






在上篇文章中,我们使用Qwen2.5-Coder编写了一个自动编程的多智能体系统(基于 Qwen2.5-Coder 模型和 CrewAI 多智能体框架,实现智能编程系统的实战教程),着实感受到了Qwen2.5-Coder和CrewAI强强联合所发挥出来的强大威力。
我们知道最新发布的Qwen2.5全家桶共有 3 个模型,除常规的大语言模型 Qwen2.5 和专门针对编程的 Qwen2.5-Coder 模型之外,还有一个专门针对数学的 Qwen2.5-Math 模型,它号称是世界领先的数学开源大语言模型,我们今天就通过奥数题目来实实在在的感受一下它的强大之处。
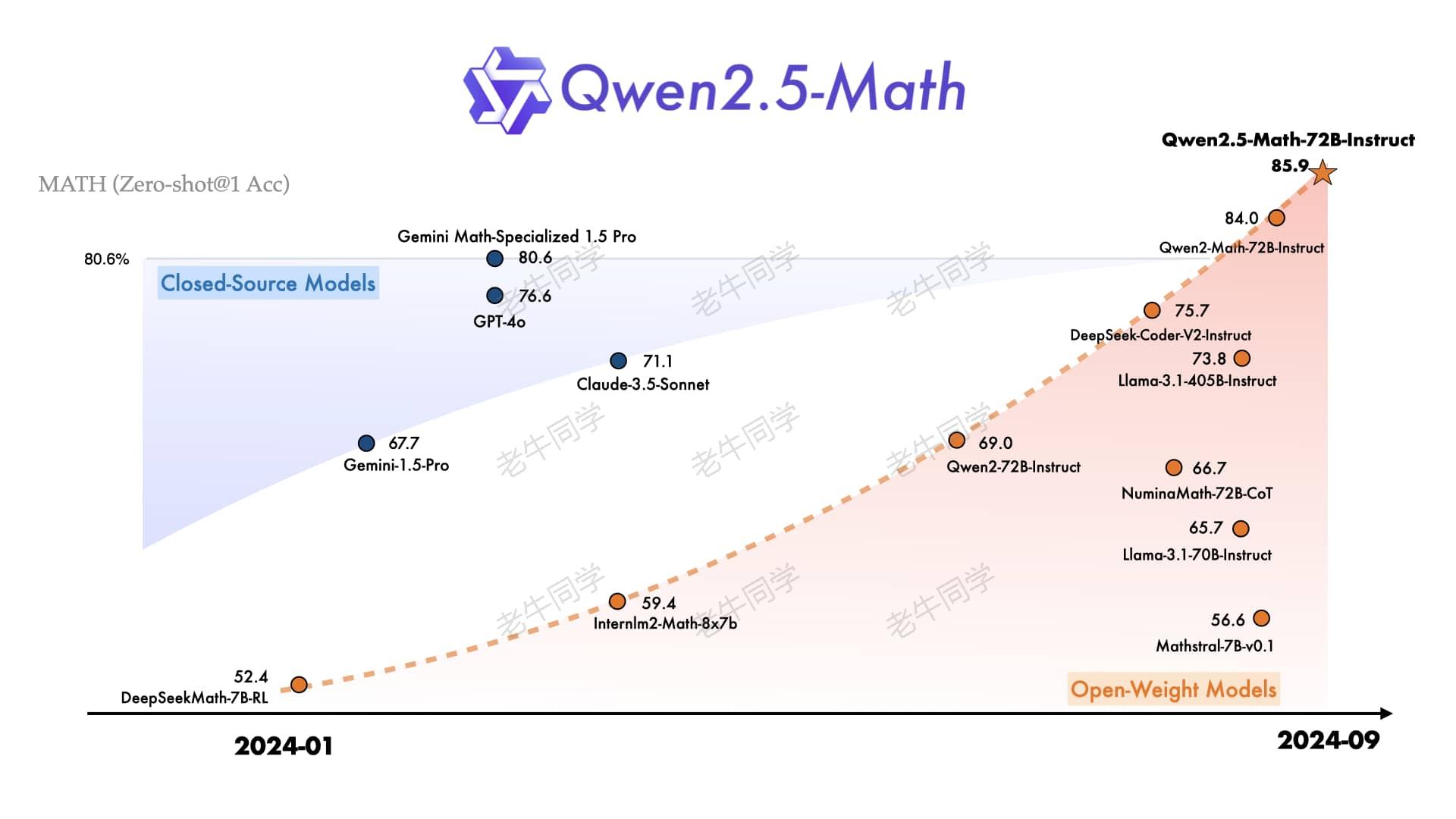
因此,我们将通过以下 3 个主要部分来完成 Qwen2.5-Math 模型的实战之旅:
- Qwen2.5-Math的基本介绍,主要是简单了解一下Qwen2.5-Math的特点和能力
- 本地部署Qwen2.5-Math-1.5B模型,通过一个一元一次方程简单数学题,体验一下其数学推理能力
- 我们选取小学和初中阶段经典的几道奥数题,让 Qwen2.5-Math-72B 作为 AI 老师,来实战验证其逻辑推导能力
Qwen2.5-Math 基本介绍、CoT 和 TIR 推理方式
Qwen2.5-Math 明确说明:Qwen2.5-Math 主要被设计用于通过CoT或TIR的方式解中英数学题,不推荐在其他任务上使用该系列模型。那么,什么是 CoT 和 TIR 推理方式呢?
【CoT 推理方式:】即思维链(Chain of Thought),主要目的是让大模型一步一步的展现出其推理过程,而不是直接给答案,就像我们人类逻辑思维过程一样,通过多步分解的方式,能更好的理解和解决复杂问题。如下数学题目的解答过程:
- 题目:小明有 10 个苹果,他给了小红 3 个苹果,然后又买了 5 个苹果,请问小明现在有几个苹果?
- CoT 推理过程:
- 第一步:小明最初有 10 个苹果。
- 第二步:小明给了小红 3 个苹果,所以现在剩下 10-3=7 个苹果。
- 第三步:小明又买了 5 个苹果,所以现在共有 7+5=12 个苹果。
- 答案:现在小明有 12 个苹果。
【TIR 推理方式:】即工具集成推理(Tool integrated Reasoning),就是在推理过程中使用外部工具(如:使用 Python 执行代码获取结果)。TIR 是Qwen2.5-Math的新特性,它能显著提升中英文的数学解题能力,包括精确计算、符号操作和算法操作等方面。具体用法可以阅读样例代码:https://github.com/QwenLM/Qwen-Agent
另外,有关 Qwen2.5-Math 的预训练架构设计,有个特别有趣的地方:Qwen2.5-Math的部分预训练数据,竟然是由Qwen2-Math-Instruct 模型提供的,感觉它们已经开始在左右互搏了,因此世界领先也就不为奇了。
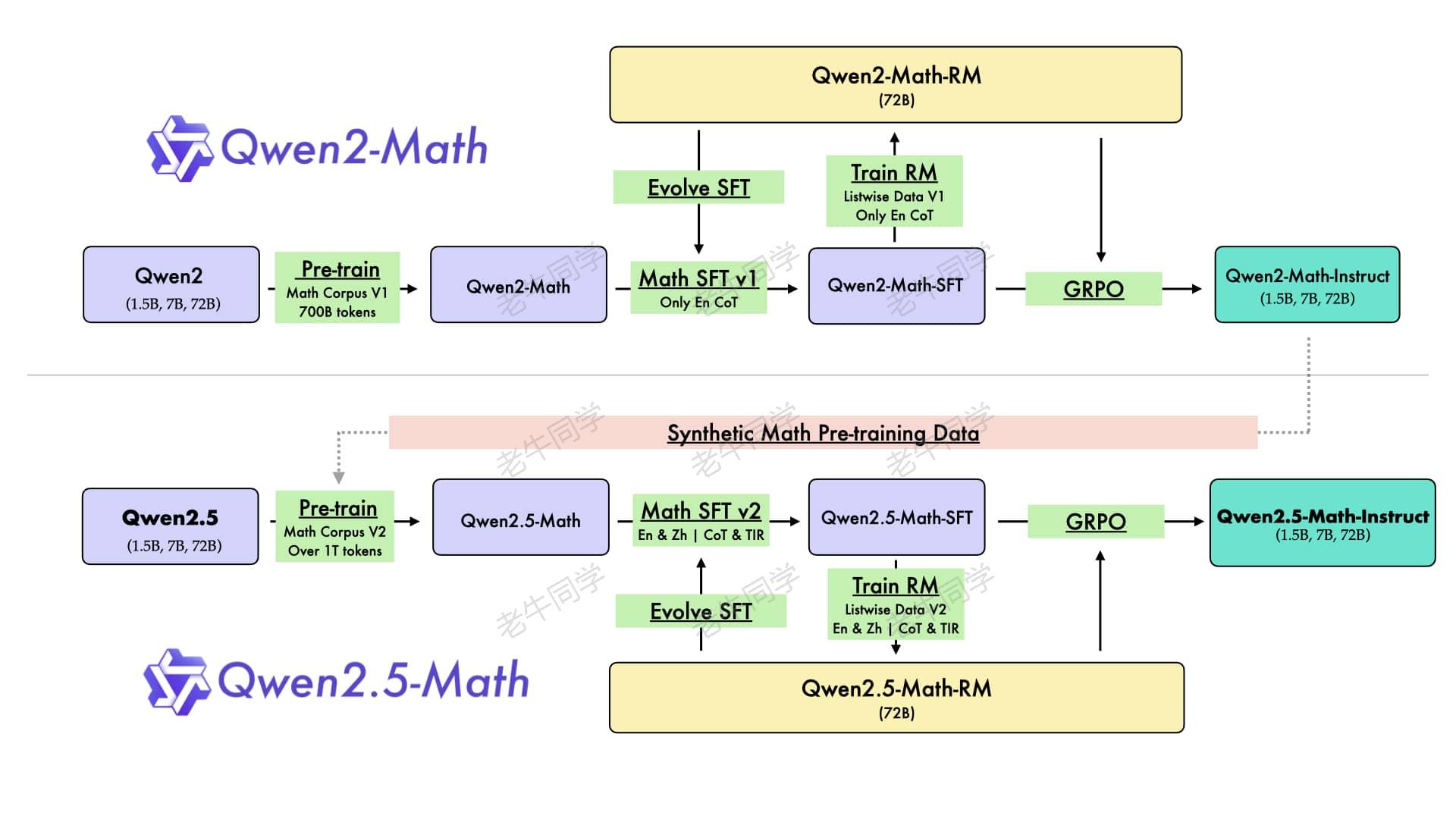
更多 Qwen2.5-Math 的详细介绍,可查看官网:https://qwenlm.github.io/zh/blog/qwen2.5-math/
Qwen2.5-Math 本地部署和体验
我们先本地部署 Qwen2.5-Math 模型,然后进行简单的数学题推理。由于老牛同学电脑配置不够强悍,因此本次演示我们使用1.5B参数版本(大家可根据自己硬件配置,选择不同的参数量版本)。我们通过以下三步完成整个流程:
【第一步:下载 Qwen2.5-Math 模型权重文件】
存放权重文件目录:Qwen2.5-Math-1.5B-Instruct
# Git大文件系统
git lfs install
# 下载模型权重文件
git clone https://www.modelscope.cn/qwen/Qwen2.5-math-1.5B-Instruct.git Qwen2.5-Math-1.5B-Instruct
若下载过程中异常中断,可以通过git lfs install命令继续下载:
# 切换到Git目录
cd Qwen2.5-Math-1.5B-Instruct
# 继续下载
git lfs install
git lfs pull
【第二步:设置 Python 虚拟环境和安装依赖】
工欲善其事,必先利其器,我们通过Miniconda管理 Python 虚拟环境,Miniconda的安装和使用可以参考老牛同学之前的文章:大模型应用研发基础环境配置(Miniconda、Python、Jupyter Lab、Ollama 等)
# Python虚拟环境名:Qwen2.5,版本号:3.10
conda create -n Qwen2.5 python=3.10 -y
# 激活虚拟环境
conda activate Qwen2.5
接下来,在虚拟环境中下载依赖包:
pip install torch
pip install modelscope
pip install "transformers>=4.37.0"
pip install "accelerate>=0.26.0"
【第三步:使用CoT方式进行数学推理验证】
我们先通过一个简单数学方程:4X+5=6X+7,验证一下 Qwen2.5-Math 的推理能力:
# Qwen2.5-Math-Eval-01.py
import os
from modelscope import AutoModelForCausalLM, AutoTokenizer
# 权重文件目录
model_dir = os.path.join('D:', os.path.sep, 'ModelSpace', 'Qwen2.5', 'Qwen2.5-Math-1.5B-Instruct')
print(f'权重目录: {model_dir}')
# 初始化模型
model = AutoModelForCausalLM.from_pretrained(
model_dir,
torch_dtype='auto',
device_map='auto',
local_files_only=True,
)
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained(
model_dir,
local_files_only=True,
)
# Prompt提示词
prompt = '请计算等式中的X值: 4X+5=6X+7'
messages = [
{'role': 'system', 'content': '你是一位数学专家,特别擅长解答数学题。'},
{'role': 'user', 'content': prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[text],
return_tensors='pt',
).to(model.device)
print(f'开始推理: {prompt}')
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
print('推理完成.')
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(
generated_ids,
skip_special_tokens=True,
)[0]
print(f'推理结果: {response}')
执行本 Python 程序:python Qwen2.5-Math-Eval-01.py,可以看到 Qwen2.5-Math 模型通过 CoT 的推理方式给出了结果:
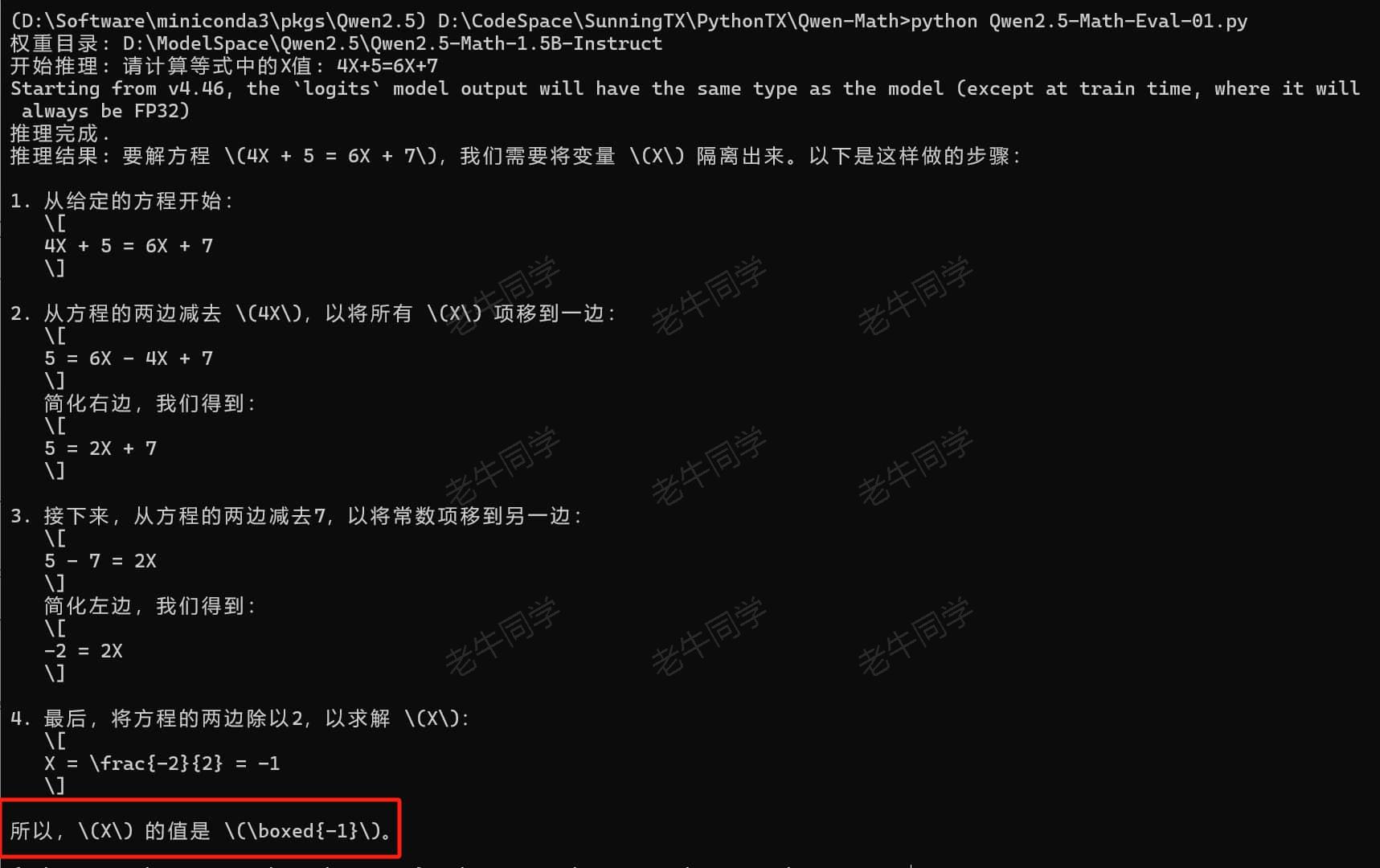
从最终结果来看,Qwen2.5-Math 推理过程很清晰,和我们的思维模型比较相近(唯一不足就是老牛同学电脑配置有点吃力)。
Qwen2.5-Math-72B 推理小学和初中奥数题挑战
上面一元一次方程只是简单体验,接下来我们通过奥数题目,对 Qwen2.5-Math 发出挑战。因此,我们将采用 Qwen2.5-Math-72B 目前地表最强数学模型,来解答小学和初中奥数题目。(那为啥没有高中奥数题呢?因为老牛同学有点担心自己不会,当不了裁判,因此就不好去挑战大模型了_)
我们将通过以下 3 个步骤,完成 Qwen2.5-Math 整个奥数题挑战验证:
【第一步:整理奥数题目,小学和初中分别 3 道题目】
老牛同学在网上分别找了 3 道奥数题目,我们通过 JSON 格式文件存储每道题目,每道题由等级、题目和答案组成:
[
{
"level": "小学",
"title": "小明和小红共有100元钱,小明比小红多20元。请问小明和小红分别有多少钱?",
"answer": "小明:60元,小红:40元"
}, {
"level": "小学",
"title": "小明围绕长方形操场跑步,跑了3圈共480米,操场的长比宽多20米。请问操场面积是多少平方米?",
"answer": "操场面积:1500平方米"
}, {
"level": "小学",
"title": "甲乙二人从两地沿直线同时相对而行,经过4小时,在距离中点4千米处相遇,甲比乙的速度快。请问甲每小时比乙快多少千米?",
"answer": "甲每小时比乙快:2千米"
}, {
"level": "初中",
"title": "小明和小红以同样多的钱买了同一种铅笔,小明要了13支,小红要了7支,小明又给小红0.6元钱。请问每支铅笔多少钱?",
"answer": "每支铅笔:0.2元"
}, {
"level": "初中",
"title": "父亲今年45岁,儿子今年15岁。请问多少年前父亲的年龄是儿子年龄的11倍?",
"answer": "12年前"
}, {
"level": "初中",
"title": "商店有一套运动服,成本价为100元,按标价的8折出售仍可获利20元。请问这套运动服的标价是多少元?",
"answer": "这套运动服的标价:150元"
}
]
【第二步:调用 Qwen2.5-Math-72B API 完成推理】
由于老牛同学本地推理比较慢,接下来将使用阿里云百炼平台 API 完成奥数推理。大家如果对自己电脑配置有信心的话,可以直接使用本地模型进行验证,可以免费完全接下来的推理。
有关阿里云百炼平台的介绍,可参考老牛同学之前的文章:太卷了,阿里云免费 1 个月大模型算力额度,玩转 Llama3.1/Qwen2 等训练推理
奥数题目的推理程序逻辑有 3 部分组成(Qwen2.5-Math-奥数推理.py):
- 读取奥数题目 JSON 文件,并循环每一道题
- 使用 Qwen2-Math 模型进行推理(或者:百炼平台 API),获取结果
- 存储奥数题目和推理结果到新文件,便于我们进行查看检测
如果大家是通过调用 API 完成推理,请先安装依赖包:pip install OpenAI
# Qwen2.5-Math-奥数推理.py
import os
import json
from openai import OpenAI
# 初始化客户端:提前配置好`DASHSCOPE_API_KEY`环境变量
client = OpenAI(
api_key=os.getenv('DASHSCOPE_API_KEY'),
base_url='https://dashscope.aliyuncs.com/compatible-mode/v1',
)
# 读取奥数题目
input_file = 'Qwen2.5-Math-奥数题目.json'
with open(input_file, 'r', encoding='utf-8') as file:
data = json.load(file)
# 循环每道题目,请求推理服务
output_data = []
for item in data:
print('')
print(f'奥数题目-> {item["title"]}')
print(f'期望答案-> {item["answer"]}')
completion = client.chat.completions.create(
model='qwen2.5-math-72b-instruct',
messages=[
{'role': 'system', 'content': '你是一位数学专家,特别擅长解答数学题。'},
{'role': 'user', 'content': item["title"]}
],
)
# 获取推理结果
result = json.loads(completion.model_dump_json())
content = result['choices'][0]['message']['content']
print(f'推理结果-> {content}')
# 暂存结果,后面统一存储到文件
output = {
'level': item['level'],
'title': item['title'],
'answer': item['answer'],
'result': content
}
output_data.append(output)
print('')
# 保存推理结果
output_file = 'Qwen2.5-Math-推理结果.md'
with open(output_file, "w", encoding="utf-8") as file:
for output in output_data:
file.write(f'{output["level"]}题目:{output["title"]}\n\n期望答案:{output["answer"]}\n\n')
file.write(f'{output["result"]}\n\n---\n\n')
Qwen2.5-Math-72B 果然没有让人失望,推理过程较快,并且推理的每一步都清晰明了:
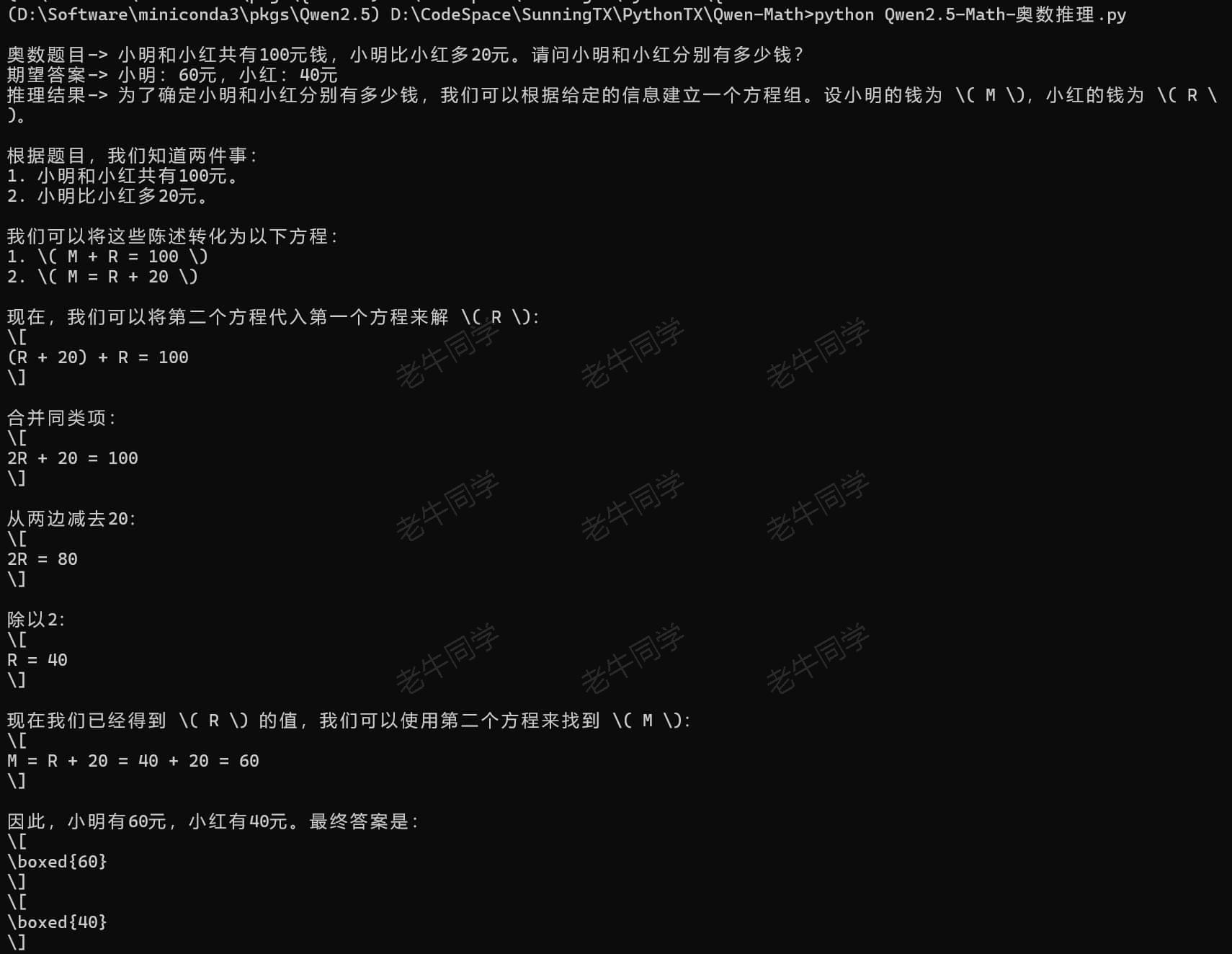
【第三步:验证推理结果的正确性,给出评分】
最后一步,我们打开 Qwen2.5-Math-72B 推理结果文件Qwen2.5-Math-推理结果.md,确定其准确率:100%(奥数题全对)

说实话,老牛同学还是挺吃惊的,它的推理速度,比老牛同学要快得多,并且推理的步骤都非常清晰明了。
对于有娃的朋友们,如果您在辅导家庭作业感到头疼的话,Qwen2.5-Math 赶紧使用起来吧,让我们真正体验一下父慈子孝的和谐乐趣~
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









