







深度学习简介
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
深度学习采用的模型为深层神经网络(Deep Neural Networks,DNN)模型,即包含多个隐藏层(Hidden Layer,也称隐含层)的神经网络(Neural Networks,NN)。深度学习利用模型中的隐藏层,通过特征组合的方式,逐层将原始输入转化为浅层特征,中层特征,高层特征直至最终的任务目标。
如下图所示:
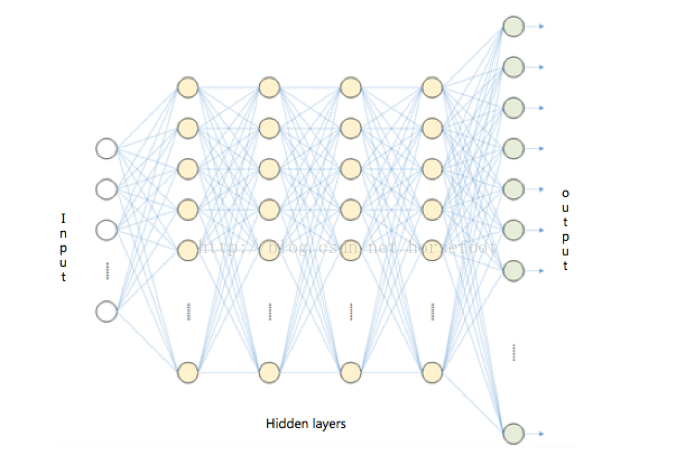
相对于传统的神经网络,深度学习含有更多的隐层(hidden layer),构造包含多隐藏层的深层网络结背后的理论依据包括仿生学依据与训练任务的层次结构依据。
对于很多训练任务来说,特征具有天然的层次结构。以语音、图像、文本为例,层次结构大概如下表所示。

以图像识别为例,图像的原始输入是像素,相邻像素组成线条,多个线条组成纹理,进一步形成图案,图案构成了物体的局部,直至整个物体的样子。不难发现,可以找到原始输入和浅层特征之间的联系,再通过中层特征,一步一步获得和高层特征的联系。想要从原始输入直接跨越到高层特征,无疑是困难的。
GPU计算的原理
1. GPU计算的优势
复杂的人工智能算法训练与计算经常涉及上亿的参数,这些参数的计算需要大量的计算能力,目前在深度学习领域,GPU计算已经成为主流,使用GPU运算的优势如下:
目前,主流的GPU具有强大的计算能力和内存带宽,如下图所示,无论性能还是内存带宽,均远大于同代的CPU。 同时,GPU的thousands of cores的并行计算能力也是一大优势。
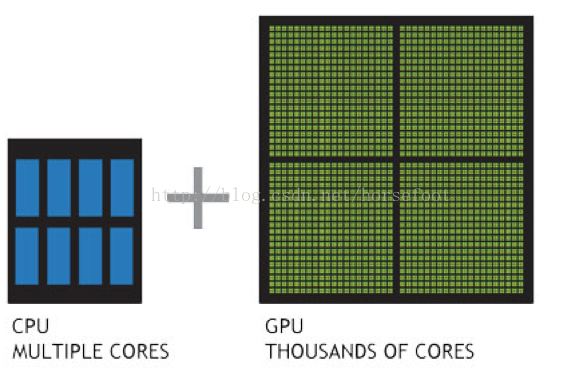
理解 GPU 和 CPU 之间区别的一种简单方式是比较它们如何处理任务。CPU 由专为顺序串行处理而优化的几个核心组成,而 GPU 则拥有一个由数以千计的更小、更高效的核心(专为同时处理多重任务而设计)组成的大规模并行计算架构。同时CPU相当的一部分时间在执行外设的中断、进程的切换等任务,而GPU有更多的时间并行计算。
2. GPU计算的原理
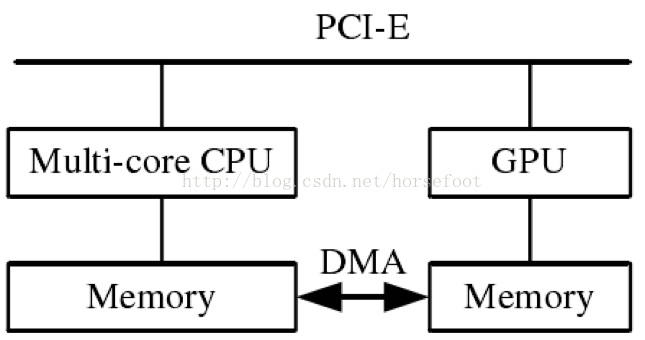
那么,CPU与GPU如何协同工作?下图展示了CPU与GPU的并存体系模式。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 677
677

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









