






重磅发布,阿里云深夜发布了传言已久的Qwen3(通义千问3)系列大模型,一举拿下开源模型冠军。

阿里这次一共发布了8个模型,Qwen3-0.6B、1.7B、4B、8B、14B、32B,这6个都是Dense稠密模型。
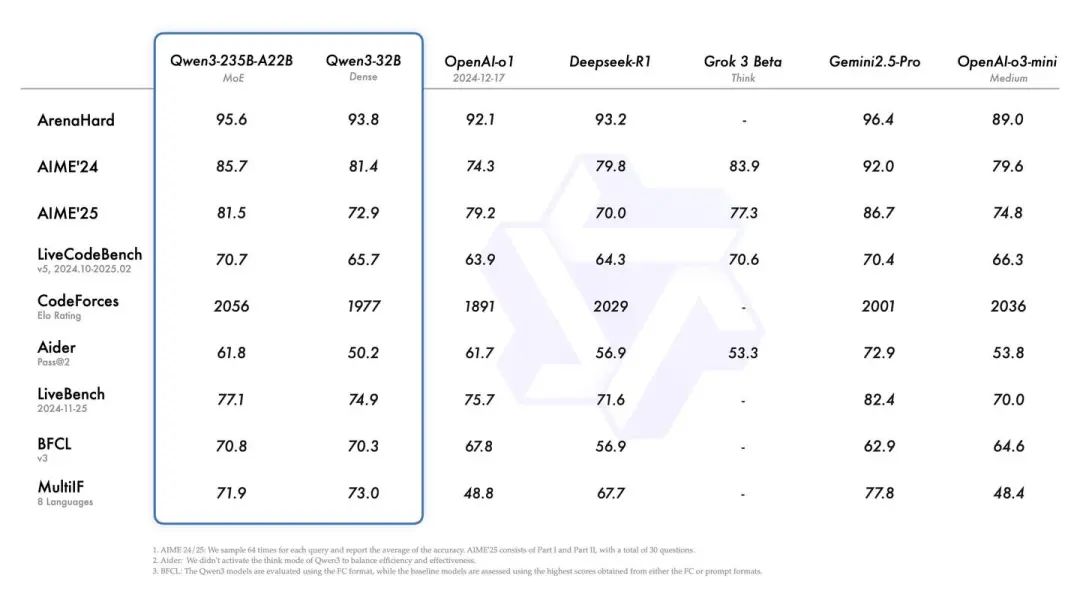
还有两个重量级MoE模型,Qwen3-30B-A3B,和旗舰版的Qwen3-235B-A22B。MoE旗舰版Qwen3-235B-A22B在22B的激活参数下,性能与当前最先进的闭源模型Gemini 2.5 Pro、o1能力相当。
但其在部署效率方面取得重要突破,仅需4块H20显卡即可完成完整部署。相较于前代Qwen 2.5,Qwen 3整体能力提升明显,Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。模型采用4步预训练和4步后训练,具有混合推理能力。
旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
仅发布2小时,GitHub星标数便突破1.6万,成为开发者关注的焦点。向世界展示了中国大模型的硬实力。

五大核心升级:Qwen3凭什么“以小搏大”?
1. 混合思考模式:快与慢的智慧平衡
Qwen3首次引入“思考模式”与“非思考模式”:
- 思考模式
:逐步推理,适合解决复杂问题(如数学证明、编程难题),输出严谨答案;
- 非思考模式
:快速响应,适用于简单任务(如问答、摘要生成),几乎“秒回”。
用户可灵活切换模式,平衡推理质量与响应速度,甚至自定义思考预算,让模型更“聪明”也更“高效”。
2. 推理能力飞跃:小参数打败大模型
- Qwen3-235B-A22B
:在编程、数学、通用能力基准测试中,超越DeepSeek-R1、OpenAI o1/o3-mini等国际竞品;
- Qwen3-4B
:参数仅为Qwen2.5-72B的5.6%,但性能相当,真正实现“小身板,大能量”;
- STEM与代码生成
:在数学、代码等高难度领域,Qwen3甚至超越参数更大的Qwen2.5系列。
3. 多语言支持:119种语言无障碍沟通
Qwen3覆盖全球119种语言及方言,无论是中文、英文,还是小语种、方言,均具备理解、推理、生成能力,助力跨国协作与全球化场景落地。
4. Agent能力强化:MCP协议让模型“更聪明”
通过MCP(模型上下文协议),Qwen3可无缝集成外部数据源和工具,完成复杂任务(如数据分析、多步骤推理)。例如:
结合天气API生成旅行建议;
调用数据库生成财务报告。
开发者可轻松构建智能Agent,让模型成为真正的“决策助手”。
5. 开源与部署:灵活适配各类场景
Qwen3在Hugging Face、ModelScope等平台开源,遵循Apache 2.0协议,支持本地部署工具(如Ollama、LMStudio)。开发者可结合SGLang、vLLM等框架,快速实现模型落地。
技术亮点:数据规模翻倍,训练策略革新
1. 预训练数据量翻三倍
Qwen3的预训练数据量从Qwen2.5的1800亿token激增至3600亿token,涵盖网络文本、PDF文档、合成数据(通过Qwen2.5-Math/Coder生成),尤其强化了数学、代码领域的数据质量。
2. 三阶段预训练+四阶段微调
- 预训练
:分阶段提升模型能力,从基础语言技能到长上下文处理;
- 微调
:通过思维链(CoT)冷启动、强化学习、模式融合等步骤,兼顾推理与快速响应能力。
3. MoE架构:激活参数更高效
Qwen3包含2个MoE(混合专家)模型:
- Qwen3-30B-A3B
:激活参数仅30亿(总参数300亿),性能却反超QwQ-32B(激活参数320亿);
- 上下文长度
:小模型支持32K,大模型支持128K,满足长文本处理需求。
Qwen3,定义下一代AI的“中国速度”
从数据规模到技术创新,从性能突破到开源生态,Qwen3再次证明了阿里云在大模型领域的深厚积累。无论是开发者还是企业,都能借助Qwen3的灵活性与强大能力,快速落地智能应用。

















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









