






服务器配置
老板给了一张RTX 2070Ti的显卡,有11GB左右的显存,故选择使用1.8B(3B、5B不知道会不会报什么奇怪的错误,暂时先不尝试了)+Qlora
1、登上服务器后发现CUDA版本12.4,挺高的好像,不知道后面会不会出现什么问题,先不管了,nvidia-smi看一下显卡状态,四张卡,只有一张空着,先用着吧,能跑通再说(关于显卡的介绍链接)。
2、先用conda create -n QwenQlora ,再conda activate QwenQlora
0帧起手一个conda install python 然后发现下载版本3.13.1,随后在conda install pytorch的时候出现版本太高没有适配的python 于是 conda uninstall python(其中试了一下pip uninstall 居然卸不掉,有生殖隔离吗???),由于网太差第二次下载中断,于是准备找镜像
可以使用下面的代码来指定镜像网站,或者第二种方法永久配置镜像网站
conda install -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free package_nameconda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/在Anaconda中,当显示“Executing transaction: done”并且没有错误信息时,通常表示包已经成功安装。如果您需要确认包是否安装成功,可以在Anaconda Prompt或者终端中使用conda list命令来查看已安装的包列表,确认openssl是否已经更新到您需要的版本。
根据这个错误信息,主要问题如下:
a. 连接中断:在尝试收集包元数据时,连接被远程端关闭,导致连接中断。
b. 包找不到:以下包在当前渠道中不可用:
- transformers_stream_generator==0.0.4
- tiktoken
- einops
- accelerate
c. 当前渠道:当前使用的渠道是清华大学镜像和Anaconda官方渠道。
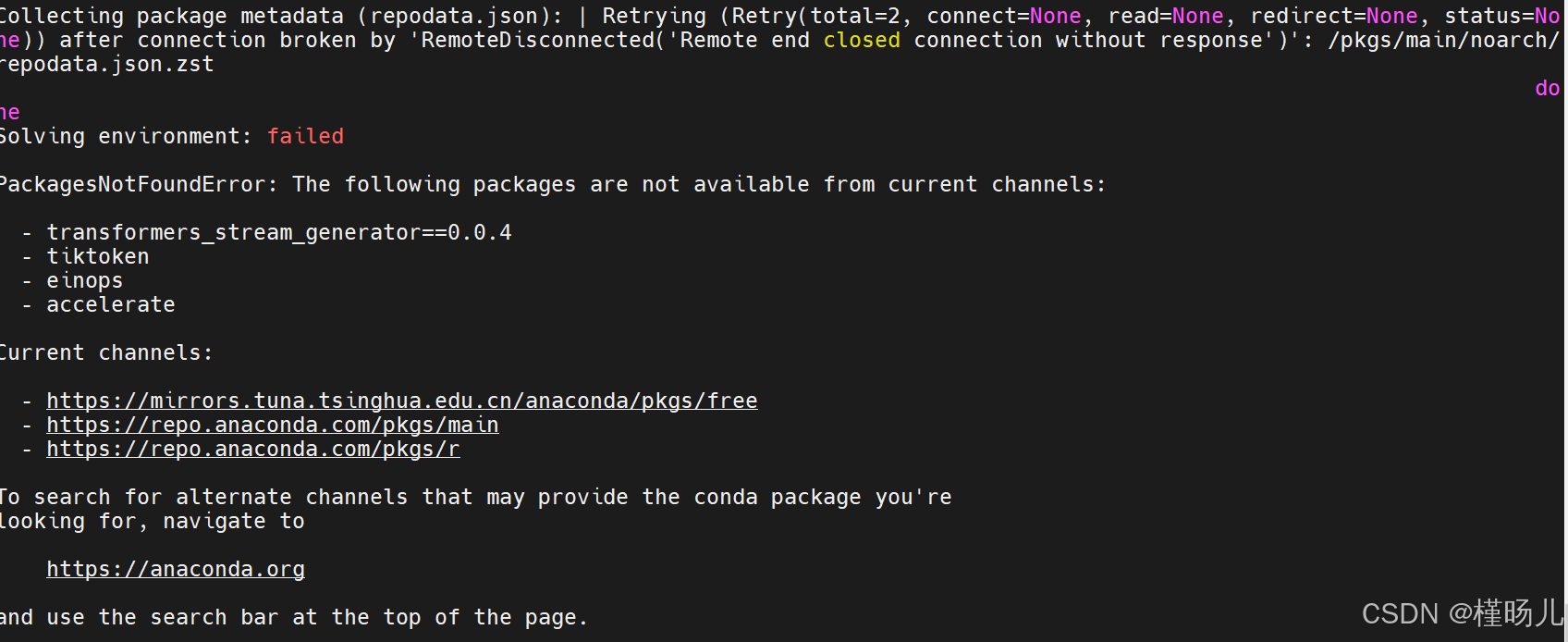
不知道为啥这几个包总是找不到,第一阶段先到这里吧,真的下不下来包。。。
昨天真的下破防了,今天再战:
还是下不下来包,于是发现python版本是3.6,这是因为在新建环境时没有指定python版本,所以新开了一个环境,重新下载,这次连torch也下不下来了,问了kimi说这个代码可以自动处理依赖,需要把后面的cu113换成自己nVidia显卡对应的cuda版本,然后正常运行,叽里咕噜下来一大堆东西,刚开始下的时候很快,后面就很难,扫了一眼有什么pillow,numpy的,想复制一下包名结果以外中止了程序。。。numpy没下下来。。。也不知道会不会给后面埋雷,不管了!
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113既然已经中断,那么就添加两个channels,然后查看一下现在有哪些网站吧,估计没使用./condarc文件内的镜像网站:

使用conda install是希望可以自动地解决依赖冲突问题,
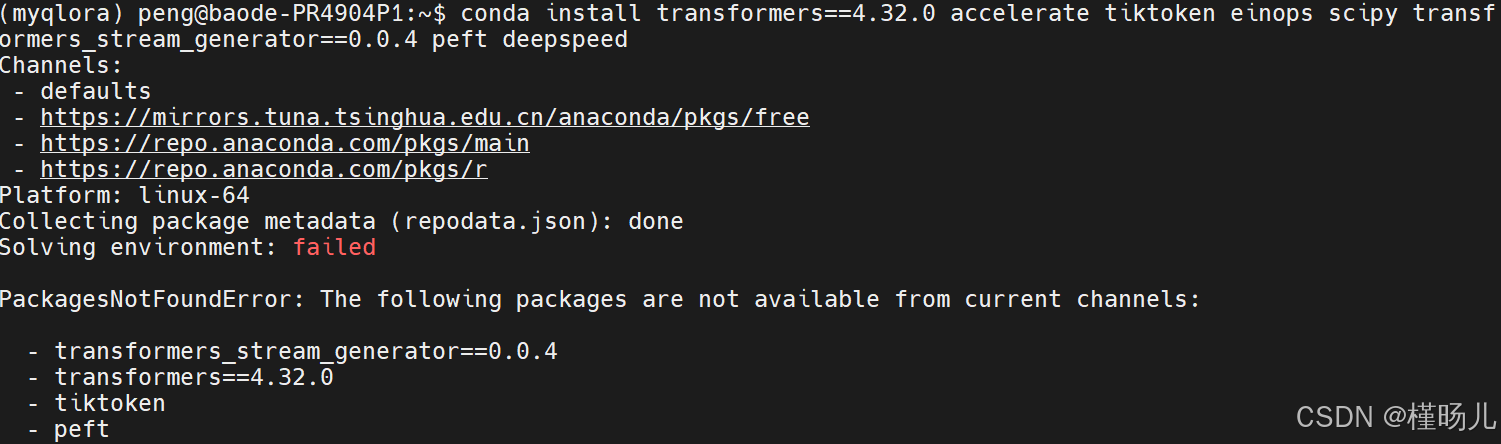
结果还是相同的错误,然后问了一下kimi,解释说
- 有些包可能不在默认的 conda 通道中。您可以尝试添加额外的通道,例如 conda-forge,它提供了许多 conda 官方通道中没有的包。
- 如果 conda 无法找到这些包,您可以尝试使用 pip 来安装。pip 是 Python 的另一个包管理器,通常能找到更多的包。
确实,使用pip后可以安装了,但是速度真的太慢了。。。咱也一动不敢动了
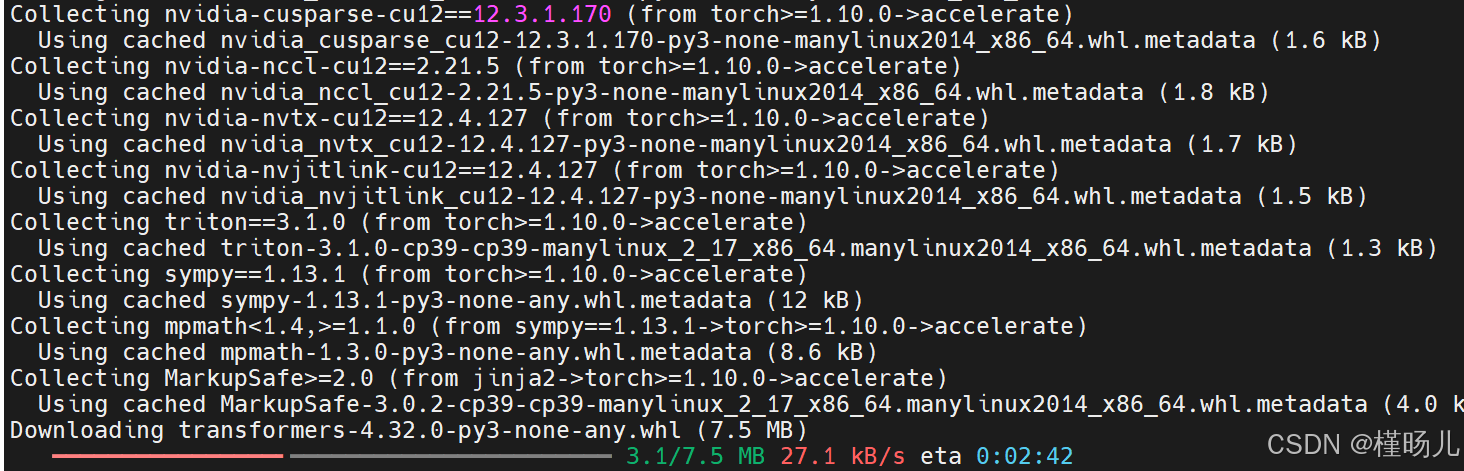
1、下载过程是先下载xxxx.wheel.meta文件,然后再下载wheel文件,真的太慢了,不知道猴年马月才能下完
2、之前下载下nvidia匹配版本驱动(或许不是驱动)的时候有一些cache可以用,但是都是小的metadata,真的,下载太慢了,不知道是什么原因
因为太慢而网络中断,后来意识到是conda之前配置了镜像,但是pip没有配置,所以ctrl+c中断然后执行以下代码
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
这是一种临时使用,如果想永久配置可以使用如下代码配置一个镜像网站
# 永久配置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple对于flash attention这个包的下载出现以下报错

解决方法是使用
pip install flash-attn --no-build-isolation其中
--no-build-isolation:
- 这是一个 pip 的可选参数,用于控制构建过程中的隔离行为。
- 默认情况下,pip 会使用构建隔离(build isolation),这意味着 pip 会在一个临时目录中构建包,以避免污染全局环境。
- 使用 --no-build-isolation 选项会禁用这种隔离,允许 pip 在当前目录下构建包。这可能会使得构建过程更快,因为避免了创建和删除临时目录的开销。
- 但是,这也意味着构建过程中产生的文件会留在当前目录,可能会留下一些构建垃圾。
但素嘞,过程中又报错啦
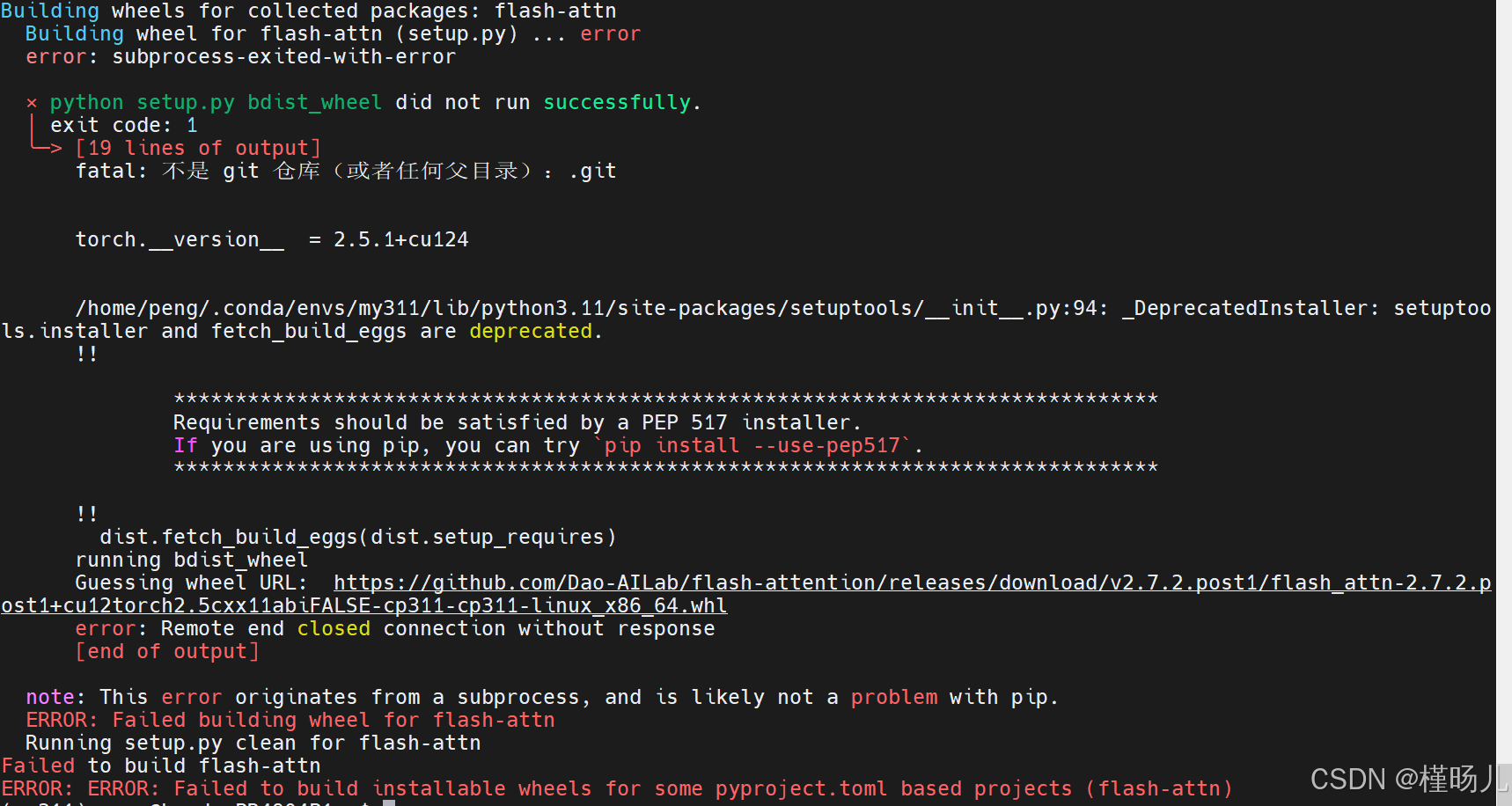
kimi给出的错误原因是
安装环境问题:
- 确保您的Python环境是激活的,并且是您想要安装flash-attn的环境。
- 检查您的pip版本是否是最新的,可以通过运行pip install --upgrade pip来更新。
依赖问题:
- 错误信息中提到torch.__version__= 2.5.1+cu124,确保您的PyTorch版本与flash-attn兼容。可能需要安装与flash-attn兼容的PyTorch版本。
使用PEP 517安装器:
- 错误信息建议使用PEP 517安装器,您可以尝试使用pip install --use-pep517 flash-attn来安装。
直接下载wheel文件:
- 错误信息中提到了一个wheel文件的URL,您可以尝试直接从该URL下载wheel文件并使用pip安装:
pip install [URL]- 请替换[URL]为实际的wheel文件URL。
环境变量问题:
- 错误信息中提到fatal:不是 git仓库(或者任何父目录):.git,这可能意味着您当前的工作目录不是一个Git仓库。确保您在正确的目录中运行命令,或者初始化一个Git仓库。
权限问题:
- 如果您在安装过程中遇到权限问题,尝试使用sudo(在Linux或macOS上)或以管理员身份运行命令提示符(在Windows上)。
个人判断问题出现在第二步,然后根据报错信息中给出的网站这个是wheel包,针对特定linux版本的,在windows浏览器中打开发现是一个以whl为后缀的包,所以决定尝试在linux终端下载这个wheel文件,因为没有看到pip好像也能直接下载,所以使用了wget
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.2.post1/flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
注意,我使用wget下载时是先进入了library目录下才wget的
接着使用,pip install 安装,最终successfully了!不容易!
pip install flash_attn-2.7.2.post1+cu12torch2.5cxx11abiFALSE-cp311-cp311-linux_x86_64.whlSuccessfully installed flash-attn-2.7.2.post1
明天todo:
1、去github上找一个微调部分的代码修改
2、确定使用1.8-chat了,因为只有chat可以Qlora
3、看一看是不是自动匹配可用gpu的数量的,如果不是要判断一下老师给的卡能用单gou还是多gpu,能不呢用accelerate库自动识别
4、tensorboard和accelerate怎么连能够记录除了trainingloss以外的数据,比如accuracy、peperlixity等等
5、看看代码,包括finetuning和eval,这次主要不是看懂而是需要跑通。
在构造好数据后开始bash fintuning的时候报错,出现了各种各样的依赖问题,整了半天突然想起来官方markdown提醒的cuda tooklit,发现好像真是这玩意儿的问题,所以根据这个文档完成了不需要权限的安装,但是sh跑完后没有出现和博主一样的驱动安装窗口,所以又停歇了
https://blog.csdn.net/K_wenry/article/details/138350564
12月16日
又开启了,这次直接跑ds.sh报错没有torchrun(用于分布式训练)这个块,然后我说那好吧那我跑siglegpu这块,然后报错没有torch.utils.data这个块,这两个好像都指向一个问题——torch版本不匹配,先使用如下代码检查
python -c "import torch; print(torch.__version__)"报错import不进来torch,然后使用如下代码,显示torch是正常安装的
pip list | grep torchrun(my311) peng@baode-PR4904P1:~/Qwen/finetune$ pip list | grep torch
torch 2.5.1+cu124
torchaudio 2.5.1+cu124
torchvision 0.20.1+cu124根据您提供的
pip list命令的输出,您已经成功安装了 PyTorch 2.5.1 版本,这个版本是为 CUDA 12.4 构建的。同时,您也安装了与之配套的torchaudio和torchvision,它们也都是为 CUDA 12.4 构建的。如果您遇到了
ModuleNotFoundError: No module named 'torch.utils.data'这样的错误,这通常意味着 Python 解释器无法找到已安装的 PyTorch 模块。这里有几个可能的原因和解决方法:
环境问题:确保您在激活了正确虚拟环境的情况下运行您的 Python 脚本。您的虚拟环境名称是
my311,所以您需要确保在运行脚本之前已经激活了这个环境。Python 版本问题:虽然您的 PyTorch 版本是 2.5.1,但是您需要确保您的 Python 版本与 PyTorch 兼容。PyTorch 2.5.1 支持 Python 3.9、3.10、3.11、3.12 和 3.13。如果您的 Python 版本不在这个范围内,您可能需要安装一个兼容的 Python 版本。
路径问题:确保您的脚本没有指定错误的 Python 解释器路径。如果您的虚拟环境中的 Python 解释器路径不是默认的,您可能需要在脚本中明确指定正确的路径。
重新安装 PyTorch:如果上述步骤都无法解决问题,您可以尝试重新安装 PyTorch。使用以下命令:
bash
pip uninstall torch torchaudio torchvision pip install torch==2.5.1+cu124 torchaudio==2.5.1+cu124 torchvision==0.20.1+cu124
但其实这个pip install是不正常的,因为pip里没有办法与cuda版本对应的,这时kimi提醒会不会是包没有下载完全,我有点懵,于是爬回去重新下载了一下
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
能跑一点了,就是会报一些import erro,它报,那我就下,然后惊觉忘记改博主的cuda版本了,我现在最高版本是12.4.0,那应该下11.3也行吧,说不定qwen就吃11.3呢,
python -c "Pyhton 代码"get一个新技能可以在cmd中简单跑一个python代码
接下来报错triton中没有jit这个属性,经过kimi解答了解到可能是和deepspeed版本冲突,于是开启了三install三uninstall deepspeed,由于依赖问题没有办法下载低版本deepspeed,所以选择升级triton,嘿,问题还真就解决了,同时又报错有关numpy语法的错误,也是通过升级numpy完成了
接下来又一个头疼的报错
safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLargekimi误判flashattention的问题,用官方文档中的内容重新下载flashattention发现没有什么区别。。。
目前有两种解决方案,首先尝试了第一种,说是可能用git下载的大文件不完整,选择使用modelscope再下载一次:
我先简单记录一下模型的下载地址:/home/peng/.cache/modelscope/hub/Qwen/Qwen-1_8B-Chat
好嘞,第一种方法成功解决!记录一下第二种吧,万一下次是第二种呢呸呸呸如何完美解决ERROR: safetensors_rust.SafetensorError: Error while deserializing header: HeaderTooLarge-腾讯云开发者社区-腾讯云
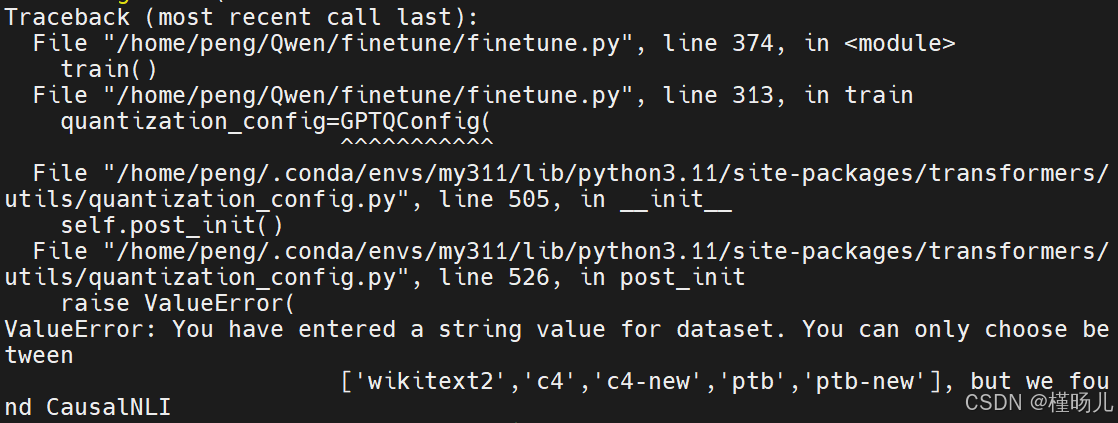
在准备finetune的过程中出现了一个有关于量化的报错,提示量化时需要指定数据集,本来输了自己本地的数据集,以为单纯使用自己的数据集进行量化,结果报错并提示只能使用给定的量化数据集,于是学习了一下什么叫做量化数据集:
在量化过程中,所需的量化数据集通常被称为校准集(Calibration Set)。以下是关于量化数据集的一些关键信息:
1. **校准集的作用**:
- 在后训练量化(Post-Training Quantization, PTQ)中,校准集用于确定量化因子,这些因子用于将模型的权重和激活值从浮点数转换为低精度的表示。校准集帮助模型在量化后保持尽可能接近原始模型的性能。2. **校准集的大小**:
- 校准集的大小可以根据模型的复杂性和数据的多样性来确定。一般来说,校准集应该足够大,以覆盖模型在实际使用中可能遇到的各种情况,但又不至于大到消耗过多的计算资源。3. **校准集的选择**:
- 校准集通常从训练集或验证集中选取,或者是这些集合的子集。它们应该具有代表性,能够反映模型在实际应用中会遇到的数据分布。4. **数据集蒸馏量化技术**:
- 某些量化技术,如数据集蒸馏(Dataset Distillation),通过压缩大量数据集的知识到少量合成数据上,提升了模型训练效率。这些合成数据在保持模型性能的同时,极大地减少了训练所需的数据量。5. **数据集量化(DQ)**:
- 数据集量化是一种将大规模数据集压缩成小子集的新框架,可用于训练任何神经网络架构。这种方法通过最大化子模块增益将数据集划分为几个不重叠的 bin,然后从这些 bin 中均匀采样集成核心集进行训练。6. **量化方法**:
- 在量化过程中,可以选择不同的量化方法,如KL散度(KL)或直接量化(direct),这些方法会影响校准集的量化因子计算。7. **量化的应用场景**:
- 量化技术在大规模向量检索、深度学习模型部署等领域中应用广泛,它帮助减少模型的存储需求和计算量,同时保持模型性能。总结来说,量化数据集是量化过程中不可或缺的一部分,它帮助模型在量化后保持高性能,并且对于确定量化参数至关重要。根据不同的量化技术和应用场景,校准集的选择和大小会有所不同。
那我想,咱就用这个wikitext吧,结果由于防火墙嘛啥玩意儿,没办法从huggingface直接使用,那我想就用镜像hfd 吧,我记得之前好像下模型用的就是这个,结果服务器权限不够,真的谢。。。
- 通过网页下载:访问 Hugging Face 数据集页面,点击 “Files and Versions”,选择需要下载的数据集版本及对应的文件格式,如
parquet格式等,点击下载按钮即可将数据集文件下载到本地3.- 使用 huggingface-cli 命令行工具下载3 :
- 首先安装
huggingface_hub:pip install -U huggingface_hub- 设置环境变量,以使用镜像站加速下载,在
~/.bashrc中添加export HF_ENDPOINT=https://hf-mirror.com(Linux 系统),或者在 Windows Powershell 中执行$env:HF_ENDPOINT = "https://hf-mirror.com".详询,一定不能忘记source .bashrc【已解决】如何在服务器中下载huggingface模型,解决huggingface无法连接_failed to connect to huggingface.co port 443-CSDN博客- 执行下载命令:
huggingface-cli download --local-dir-use-symlinks False --repo-type dataset --resume-download wikitext --local-dir wikitext,其中--local-dir参数指定了下载到本地的路径,可根据需要修改为自己想要的路径。- 使用hf-mirror.com的 hfd 工具下载3 :
- 下载 hfd:
wget https://hf-mirror.com/hfd/hfd.sh,并添加执行权限chmod a+x hfd.sh- 设置环境变量,同 huggingface-cli 中的设置方法,在
~/.bashrc中添加export HF_ENDPOINT=https://hf-mirror.com(Linux 系统),或者在 Windows Powershell 中执行$env:HF_ENDPOINT = "https://hf-mirror.com"- 执行下载命令:
./hfd.sh wikitext --dataset --tool aria2c -x 4,其中--dataset表示下载的是数据集,--tool aria2c指定了使用 aria2c 工具进行下载,-x 4表示同时使用 4 个连接进行下载以加速,可根据实际情况调整。
解决了,关于量化数据集问题的解决是将数据集下载到本地,第一次用cli没成功可能是因为没有 source .bashrc 看来还是终端熟悉度不高的原因造成的。
在跑single—gpu时报错
然后修改了.sh文件发现是指定可用GPU有误,老师已经把第0号GPU使用掉了,所以这里改成1,不知道后面会不会报错,期待不会了吧。。。

嗯。。。老师给的卡RTX2080不支持flash-attention
NVIDIA GeForce RTX 2080 Ti 是基于 Turing 架构的 GPU,而不是 Ampere 架构。FlashAttention 是专为 Ampere 架构以及更新的 GPU 设计的,这些 GPU 包括但不限于 NVIDIA A100、NVIDIA H100、GeForce RTX 30 系列等。
由于 FlashAttention 需要 Ampere 架构特有的硬件特性,如新的张量核心和更高效的内存访问模式,因此在 Turing 架构的 RTX 2080 Ti 上,FlashAttention 可能无法提供优化的性能,甚至可能不被支持。
如果你正在使用 GeForce RTX 2080 Ti,你可以尝试以下方法:
1. **使用标准注意力**:继续使用 PyTorch 或 Transformers 库中的标准注意力机制,这些通常在所有支持的 GPU 上都能工作。
2. **检查库支持**:查看 FlashAttention 或相关库的文档,了解是否有对 Turing 架构的支持,或者是否有为旧架构提供回退选项。
3. **升级硬件**:如果可能,考虑升级到支持 Ampere 架构的 GPU,以利用 FlashAttention 的性能优势。
4. **使用其他优化**:探索其他可能适用于 Turing 架构的优化技术,如混合精度训练或模型并行。
5. **社区支持**:如果库的文档没有提供明确信息,你可以在相关的社区论坛或 GitHub 仓库中寻求帮助,了解是否有其他用户在 Turing 架构上成功使用了 FlashAttention 或类似技术。
总之,虽然 GeForce RTX 2080 Ti 是一款强大的 GPU,但它可能无法完全利用 FlashAttention 的优化特性。你可以考虑上述建议来适应你的硬件配置。
如何弃用 Flash-attention?在finetuning文件中没有找到相关的接口,就直接把库删了,据说默认就能直接使用transformer自己的注意力机制了。
终结我的梦。。。。

12.17日
发觉到之前训练总是OOM是因为根据官方文档和finetune文件发现在运行过程中使用gpq量化,这个OOM报错的原因是量化过程中报错,之前下载的Qwen-1_8-chat,这次改成官方量化好的Qwen-1_8-chat-int4,就能在有限显存下微调了。
持续报错:数据读取问题:这个数据是经过我处理后的数据,以数组的形式将json格式的数据写入jsonl文件,结果总是读取不到,产生了两个报错
1、{和“不匹配,这是因为读取的时候使用了for line in file 和json.loads这两个语句,由于json中又有conversation列表中有语句需要{}而没有加转义符号而导致解析错误
2、存到文件中的是一个列表,忘记了哪个错误,总之是json嵌套不能直接json.loads(),而是使用json.load()解决,看来json文件解析这部分还是太不熟练了。
dataset_cls = (
LazySupervisedDataset if data_args.lazy_preprocess else SupervisedDataset
)
rank0_print("Loading data...")
# 创建一个空列表来存储解析后的数据
train_json = []
with open('trainV2.json', 'r', encoding='utf-8') as file:
train_json=json.load(file)
#for line in file:
#for line_number, line in enumerate(file, start=1):
# try:
# 去除行尾的换行符并解析 JSON 数据
#data = json.loads(line)
#json.loads(line.strip())
# 将解析后的数据添加到列表中
#train_json.append(data)
# except json.JSONDecodeError as e:
# print(line_number)
#train_json = json.load(open(data_args.data_path, "r"))
train_dataset = dataset_cls(train_json, tokenizer=tokenizer, max_len=max_len)
总之最后的解决方法就是使用json.load(file)将file看作一个大的字符串,字符串里是一个大的列表,列表中的每个项都是一个json,实际上就是把字符串的双引号脱了,真麻烦。。。之前碰到过这个问题但是都没有总结过,原来懒惰都是给自己挖到的坑。
后来又报错
TypeError: Accelerator.__init__() got an unexpected keyword argument 'dispatch_batches'
经过这几天的折磨,我已经可以轻车熟路地判断出来这是包之间出了依赖问题,降低accelerator版本即可,装装卸卸多个版本后,确定使用0/28/0这个版本,
然后继续报错,缺少mpi4py,这个包的下载更折磨,pip和conda尝试了都下不下来,然后又回去下下卸卸accelerate,最后accelerate版本是0.27.0

然后放弃accelerate,又回来整mpi4py,pip之后有一大堆输出
![]()
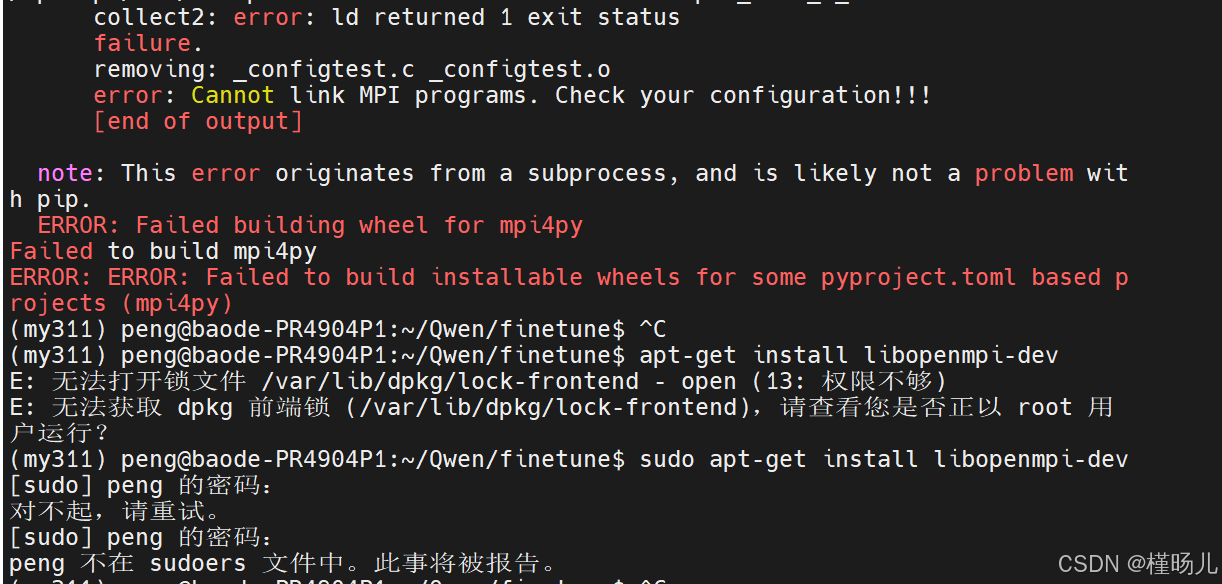
然后使用sudo 没su ,搜了相关问题说下载libopenmpi这个包,下不下来,说的找不到包
![]()

然后又试了一下conda install mpi4py,莫名其妙地能下下来了。。。然后感天动地能跑下来了!!!然后现在的结果是loss下降的很慢,训练过程也很慢,不知道是不是lossprint有点多,但这里train封装的太严实了,不知道要怎么修改相关的参数(其实能从.sh文件修改),另一个问题是没有办法打开tensorboard实时查看训练情况。。。

这次劫先渡到这里,下一章接着讲Transformer封装的Trainer和accelerate。(请监督)


















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











