






Prompt 报告:prompt技术的系统调查
该报告由OpenAI,Stanford,Microsoft等机构在2024年6月17号联合发布,目的是对生成式人工智能的prompt技术进行第一次迭代总结,建立结构化的理解,规范prompt领域的术语。
报告链接:The Prompt Report (trigaten.github.io)
目录
3. Beyond English Text Prompting
Retrieval Augmented Generation (RAG)
1.介绍
研究范围:本次报告研究涉及离散型,前缀的prompt。(也就是我们常用的直接输入大模型的指令)以下游任务为导向,不涉及微调等技术(比如prompt微调等)。
本次报告除了基础的英文文本prompt之外,还研究了多语言的prompt,多模态(文本,图像,语音等)prompt,使用外部工具的(agent)prompt。此外还研究了评估和安全方面
1.1 prompt定义
prompt是生成式人工智能的输入,用来指导生成式人工智能的输出。
prompt template是包含多个变量的函数,通过变量替代来产生prompt实例。
1.2 prompt的组成
Directive:指令,也是prompt的核心,告诉模型做什么
Examples:例子,用于给大模型进行few-shot学习的,给示范
Output Formatting:输出格式要求
Style Instructions:风格的指令,比如要求模型以幽默的语气回复等
Role:角色,就是告诉模型扮演什么,提高模型对某方面的关注
Additional Information:额外信息,通常也被叫做 Context(上下文) (但是报告里面不建议叫做context,说跟LLM前向过程的术语重复了)。这个是用来给模型提供一些知识点,比如RAG(检索增强生成)就是提取相关文档给模型。
1.3 prompt术语
报告介绍了几乎论文中提到的和大家常用的所有术语,进行解释,给出了附录。建议去原报告链接看看。
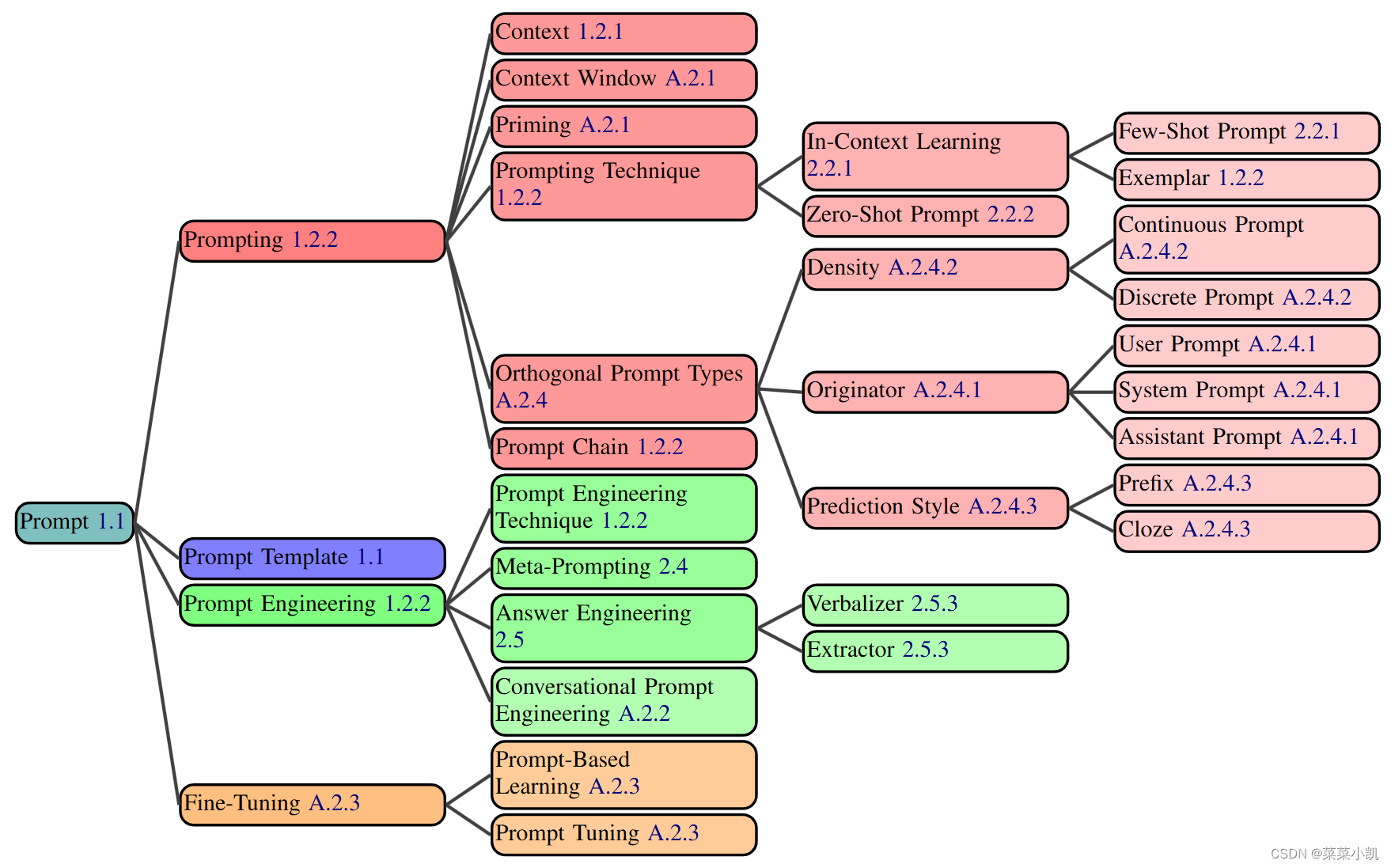
比如介绍一下prompt chain:
什么是链呢,就是多个prompt模板组成一个链,前面的prompt模板的生成的prompt是后面prompt模板的变量,迭代套娃。
再说一下prompting, 这个跟prompt什么区别呢?
prompting是一个prompt向生成式AI发送prompt的过程!prompt是提示,而prompting是过程。
2. Prompt的元分析
前面分析了一通,大概意思是报告通过筛选,最后选出了1565篇论文作为这次的分析 。
2.1 基于文本的prompt
基于文本的提示是目前最常见的,报告分析出了58种基于文本的prompt技术,并且将其分成了6类。
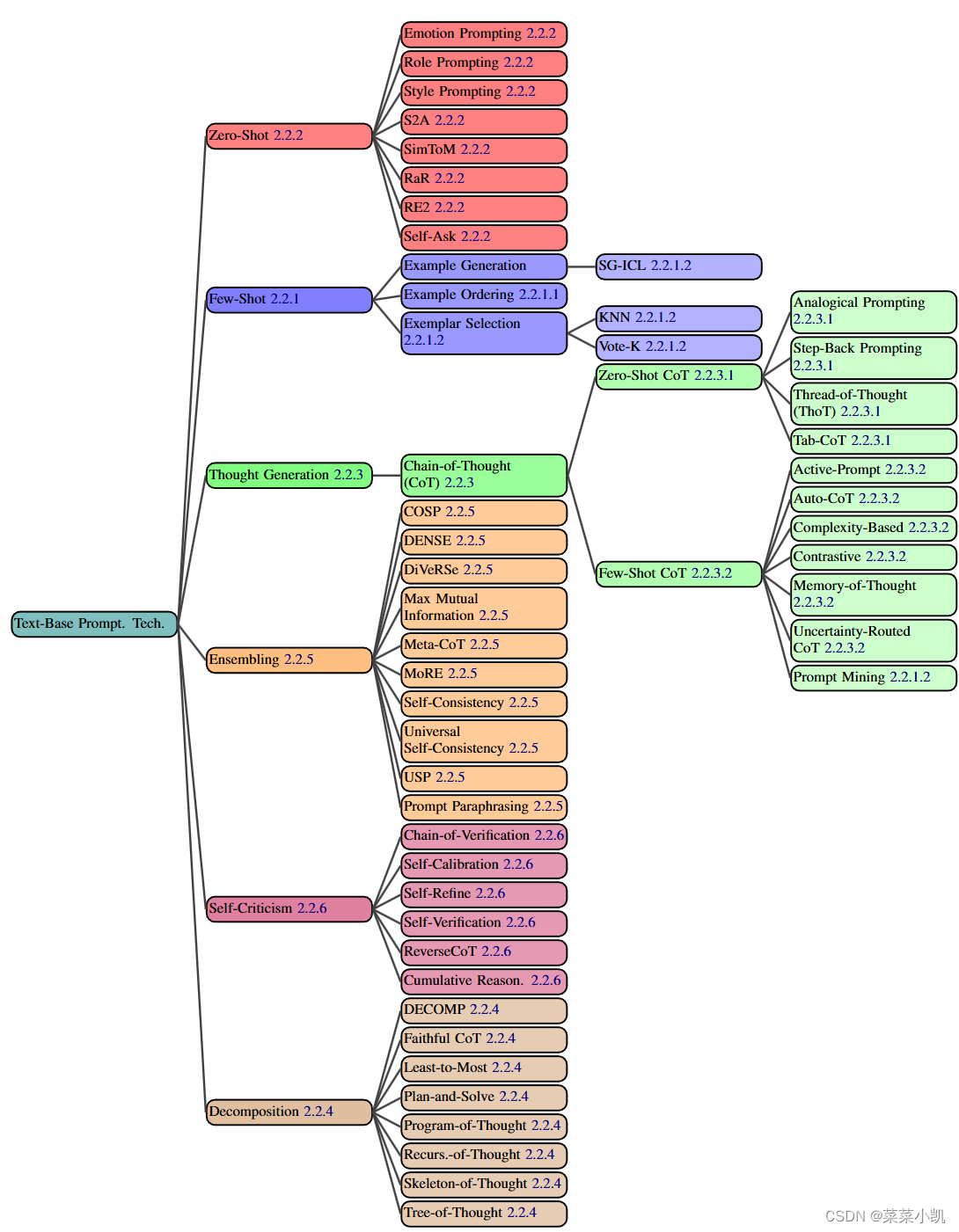
根据报告,进行如下的介绍:
第一类:In-Context Learning (ICL)
In-Context学习在大模型训练中也是个常见技术,利用上下文进行训练。推理时候,我们也可以提供上下文让大模型去学习,毕竟大模型能力比较强,强大的能力赋予了他可以通过输入的改变来进行的输出控制,这也是prompt的意义。
上下文学习也可以理解为少样本的提示或者是学习,在这里我们主要是针对推理,就是提供一些例子,让模型学习我们需要怎么样的形式,什么方面的内容的输出。
那么一个关键是,例子的提供,有没有一些技巧,或者说注意事项呢?有!报告列举了提供例子时,影响模型表现的6种因素。
少样本提示的设计决策
-
例子数量:例子多一些对模型有好处,但是当例子超过20个的时候,好处就不明显了。
-
例子顺序:例子的放置顺序会对模型表现造成,-50%~+90%的影响,所以具体任务可以多尝试。
-
例子标签分布:这个是指例子之间的相似性。我的理解是,假设是个情绪二分类,你给10个例子,8个正向,2个负向,模型在不明确判断的时候,就会偏向正向的分类。
-
例子标签质量:也就是你给的例子对不对。还是假设情绪二分类,假设你的例子就给的错误判断,会影响模型的性能吗?答案是,会,但是可能没有很大的影响,并且随着模型规模越大,这个影响就越小。(为什么非要讨论这个呢,都给例子了不能给正确的吗? 那是因为少样本例子也有可能是从一个大数据集里面自动生成的嘛,规模大的数据集是不能保证其全部正确的!所以这个也告诉我们,自动提取例子是可行的!)
-
例子格式:给例子的格式也会影响模型性能。而且如果按照大模型训练时候的数据格式给,就会有好处!比如问答任务,大模型训练时候问题和答案是{Q:question, A:answer},那你问答时候在也按照这个格式给答案,那是会提升模型表现的。
-
例子相似性:如果给的例子比较贴近实际测试的例子,就会有好处。一些任务中,给的例子比较多样化,也会有好处。
少样本提示的技术
那么有哪些可以帮助我们设计例子的技术呢?
-
K-Nearest Neighbor (KNN):从训练集里面用KNN匹配跟问题最相近的几个训练数据,拿过来当例子,这符合我们之前例子格式的分析,可以提示性能。
-
Vote-K:在KNN的基础上对相似样本进行惩罚,提高了多样性。符合上面例子相似性的结论。
-
Self-Generated In-Context Learning (SG-ICL):训练集不可用的时候,就先把问题给生成式AI(我理解就是大模型),给你生成一些例子,但是这个效果不佳,而且多次传入大模型,效率也会下降!
-
Prompt Mining:这个其实是找prompt模板的,刚才我们提到QA的模板,这个是去语料库找有没有训练时候使用的模板,弄个过来,贴近训练集或者测试集,提高性能。
-
More Complicated Techniques:无非是过滤,检索等等,利用上面6条设计决策,来设计提示技术,提高性能!
第二类:Zero-Shot
零样本技术就是不提供例子,但是其他的提示也不会少,比如赋予角色等,也是我们常用的。
-
Role prompting:赋予大模型角色,比如:你是一个智能客服。
-
Style Prompting:赋予大模型风格,类型,音调等。比如:你是一个童话家,用诙谐的风格讲个故事。
-
Emotion Prompting:赋予一些人类化情绪,让大模型体会。比如:写一篇作文。务必一定超过800字。
-
System 2 Attention (S2A):让大模型重写提示并且移除无关信息,然后把新提示给大模型生成回应。
-
SimToM:让大模型先生成一些事实,再根据事实回应(这些是一起做的,一次问答即可)。这个已经有点思维链的影子了。
-
Rephrase and Respond (RaR):”改写和扩展问题,并响应。“可以把这个和问题一起给,一次提示。也可以得到扩写的问题以后,分别给大模型,得到的不同答案,再进行融合。不过这样效率就低了。
-
Re-reading (RE2):”Read the question again:“。把这个加到问题前面,就可以提高大模型的推理能力。好神奇,可能也是有点让大模型多次关注,反思的结果。
-
Self-Ask:让大模型分析问题,如果有疑问,可以反问用户,根据用户再次的提供信息,再进行最终的回应。这个在客服问答助手之类的,会很有用。
第三类:Thought Generation
这个就是著名的Chain-of-Thought (CoT) Prompting。让大模型回答问题的时候一步步思考!,这个对数学和推理性强的问题,提升很大!
Zero-Shot-CoT
不需要写例子,在问题中,附加提示即可。
比如,著名的一句话:“Let's think step by step.” 还有比如:"Let's work this out in a step by step way to be sure we have the right answer"和 "First, let's think about this logically"。
-
Step-Back Prompting:让大模型先思考这个问题的抽象问题,再反过来思考这个问题。
-
Analogical Prompting:类似SG-ICL,让大模型自己生成包含COT的列子。
-
Thread-of-Thought (ThoT) Prompting:这个提示词是:"Walk me through this context in manageable parts step by step, summarizing and analyzing as we go."这个更加适合有复杂的,较多的上下文的任务。
-
Tabular Chain-of-Thought (Tab-CoT):给提示,让生成表格。这个我去找了原论文,示例如下图:

Few-Shot CoT
就是给一些例子。这些例子使用的就是COT的推理形式,模型会自动去学习。但是,这个需要模型能力比较强!
-
Contrastive CoT Prompting:给的COT例子有正确的,也有错误的,用来对比,让模型更加清楚走怎样的路。
-
Uncertainty-Routed CoT Prompting:选择多个COT路径推理,选答案最多的那个。
-
Complexity-based Prompting:1.对给出的COT示例进行注释,先学习一遍。2.多个COT路径推理,投票选择答案。
-
Active Prompting:从训练里面抽一些问题给大模型回答,对比不确定的,人工重写。
-
Memory-of-Thought Prompting:去训练集里面找相似的问题,大模型自己写COT答案作为例子。
-
Automatic Chain-of-Thought (Auto-CoT) Prompting:先对训练集进行问题聚类,每个类生成一个COT例子。测试时候用。
第四类:Decomposition
将复杂问题分解为简单的几个子问题,分别解决。
-
Least-to-Most Prompting:分解子问题以后,依次求解,求解出一个,就把这个答案加到prompt里面,然后求解下一个,直到得出最终答案!对数学推理效果很好。
-
Decomposed Prompting (DECOMP):LLM将其原始问题分解为发送给不同函数的子问题!这个中,LLM是任务分配者,选择合适的API解决子任务。个人觉得这个很适合大模型和小模型配合。因为小模型往往可以解决具体任务,大模型擅长分析推理!
-
Plan-and-Solve Prompting:有个提示词:"Let's first understand the problem and devise a plan to solve it. Then, let's carry out the plan and solve the problem step by step".
-
Tree-of-Thought (ToT):也是多个想法,产生最佳路径。不过这个效率应该不太好。
-
Recursion-of-Thought:递归与常规 CoT 类似。然而,每次它在推理链中间遇到一个复杂的问题时,它将这个问题发送到另一个提示/LLM调用中。完成后,将答案插入到原始提示中。通过这种方式,它可以递归地解决复杂问题,包括那些可能在该最大上下文长度上运行的问题。这个就有点多Agent那个意思了。
-
Program-of-Thoughts:使用像 Codex 这样的 LLM 来生成编程代码作为推理步骤。代码解释器执行这些步骤以获得最终答案。擅长数学和编程相关的任务,但对语义推理任务效果较差。
-
Faithful Chain-of-Thought:生成具有自然语言和符号语言(例如 Python)推理的 CoT,就像Program-of-Thoughts一样。但是它可以根据任务使用不同类型的符号语言
-
Skeleton-of-Thought:给定一个问题,它提示 LLM 创建答案的骨架,从某种意义上说,要解决子问题。然后,并行地,它将这些问题发送给LLM,并连接所有输出以获得最终响应。这个思路其实也不新,而且多次通过LLM,就算子问题并行,也要3次,效率不高。
第五类:Ensembling
使用多个提示来解决同一问题的过程,然后将这些响应聚合到最终输出中。在许多情况下,多数投票——选择最频繁的响应——用于生成最终输出。这个方式需要调用多个大模型,而且最后的答案聚合也需要大模型聚合。
-
Demonstration Ensembling (DENSE):多个来自训练集的提示,聚合响应。
-
Mixture of Reasoning Experts (MoRE):为不同的推理类型使用不同的提示(例如用于事实推理的检索增强提示、用于多跳和数学推理的思维链推理以及为常识推理生成知识提示),创建不同的推理专家。所有专家的最佳答案是根据一致性分数选择的。
-
Max Mutual Information Method:创建了多个具有不同样式和示例的提示模板,然后选择最佳模板作为最大化提示和 LLM 输出之间的互信息模板。
-
Self-Consistency:在给examples的时候,每个问题回答的思路和格式尽量相同,LLM就会去学习这种自我一致性。对新问题给出类似的答案。基于多个不同的推理路径可以导致相同的答案。这种方法首先多次提示LLM执行CoT,关键是使用非零温度来引出不同的推理路径。接下来,它对所有生成的响应使用多数投票来选择最终响应
-
Universal Self-Consistency:与 Self-Consistency 类似,只是通过编程方式计算它出现的频率来选择多数响应,它将所有输出插入到选择多数答案的提示模板中。
-
Meta-Reasoning over Multiple CoTs:首先为给定的问题生成多个推理链(但不一定是最终答案)。接下来,它将所有这些链插入到单个提示模板中,然后从中生成最终答案。
-
DiVeRSe:多个提示,生成多个COT,对推理路径进行评分,然后选择最终响应。
-
Consistency-based Self-adaptive Prompting (COSP):在一组示例上运行 Zero-Shot CoT 和 Self-Consistency 来构建 Few-Shot CoT 提示,然后选择最终提示中包含的输出的高度一致性子集作为示例。
-
Universal Self-Adaptive Prompting (USP):USP 利用未标记的数据生成样本和更复杂的评分函数来选择它们
-
Prompt Paraphrasing:提示释义 (Jiang et al., 2020) 通过改变一些措辞来转换原始提示,同时仍然保持整体含义。它是一种有效的数据增强技术,可用于为集成生成提示
这些方式感觉效率都比较低,而且增强有限。
第六类:Self-Criticism
让 LLM 批评自己的输出,根据反馈再修改答案,可以提升性能。
-
Self-Calibration:回答问题后,询问答案是否正确,来判断要不要返回答案。
-
Self-Refine:Self-Refine 是一个迭代框架,其中,给定 LLM 的初始答案,它提示相同的 LLM 提供答案的反馈,然后提示 LLM 基于反馈改进答案。这个迭代过程一直持续到满足停止条件(例如,达到的最大步数)。
-
Reversing Chain-of-Thought (RCoT):首先提示 LLM 根据生成的响应重建问题。然后,它将原始问题和重构问题之间的细粒度比较作为检查任何不一致的一种方式。然后将这些不一致转换为LLM的反馈,以修改生成的答案。
-
Self-Verification:生成多个候选解决方案。然后,它通过屏蔽原始问题的某些部分并要求 LLM 根据问题的其余部分和生成的解决方案来预测它们来对每个解决方案进行评分。
-
Chain-of-Verification (COVE):首先使用 LLM 为给定的问题生成答案。然后创建一个相关的问题列表,以帮助验证答案的正确性。每个问题都由 LLM 回答,然后将所有信息提供给 LLM 以产生最终修订的答案。这种方法在各种问答和文本生成任务中显示出改进。这个我认为,非常适合规范性的答案,可以根据必要的要素进行验证!同时适合非即时的任务。
-
Cumulative Reasoning:首先在回答问题时生成几个潜在的步骤。然后它有一个 LLM 评估它们,决定接受或拒绝这些步骤。最后,它检查它是否到达最终答案。如果是这样,它会终止该过程,否则它会重复它。
2.2 Prompting Technique Usage
这里介绍了一些提示技术的使用,包括论文使用怎么样的benchmark,但是由于工业意义不多,感兴趣的可以自己看。
2.3 Prompt Engineering
这里讲解了一些软提示工程(通过学习训练更新的提示token),暂时不太讨论,感兴趣的自己看。
2.4 Answer Engineering
就是如何在LLM的回应里面,抽取正确的答案?有时候可能LLM的响应不符合固定格式,不利于我们的后续逻辑判断。
先看答案工程的元素:
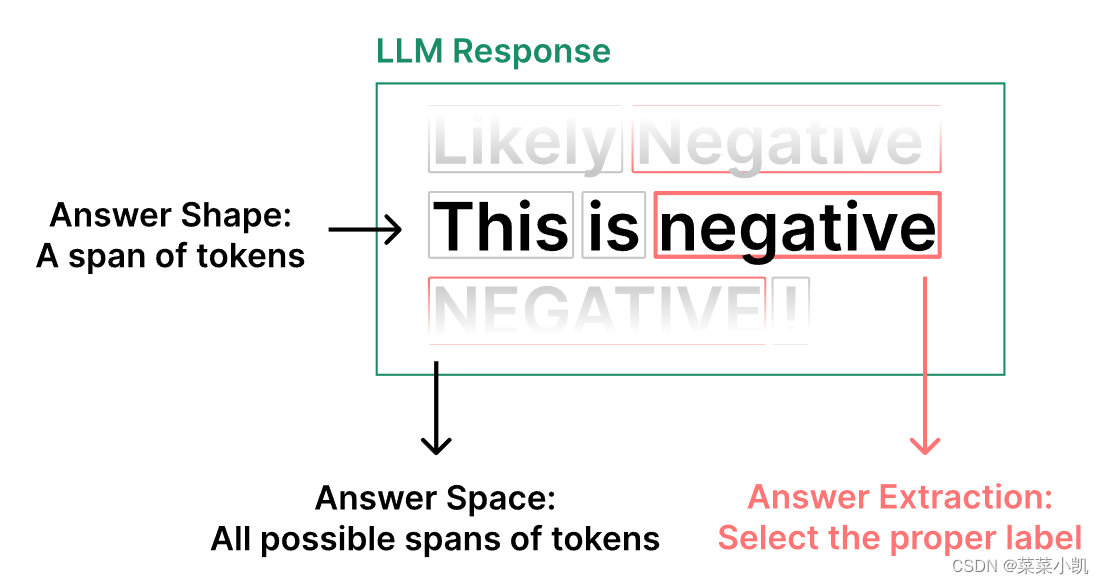
包括三个:答案形状,答案空间,答案提取。
-
Answer Shape:就是模型输出的一系列tokens,所有的响应。
-
Answer Space:我们希望的答案的样子,假设情绪二分类,我们就希望输出”积极“或者”消极“。肯定不希望他是:”这个文本的情绪是积极的。“ 这种回复不是我们想要的,也就不在答案空间里面。
-
Answer Extraction:如何从答案形状中抽取属于答案空间的内容。比如,词表映射,正则表达式提取,独立的LLM提取等。
3. Beyond English Text Prompting
3.1 多语言
Translate First Prompting:翻译成英语输入
对于多语言的挑战主要是,测试集与训练集的分布不同!我们可以通过few-shot的例子来促进LLM实现简单的分布迁移。
比如:在处理模棱两可的句子时,选择具有多义词或稀有词意义的示例可以提高性能。使用跨语言的示例等等。
用于机器翻译的提示
-
Chain-of-Dictionary (CoD):首先从源短语中提取单词,然后通过从字典中检索(例如英语:“苹果”、“西班牙语:“曼扎纳”)。然后,他们将这些字典短语添加到提示中,在那里它要求 GenAI 在翻译期间使用它们。就是利用这个作为上下文,专业名词翻译会很有用!
-
Decomposed Prompting for MT (DecoMT):将源文本分成几个块,并使用少样本提示独立翻译它们。然后它使用这些翻译和块之间的上下文信息来生成最终的翻译。
Human-in-the-Loop
-
Interactive-Chain-Prompting (ICP):通过首先要求 GenAI 生成有关要翻译的短语中任何歧义的子问题来处理翻译的潜在歧义。人类后来对这些问题做出反应,系统包括此信息以生成最终翻译。
-
Iterative Prompting:他们提示 LLM 创建草稿翻译。通过整合从自动检索系统或直接人工反馈获得的监督信号,进一步细化这个初始版本。
3.2 多模态
Image Prompting
图像prompt包括照片,画以及文本截图等等,通常用于,图像生成,标题生成,图像编辑,图像分类等任务。
提示修饰符(prompt modifiers),给图片和文字,用于修改图片的某些地方。
Negative Prompting,用户添加一些负向提示,让图片生成这些更少。
多模态上下文学习
-
Paired-Image Prompting:给出一些图片前后转换的例子,再给出一个图片,模型也可以进行类似的转换。类似few-shot。
-
Image-as-Text Prompting:生成图像的文本描述,基于这个文本就可以生成类似的多个图像。
多模态COT
-
Duty Distinct Chain-of-Thought (DDCoT):创建子问题生成答案然后合并。从text到多模态的延申。
-
Multimodal Graph-of-Thought:在推理时,输入提示用于构建思想图,然后将其与原始提示一起使用以生成回答问题的基本原理。当图像与问题一起输入时,使用图像字幕模型生成图像的文本描述,然后在思想图构建之前将其附加到提示中以提供视觉上下文。
-
Chain-of-Images (CoI):在推理时,输入提示用于构建思想图,然后将其与原始提示一起使用以生成回答问题的基本原理。当图像与问题一起输入时,使用图像字幕模型生成图像的文本描述,然后在思想图构建之前将其附加到提示中以提供视觉上下文。
Audio Prompting
音频提示目前处于早期阶段,但我们希望看到未来提出的各种提示技术。
Video Prompting
Video Generation Techniques
在提示模型生成视频时,可以使用各种形式的提示作为输入,并且经常使用几种提示相关技术来增强视频生成。图像相关技术,例如提示修饰符,通常可用于视频生成。
Segmentation Prompting
提示可以被用来指导语义分割。
3D Prompting
3D输入提示模式包括文本、图像、用户注释(边界框、点、线)和 3D 对象。
4. prompt的延伸
4.1 Agent
定义:我们将代理定义为 GenAI 系统,该系统通过参与 GenAI 本身之外的系统的动作为用户提供目标。
Tool Use Agents
-
Modular Reasoning, Knowledge, and Language (MRKL) System:进行推理选择对应api工具的使用,这个需要微调模型达到这个能力。
-
Self-Correcting with Tool-Interactive Critiquing (CRITIC):先不适用工具生成一个答案,然后用相同的LLM批判这个答案,再调用工具去修复不正确的地方。
Code-Generation Agents
-
Program-aided Language Model (PAL):将问题翻译成代码,利用python解释器生成答案。
-
Tool-Integrated Reasoning Agent (ToRA):类似PAL,但是只在必要的步骤使用代码,代码和推理交错。
-
TaskWeaver:类似PAL,也是翻译成code,但是使用的是用户自己选择工具和插件。
Observation-Based Agents
基于对环境的观察,将观察到的环境插入到prompt中。
-
Reasoning and Acting (ReAct):生成一个想法,采取行动,并在给定一个要解决的问题时接收观察(并重复这个过程)。所有这些信息都被插入到提示中,因此它具有过去的想法、动作和观察的记忆。
-
Reflexion:建立在 ReAct 之上,添加了一层内省。它获得了动作和观察的轨迹,然后给出了成功/失败的评估。然后,它会对它做什么和什么出错产生反思。这种反射被添加到它的提示中作为工作记忆,过程重复。
Lifelong Learning Agents:
-
Voyager:由三部分组成。首先,它为自己提出任务来完成,以便更多地了解世界。其次,它生成代码来执行这些操作。最后,当有用时,它会保存这些动作以供以后检索,作为长期记忆系统的一部分。该系统可以应用于代理需要探索和与工具或网站(例如渗透测试、可用性测试)交互的现实世界任务。
-
Ghost in the Minecraft (GITM):从任意目标开始,递归地将其分解为子目标,然后通过生成结构化文本(例如“equip(sword)”)而不是编写代码来迭代计划和执行动作。GITM 使用 Minecraft 项目的外部知识库来辅助分解以及过去经验的记忆。
这部分不太了解效果,但是大为震惊,现在agents都发展到这个地步了吗,终身学习。
Retrieval Augmented Generation (RAG)
这里面很多方法也是分解,COT类似的,建议去看专门的RAG综述讲解会更好。
4.2 评估
对于一个稳定的评估框架,作者分成了四部分:prompt技术,输出格式,prompt框架,其他的一些技术。
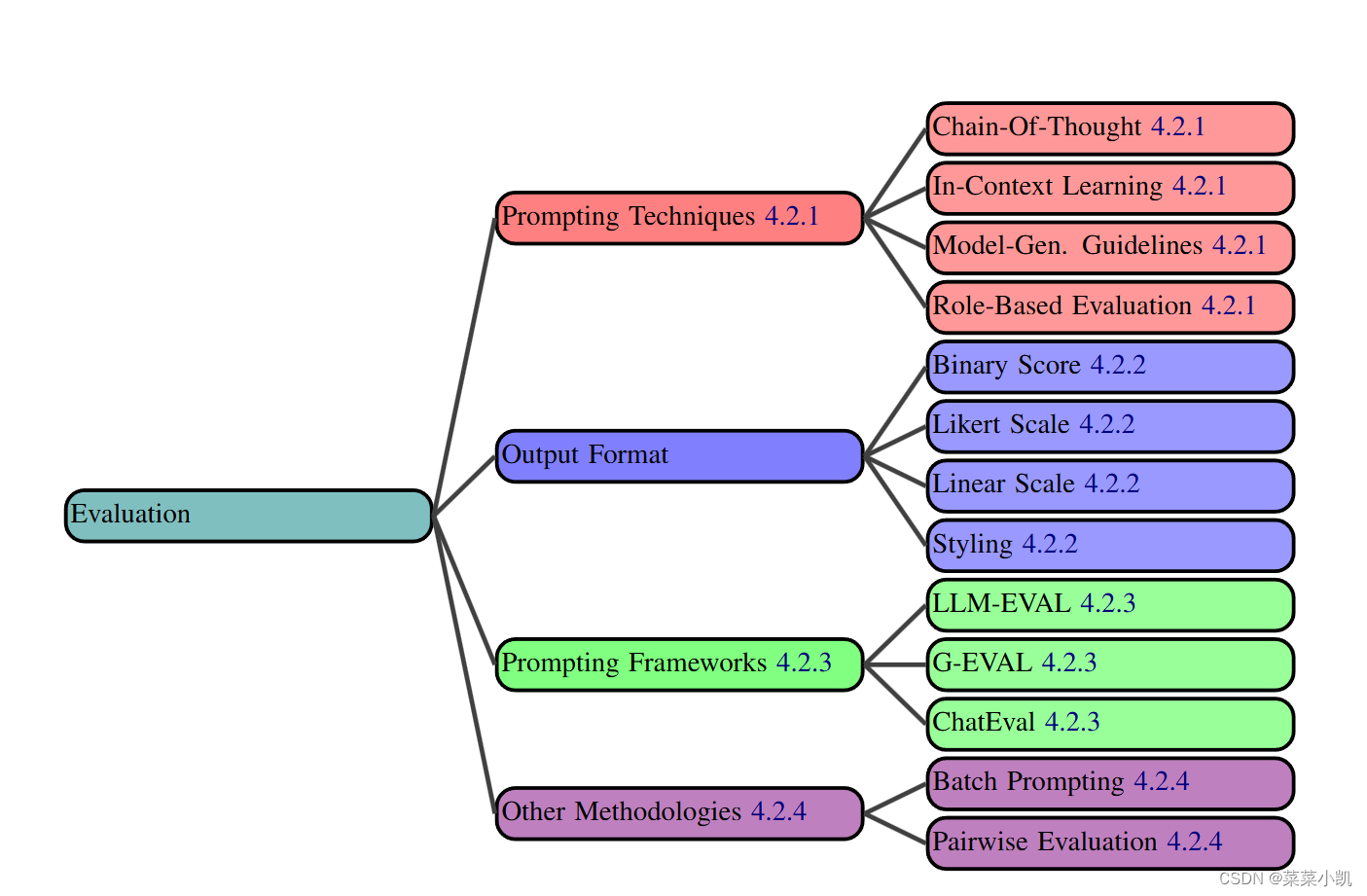
Prompting Techniques
四种:上下文学习,基于角色和COT都是跟上面一样,用这些思想提示LLM进行评估。 Model-Gen. Guidelines是先让LLM生成一个指导的原则,或者说评估的规则,依据这个规则进行评估,这样就可以避免前后评估不一致的问题!
Output Format
规范评估器的输出格式是很有帮助的,作者分为如下几种:
1.规范风格,确保输出类似json,xml等格式。
2.规范线性的范围,比如让LLM输出结果在1-10分之间这种。
3.二分类,LLM判断yes和no。
4.喜欢的范围,比如给出一些选项:poor,acceptable,good,very good 类似这种。
Prompting Frameworks
-
LLM-EVAL:它使用包含变量模式的单个提示来评估(例如语法、相关性等),说明模型在某个范围内输出每个变量的分数,以及要评估的内容。
-
G-EVAL:与 LLMEVAL 类似,但在提示本身中包含了 AutoCoT 步骤。这些步骤是根据评估指令生成的,并插入到最终提示中。根据标记概率有权重的回答。
-
ChatEval:使用多智能体辩论框架,每个代理都有一个单独的角色。
Other Methodologies
-
Batch Prompting:多个实例一次评估或者一个实例多次评估,前者会降低每个的评估性能,后者类似辩论的形式。
-
Pairwise Evaluation:发现直接比较两个文本的质量可能会导致次优结果,并且明确要求 LLM 为单个摘要生成分数是最有效的可靠方法。成对比较的输入顺序也可能严重影响评估
5. Prompting的问题
5.1 Security
本章节描述了关于prompt的可以攻击LLM造成隐私泄露的一系列安全问题以及如何使用简单的prompt进行防御。此处不再概述,感兴趣可以去原文章读一读这一节。
5.2 Alignment
本章节说了,prompt是敏感的,简单的微小改动就可能导致输出性能的改变。而且随着模型发生变化,prompt也要随着修改。
本章节还分析了模型可能带来的关于文化方面的偏见,模糊的问题等等
对于模糊问题的澄清:显式地设计单独的提示:1)生成初始答案2)分类是否生成澄清问题或返回初始答案3)决定生成什么澄清问题4)生成最终答案。 这个有助于跟用户进行交互。
6. Benchmarking
第六章描述了目前实验的很多benchmarking,由于我不使用这个学术研究,暂时不进行解析。感兴趣可以去看原文。
7. Related Work
第七章简短介绍了相关工作。
8. Conclusions
结论作者声明了,这个报告主要是规范提示工程中间的术语,使用,顺便做第一次的迭代总结。(看看大佬说的话,能为一个领域做一次迭代总结!)不过他们也强调了,本次研究主要是观察性的,无法保证所有列出技术的有效性,也鼓励大家进行prompt的尝试和观察!并且沿着他们这个文档的写法和思路,把prompt这个领域做下去,你我共勉。
文本Prompt示例
最后也为大家提供了一个prompt模板示例,使用python写出:
role = f"此处定义角色,来对齐下游任务"
context = "这里是一些上下文,给模型一些参考信息,可以降低幻觉(例如RAG的参考文档,翻译任务中的专有名词等等)"
question = "对于一个chat场景,这个就是用户的问题,或者说是指令都可,是任务的关键目标。"
output_type = "这里定义输出类型,比如json,也可以使用langchain框架对输出进行类型检验和纠正。"
examples = "这里给出一些示例用于few-shot,在这里我们可以进行很多的prompt优化,比如COT示例,或者借助示例规范输出等,都是可以的。示例进行与训练样本的格式对齐,与测试样本的分布对齐。"
# 系统消息通常用于定义角色,如果是助手的话是AI的回答,用于传对话历史的。
system_message = f"##Role:{role}"
user_message = f"""
##Context:
{context}
##Examples:
{examples}
##output_type:
{output_type}
##Question:
{question}
"""
















 2578
2578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









