







 本文介绍OCR技术的基本概念及其发展历程,详细阐述了OCR的工作流程,包括图像预处理、字符分割与识别等关键步骤,并提供了MATLAB实现的示例代码。
本文介绍OCR技术的基本概念及其发展历程,详细阐述了OCR的工作流程,包括图像预处理、字符分割与识别等关键步骤,并提供了MATLAB实现的示例代码。
目录
1.算法描述
OCR技术中使用模板匹配法时首先要建立标准的模板字符库,接着将待识别字符图像与模板字符库中字符进行匹配相似度计算,得到匹配相似度值最大的就是相对应的字符识别结果。模板匹配的优点在于识别过程直接采取两幅图像间的相似匹配度,在某些特定的场景中有着很高的实用性。
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提升识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也随之产生。简单来说,**OCR识别就是光学文字识别,是指通过图像处理和模式识别技术对光学的字符进行识别。**它是计算机视觉研究领域的分支之一,是计算机科学的重要组成部分。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
OCR的概念是在1929年由德国科学家Tausheck最早提出来的,后来美国科学家Handel也提出了利用技术对文字进行识别的想法。而最先对印刷体汉字识别进行研究的是IBM公司的Casey和Nagy,1966年他们发表了第一篇关于汉字识别的文章,采用了模板匹配法识别了1000个印刷体汉字。
早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以一样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局做区域分信的做业;也所以至今邮政编码一直是各国所倡导的地址书写方式。
20世纪70年代初,日本的学者开始研究汉字识别,并作了大量的工做。中国在OCR技术方面的研究工做起步较晚,在70年代才开始对数字、英文字母及符号的识别进行研究,70年代末开始进行汉字识别的研究,到1986年,我国提出“863”高新科技研究计划,汉字识别的研究进入一个实质性的阶段,清华大学的丁晓青教授和中科院分别开发研究,相继推出了中文OCR产品,现为中国最领先汉字OCR技术。早期的OCR软件,因为识别率及产品化等多方面的因素,未能达到实际要求。同时,因为硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。进入20世纪90年代之后,随着平台式扫描仪的普遍应用,以及我国信息自动化和办公自动化的普及,大大推进了OCR技术的进一步发展,使OCR的识别正确率、识别速度知足了广大用户的要求。
文字识别(OCR)目前在多个行业中得到了广泛应用,比如金融行业的单据识别输入,餐饮行业中的发票识别, 交通领域的车票识别,企业中各种表单识别,以及日常工作生活中常用的身份证,驾驶证,护照识别等等。
OCR(文字识别)是目前常用的一种AI能力。 一般OCR的识别结果是一种按行识别的结构化输出,能够给出一行文字的检测框坐标及文字内容。
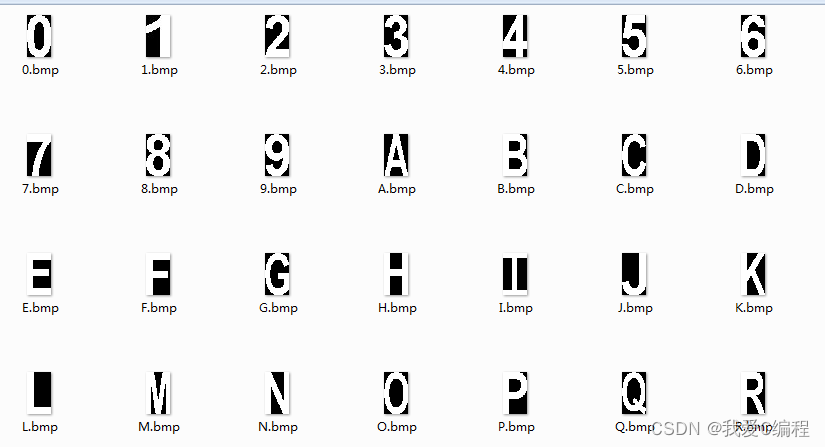
OCR(光学字符识别)是指机器自动从图像中识别文本字符的过程,是目标分类和识别的一种应用,包括训练与分类过程,可用于对被测件的识别和分类。
OCR训练过程主要从图像中提取用于字符识别的特征向量,并对各字符图像赋予准确的字符值。具有相同字符值的字符样本图像构成一个字符类,该类可以用其中一个最能代表该类字符的样本图像来代表,称为参考字符。字符训练完成后,就可得到一个用于对字符进行识别的字符集。
OCR对图像中的文本进行读取时,会先将图像中的各个字符图像分割开来,并将字符的特征向量与字符集中保存的特征向量进行对比,选取满足条件的最佳匹配向量所对应的字符值作为读取识别结果。若有必要,也可以通过字符验证过程对OCR的识别质量进行验证。
常见的OCR识别应用包括:药品包装标签识别、IC芯片编码读取、冲压零件上的字符识别、汽车零件编码读取以及车牌识别等。
OCR步骤如下:
1、图像输入、预处理:
图像输入:对于不同的图像格式,有着不同的存储格式,不同的压缩方式。预处理:主要包括二值化,噪声去除,倾斜较正等
2、二值化:
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,我们可以简单的分为前景与背景,为了让计算机更快的,更好的识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图了。
3、噪声去除:
对于不同的文档,我们对噪声的定义可以不同,根据噪声的特征进行去噪,就叫做噪声去除
4、倾斜较正:
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
5、版面分析:
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,还没有一个固定的,最优的切割模型。
6、字符切割:
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能,这就需要文字识别软件有字符切割功能。
7、字符识别:
这一研究,已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
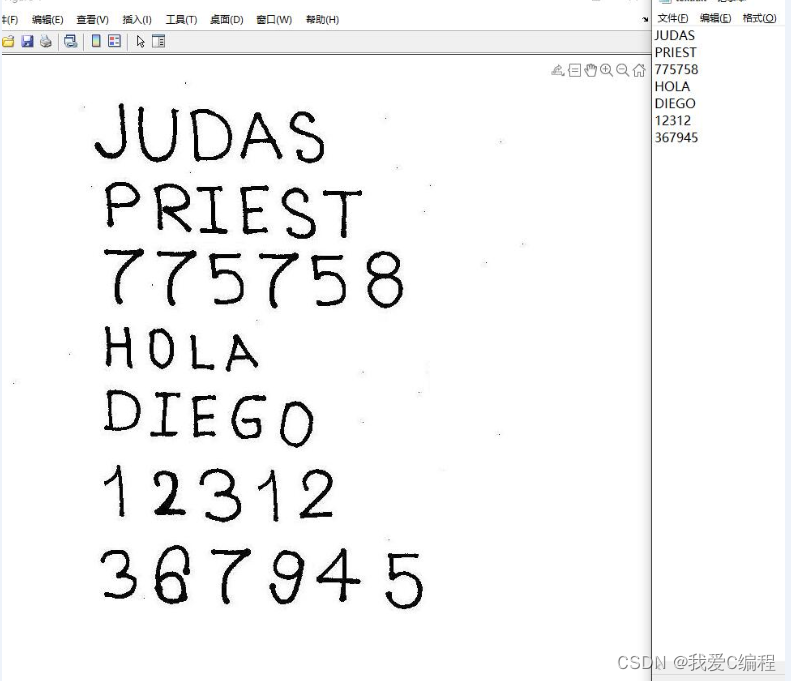
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
if vd==1
letter='A';
elseif vd==2
letter='B';
elseif vd==3
letter='C';
elseif vd==4
letter='D';
elseif vd==5
letter='E';
elseif vd==6
letter='F';
elseif vd==7
letter='G';
elseif vd==8
letter='H';
elseif vd==9
letter='I';
elseif vd==10
letter='J';
elseif vd==11
letter='K';
elseif vd==12
letter='L';
elseif vd==13
letter='M';
elseif vd==14
letter='N';
elseif vd==15
letter='O';
elseif vd==16
letter='P';
elseif vd==17
letter='Q';
elseif vd==18
letter='R';
elseif vd==19
letter='S';
elseif vd==20
letter='T';
elseif vd==21
letter='U';
elseif vd==22
letter='V';
elseif vd==23
letter='W';
elseif vd==24
letter='X';
elseif vd==25
letter='Y';
elseif vd==26
letter='Z';
%*-*-*-*-*
elseif vd==27
letter='1';
elseif vd==28
letter='2';
elseif vd==29
letter='3';
elseif vd==30
letter='4';
elseif vd==31
letter='5';
elseif vd==32
letter='6';
elseif vd==33
letter='7';
elseif vd==34
letter='8';
elseif vd==35
letter='9';
else
letter='0';
endimagen=imread('TEST_1.jpg');
imshow(imagen);
if size(imagen,3)==3 %RGB image
imagen=rgb2gray(imagen);
end
% Convert to BW
threshold = graythresh(imagen);
imagen =~im2bw(imagen,threshold);
imagen = bwareaopen(imagen,30);
word=[ ];
re=imagen;
fid = fopen('text.txt', 'wt');
% Load templates
load templates
global templates
num_letras=size(templates,2);
while 1
%Fcn 'lines' separate lines in text
[fl re]=lines(re);
imgn=fl;
[L Ne] = bwlabel(imgn);
for n=1:Ne
[r,c] = find(L==n);
% Extract letter
n1=imgn(min(r):max(r),min(c):max(c));
img_r=imresize(n1,[42 24]);
letter=read_letter(img_r,num_letras);
word=[word letter];
end
fprintf(fid,'%s\n',word);%Write 'word' in text file (upper)
word=[ ];
if isempty(re) %See variable 're' in Fcn 'lines'
break
end
end
fclose(fid);
winopen('text.txt')
A163
4.完整MATLAB
V


















 1661
1661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











