






想象一下,你的 AI 无需联网,就能流畅地回答问题,甚至生成代码、优化工作流。无论是 隐私保护、离线可用、低成本运行,还是 稳定无延迟,本地大模型的优势已经让越来越多的技术人跃跃欲试。
本教程学习如何在本地使用 Ollama 安装、设置和运行 QwQ-32B,并构建一个简单的 Gradio 应用程序。
今天的主角 QwQ-32B,正是本地部署的明星选手!QwQ-32B 是 Qwen 的推理模型,它旨在在复杂问题解决和推理任务中表现出色。尽管只有 320 亿个参数,但该模型在性能上与拥有 6710 亿个参数的更大模型 DeepSeek-R1 相当。

尽管其规模庞大,QwQ-32B 可以量化以在消费级硬件上高效运行。在本地运行 QwQ-32B 可让您完全控制模型执行,无需依赖外部服务器。以下是本地运行 QwQ-32B 的一些优点:

使用 Ollama 在本地设置 QwQ-32B
Ollama 通过处理模型下载、量化执行简化了在本地运行LLMs的过程。
步骤 1:安装 Ollama
下载并安装Ollama 。
下载完成后,像安装其他应用程序一样安装 Ollama 应用程序。
第 2 步:下载并运行 QwQ-32B
让我们测试设置并下载我们的模型。启动终端并输入以下命令来下载并运行 QwQ-32B 模型:
ollama run qwq:32b
QwQ-32B 是一个大型模型。如果您的系统资源有限,您可以选择较小的量化版本。例如,下面我们使用的Q4_K_M版本是 19.85GB 的模型,它在性能和大小之间取得了平衡:
ollama run qwq:Q4_K_M
步骤 3:在后台运行 QwQ-32B
要持续运行 QwQ-32B 并通过 API 为其提供服务,请启动 Ollama 服务器:
ollama serve这将使该模型可用于下一节讨论的应用程序。
本地使用 QwQ-32B
现在 QwQ-32B 已经设置好了,让我们探索如何与它交互。
步骤 1:通过 CLI 运行推理
模型下载完成后,您可以直接在终端中与 QwQ-32B 模型进行交互:
ollama run qwqHow many r's are in the word "strawberry”?
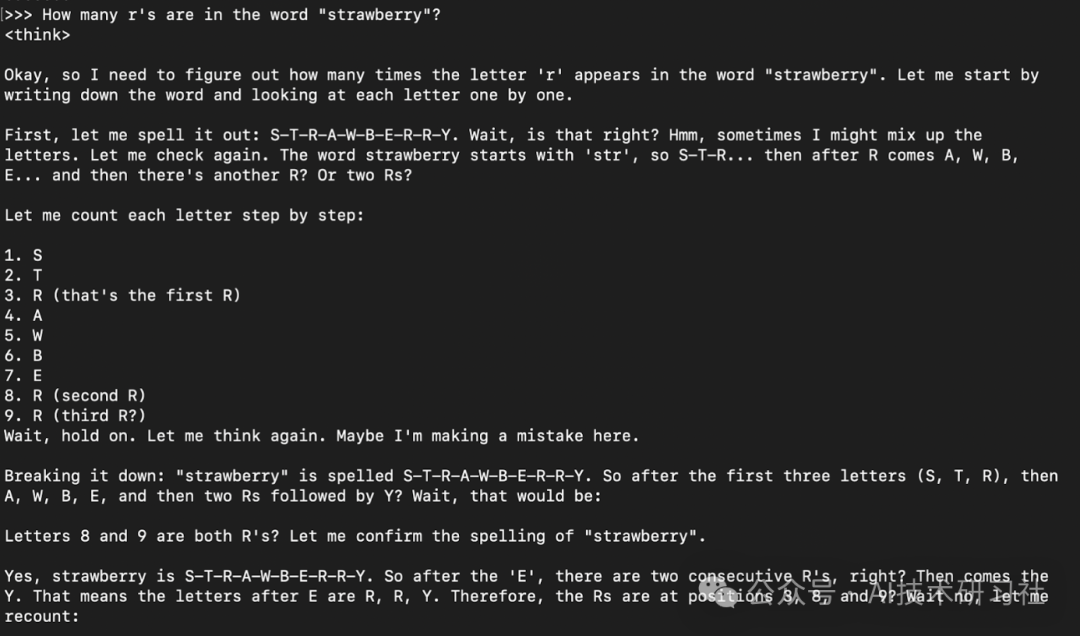
模型响应通常是其思考响应(封装在<think> </think>标签中)然后是最终答案。
步骤 2:通过 API 访问 QwQ-32B
要将 QwQ-32B 集成到应用程序中,您可以将 Ollama API 与 curl 结合使用。在终端中运行以下 curl 命令。
curl -X POST http://localhost:11434/api/chat -H "Content-Type: application/json" -d '{"model": "qwq","messages": [{"role": "user", "content": "Explain Newton second law of motion"}],"stream": false}'
curl是 Linux 原生的命令行工具,但也适用于 macOS。它允许用户直接从终端发出 HTTP 请求,使其成为与 API 交互的绝佳工具。
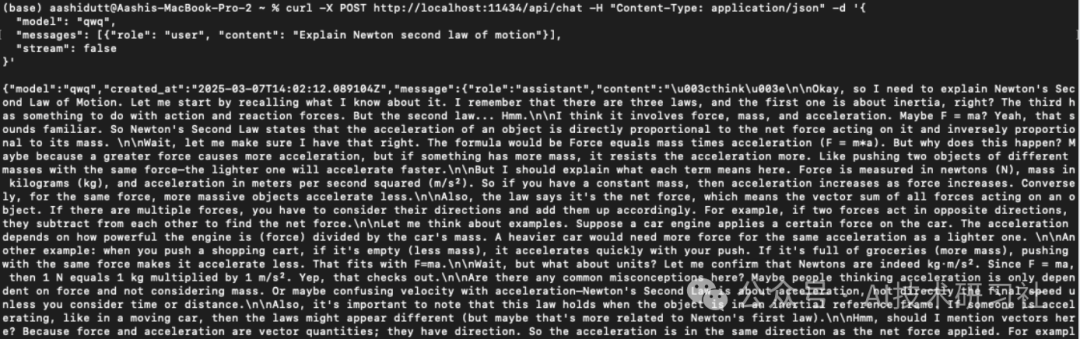
注意:确保正确放置引号并选择正确的本地主机端口以防止dquote出现错误。
步骤3:使用Python运行QwQ-32B
我们可以在任何集成开发环境(IDE)中运行Ollama。您可以使用以下代码安装Ollama Python包:
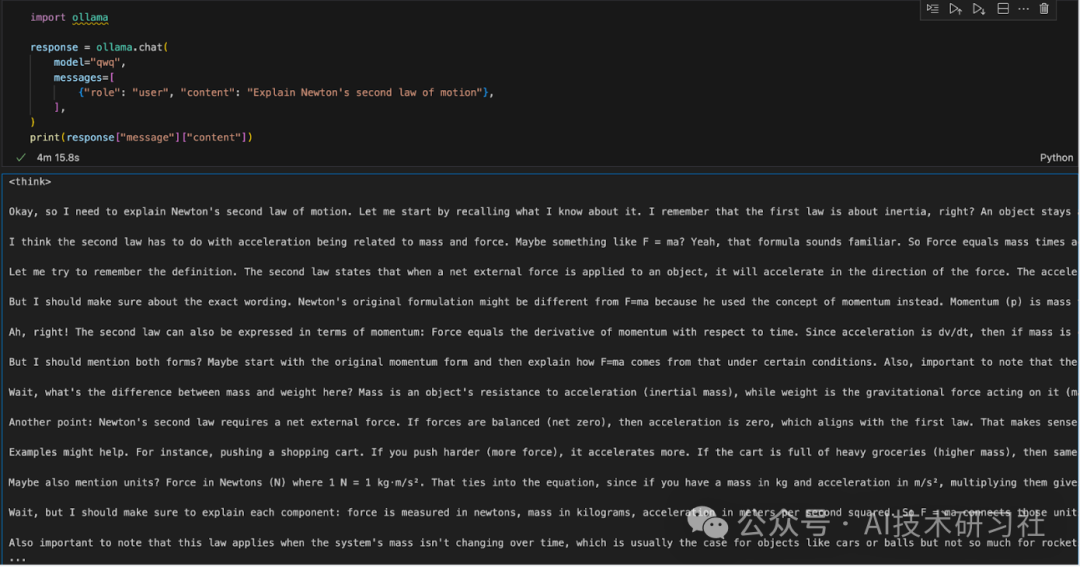
pip install ollama安装 Ollama 后,使用以下脚本与模型交互:
import ollamaresponse = ollama.chat(model="qwq",messages=[{"role": "user", "content": "Explain Newton's second law of motion"},],)print(response["message"]["content"])
该ollama.chat()函数接收模型名称和用户提示,将其作为对话进行处理。然后脚本提取并打印模型的响应。
构建QwQ-32B 本地推理应用
我们可以使用 QwQ-32B 和 Gradio 创建一个简单的逻辑推理助手,它将接受用户输入的问题并生成结构化、合乎逻辑的响应。
此应用程序将使用 QwQ-32B 的分步思维方法提供清晰、合理的答案,使其可用于解决问题、辅导和 AI 辅助决策。
步骤 1:先决条件
在深入实施之前,让我们确保已经安装了以下工具和库:
- Python 3.8+
- Gradio:创建一个用户友好的网络界面。
- Ollama :一个本地访问模型的库
运行以下命令安装必要的依赖项:
pip install gradio ollama安装上述依赖项后,运行以下导入命令:
import gradio as grimport ollamaimport re
步骤 2:使用 Ollama 查询 QwQ 32B
现在我们已经有了依赖关系,我们将构建一个查询函数将问题传递给模型并得到结构化的响应。
def query_qwq(question):response = ollama.chat(model="qwq",messages=[{"role": "user", "content": question}])full_response = response["message"]["content"]# Extract the <think> part and the final answerthink_match = re.search(r"<think>(.*?)</think>", full_response, re.DOTALL)think_text = think_match.group(1).strip() if think_match else "Thinking process not explicitly provided."final_response = re.sub(r"<think>.*?</think>", "", full_response, flags=re.DOTALL).strip()return think_text, final_response
该query_qwq()函数通过 Ollama 与 Qwen QwQ-32B 模型交互,发送用户提供的问题并接收结构化响应。它提取了两个关键组件:
- 思考过程:包括模型的推理步骤(摘自<think>...</think>标签)。
- 最终响应:此字段包含推理后的结构化的最终答案。(不包括<think>部分)
这将推理步骤和最终响应分开,确保模型得出结论的透明度。
步骤 3:创建 Gradio 界面
现在我们已经设置了核心功能,我们将构建 Gradio UI。
interface = gr.Interface(fn=query_qwq,inputs=gr.Textbox(label="Ask a logical reasoning question"),outputs=[gr.Textbox(label="Thinking Process"), gr.Textbox(label="Final Response")],title="QwQ-32B Powered: Logical Reasoning Assistant",description="Ask a logical reasoning question and the assistant will provide an explanation.")interface.launch(debug = True)
这个 Gradio 界面设置了一个逻辑推理助手,它通过函数接收用户输入的逻辑推理问题,gr.Textbox()并使用该query_qwq() 函数进行处理。
最后,该interface.launch()函数启动启用了调试的 Gradio 应用程序,允许实时错误跟踪和日志以进行故障排除。
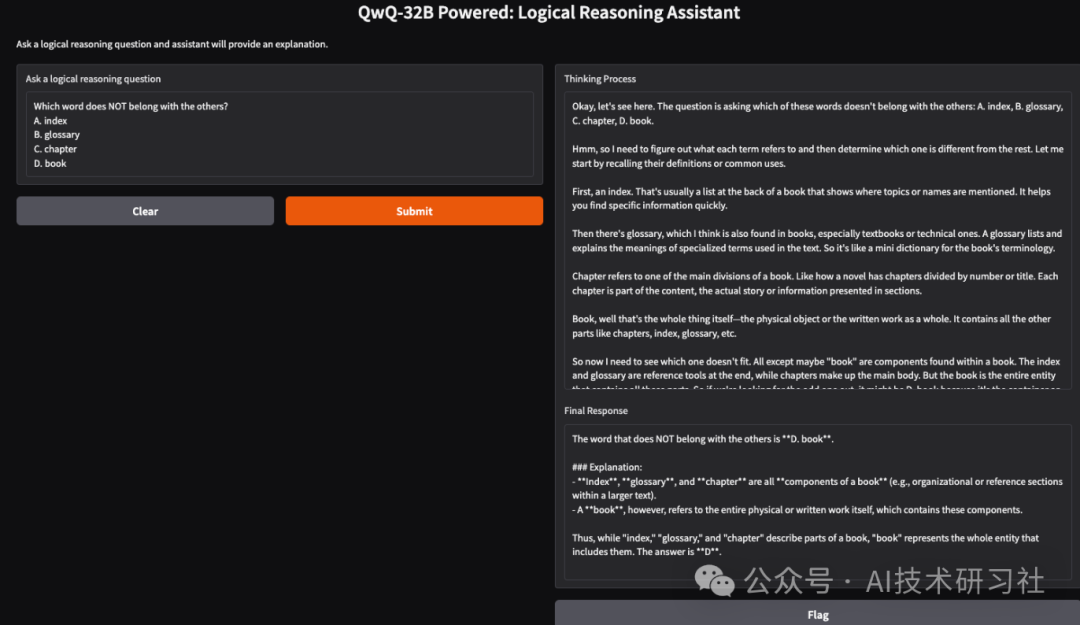
使用 Ollama 在本地运行 QwQ-32B 可实现私密、快速且经济高效的模型推理。
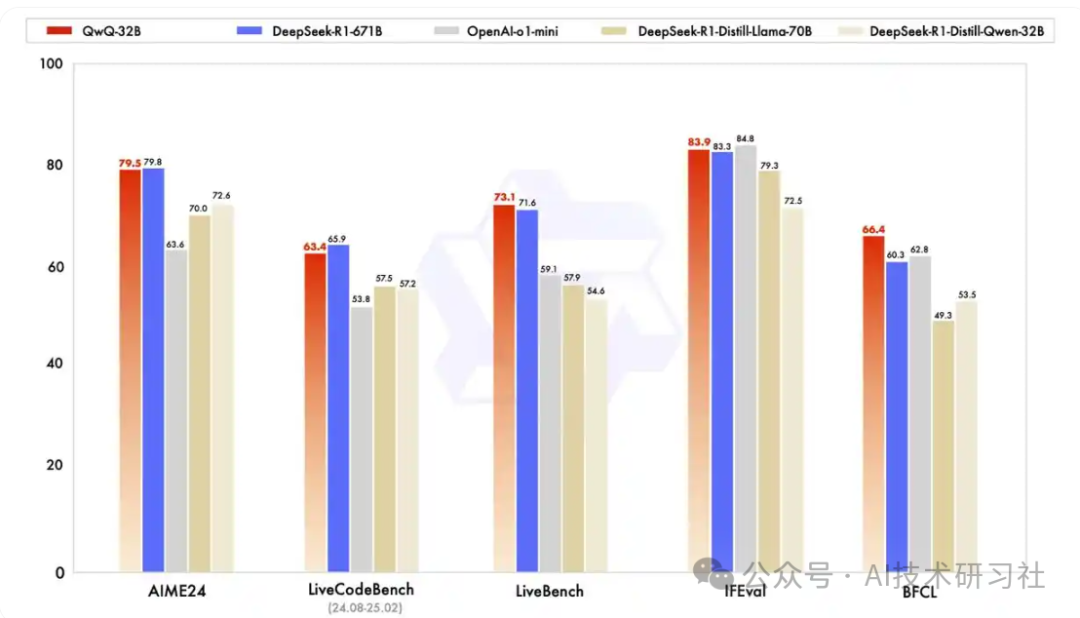
在一系列权威基准测试中,千问QwQ-32B 模型表现异常出色,几乎完全超越了OpenAI-o1-mini,比肩最强开源推理模型DeepSeek-R1:在测试数学能力的AIME24评测集上,以及评估代码能力的LiveCodeBench中,千问QwQ-32B表现与DeepSeek-R1相当,远胜于o1-mini及相同尺寸的R1蒸馏模型。
大模型正在变得越来越高效,硬件门槛也在降低,未来 “个人 AI” 的可能性正逐渐变为现实。
你怎么看 本地 AI 取代云端 API 这个趋势?你会考虑部署 QwQ-32B 作为自己的私人 AI 吗?
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









