,然后是批量归一化和pRelu [23]激活函数,如图3所示。解码后,TwinLiteNet返回两幅分割后的图像用于可驾驶区域和车道检测任务。TwinLiteNet以高精度优化了可驾驶区域分割和车道检测任务的分割性能。利用ESPNet-C和特征分析模块的双注意力网络,增强模型的特征提取能力。此外,简单的解码器块有助于降低计算成本,提高模型的效率。
B. 损失函数
我们为提出的分割模型使用了两个损失函数:Focalloss [24]和Tversky loss [25]。Focal loss旨 在 减 少 像 素 之间的分类错误,同时解决容易预测样本的影响,并对难以预测的样本进行严重惩罚,如公式1所示。另一方面 ,Tversky Loss从Dice Loss [26]中 获 得 灵 感 , 解 决 了分 割 任 务 中 的 类 别 不 平 衡 问 题 。 然 而 , 与Dice损 失 不同,Tversky损失引入了α和β参数来调整计算过程中假阳性和假阴性的重要性,如Tversky方程2所述:

C. 训练机制和推理机制
我 们 使 用 大 小 为640x360的 输 入 图 像 来 训 练 我 们的TwinLiteNet。我们使用Adam [27]优化器,其学习率随着时间的推移而下降。TwinLiteNet训练了100次,批处理大小为32。在推理过程中,采用重新参数化技术将卷积层和批量归一化 [28]层合并为单层,加快了推理速度。这个合并过程只发生在推理期间,而在模型训练期间,它们仍然作为单独的层运行:卷积和批量归一化。
IV. 实验结果
使用BDD100K [29]数据集训练和验证TwinLiteNet。它 有10个 任 务 的100,000帧 和 注 释 , 是 一 个 自 动 驾 驶 的大型数据集。由于地理、环境和天气条件的多样性,在BDD100K数据集上训练的算法具有足够的鲁棒性,可以泛化到新的设置。BDD100K数据集分为三个部分:包含70,000张图像的训练集、包含10,000张图像的验证集和包含20,000张图像的测试集。由于测试集中的20,000张图像没有标签,我们选择在一个单独的10,000张图像验证集上进行评估。在标注过程中,采用将两车道线标注信息合并为一条中心线的方法。在训练集中,我们应用膨胀操作将注释扩展8像素,同时保持验证集不变。此外,我们将BDD100k数据集中的图像从1280 × 720 × 3调整到640
× 360 × 3。本研究中描述的预处理步骤根据 [8]进行。
所有实验都是在带有32GB RAM和Intel(R) Core(TM)i9-10900X处理器的NVIDIA GeForce RTX A5000 GPU上使用PyTorch框架进行的.
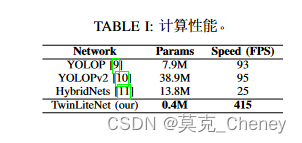
A. 成本计算性能
表I将提出的模型与其他多任务网络1进行了比较。我们的TwinLiteNet只有0.4M参数,比之前的模型低得多。此外,TwinLiteNet达到了415FPS,而其他模型在相同的测试设备上仅实现了低于100FPS的推理速度。
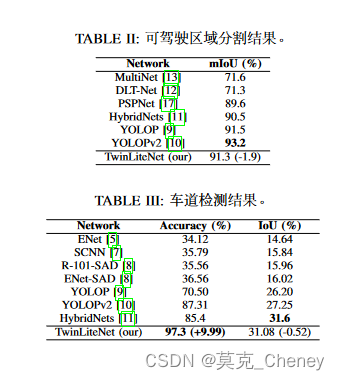
B. 可驾驶区域分割结果
本 文 将BDD100K数 据 集 中 的“可 驾 驶 区 域”和“备选 区 域”都 转 换 为“可 驾 驶 区 域”。 使 用 平 均 交 并比(mIoU)指 标 来 评 估TwinLiteNet的 分 割 性 能 。 结 果 如表II所 示 。 尽 管TwinLiteNet的 准 确 率 高 于 之 前 提 出 的一 些 模 型 , 但TwinLiteNet略 低 于 当 前 最 先 进 的(SOTA)yoloopv2(-1.88%)和YOLOP(-0.18%)。这很容易理解,因为TwinLiteNet是 为 了 优 化 推 理 时 间 而 不 是 准 确 性 而 开发 的 。 该 模 型 的 部 分 分 割 结 果 如 图4a所 示 。 结 果 展 示
了TwinLiteNet在不同照明条件下完成任务的令人印象深刻的性能,包括白天和夜间的场景。值得注意的是,该网络在分割可驾驶区域方面表现出很高的准确性,同时有效避免与对面车道混淆。
C. 车道线检测结果
BDD100K数据集中的车道线使用低像素厚度的线条进行标记。采用像素精度和车道线交并比(IoU)作为评价指标。如表III所示,TwinLiteNet在IoU(-0.52%)方面仍然低于目前的SOTA HybridNets,但TwinLiteNet的准确率达到97.3%,远高于目前的模型。该模型的部分分割结果如图4b所示。实验结果表明,所提出模型对多车道道路表现出强大的预测能力,在白天和夜间场景中表现出色。这一观察结果强调了该模型在不考虑光照条件的情况下准确预测车道配置的能力。
D. 消融研究
在本节中,我们研究消融研究。我们提出的消融选项及其相应结果如表IV所示。评估了一个简单基线的结果,该基线只包括主干和作为车道检测的整个可驾驶区域的一个输出。然后逐步添加双注意力模块、多个头和重新参数化方法。结果表明,在基线模型下,我们达到了530FPS的最高推理速度,但与完全集成的模型相比,以牺牲很大的精度为代价,后者达到了415 FPS的推理速度。
E. 边缘设备
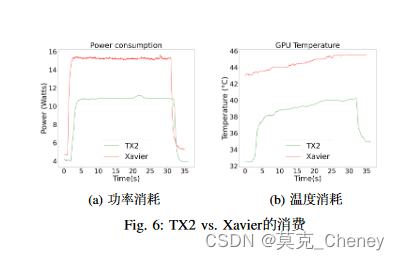
本节展示了在嵌入式设备上部署我们的TwinLiteNet模型的推理速度结果,特别是NVIDIA Jetson TX2和JetsonXavier NX。我们使用TensorRT SDK在这些Jetson设备上执行模型推理。实验结果表明,TwinLiteNet模型在边缘设备上实现了实时计算,其中Jetson Xavier NX达到了60 FPS的帧率,Jetson TX2达到了25 FPS。为了评估我们模型的性能,我们使用来自BDD100K数据集的测试视频在边缘设备2上记录了预测过程,一些可见结果如图5所示。这些结果表明,TwinLiteNet模型在各种嵌入式设备上都实现了对白天和夜间图像的准确预测。
此外,我们在嵌入式设备上监测了TwinLiteNet模型的功耗和工作温度。图6a说明了记录的功耗,图6b描述了在提出的边缘设备上推理期间模型的工作温度。这些测量为TwinLiteNet模型在现实部署场景中的能效和热性能提供了见解。
V. 结论
本 文 为 自 动 驾 驶 任 务 提 出 一 种 轻 量 级 和 节 能 的 分割模型,特别是可驾驶区域和车道检测。TwinLiteNet的目 标 是 在 精 度 略 有 权 衡 的 情 况 下 实 现 高 处 理 速 度 。对BDD100K数据集的评估表明,该模型在gpu甚至边缘设备上的精度和高计算速度之间取得了很好的平衡。未来,我们打算评估TwinLiteNet模型在各种公开数据集上的性能,并将该模型应用于现实世界的场景。这种方法使我们能够评估其在不同背景下的有效性,并解决实际挑战。
















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









