






目录
不行我还是忍不住想吐槽:我使用的工具是pycharm,出现了导入不了PCV库和VLFeat开源工具包,命令行添加还是pycharm导入都不行!!!我还特地换成了anaconda的python版本,还是不行。好吧!!!我妥协了,我用的是手动下载PCV和VLFeat,但是!!!我不知道怎么把PCV库放进pycharm里面(爆哭,我实现的需要什么就把里面的函数取出来放到同一个文件夹进行调用)。至于VLFeat,参考需要注意的点整一波就好了(为了这个作业,我真的会爆哭)
附:匹配地理标记需要用到GraphViz的pydot工具包,加油,打工人!!!
一、Harris角点检测器
Harris角点检测算法的主要思想:如果像素周围显示存在多于一个方向的边,我们认为该点为兴趣点,该点称为角点。图像域 中点 x上的对称半正定矩阵=
定义为:
 其中
其中为包含导数
和
的图像梯度。由于该定义,
的秩为1,特征值为
=
和
=0。现在对于图像的每一个像素,都可以计算出该矩阵。
选择权重矩阵W(通常是高斯滤波器),可以得到卷积: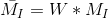 该卷积的目的是得到
该卷积的目的是得到在周围像素上的局部平均。计算出的矩阵
称为Harris矩阵。W的宽度决定了在像素X周围的感兴趣区域。像这样在区域附近对矩阵
取平均的原因是,特征值会依赖于局部图像特性而变化。如果图像的梯度在该区域变化,那么
的第二个特征值不再为0.如果图像的梯度没有变化,
特征值也不变。
取决于该区域的值,Harris矩阵
的特征值有三种情况:
1,如果和
都是很大的正数,则该x点为角点。
2,如果很大,
0,则该区域内存在一个边,区域内平均
的特征值不会变化太大;
3,如果0,该区域为空。
我们可以在角点检测过程中抑制噪声强度
from scipy.ndimage import filters
from PIL import Image
from pylab import *
from numpy import *
# import numba as nb
# @nb.jit()
def compute_harris_response(im, sigma=3):
"""在一副灰度图像中,对每个像素计算Harris角点检测器响应函数"""
# 计算导数
imx = zeros(im.shape)
filters.gaussian_filter(im, (sigma, sigma), (0, 1), imx)
imy = zeros(im.shape)
filters.gaussian_filter(im, (sigma, sigma), (1, 0), imy)
# 计算Harris矩阵的分量
Wxx = filters.gaussian_filter(imx * imx, sigma)
Wxy = filters.gaussian_filter(imx * imy, sigma)
Wyy = filters.gaussian_filter(imy * imy, sigma)
# 计算特征值和迹
Wdet = Wxx * Wyy - Wxy ** 2
Wtr = Wxx + Wyy
return Wdet / Wtr
# 阈值更改为0.01,0.05,0.1
def get_harris_points(harrisim,min_dist=10,threshold=0.1):
'''从一幅Harris响应图像中返回角点。min_dist为分割角点和图像边界的最少像素数目'''
# 寻找高于阈值的候选角点
corner_threshold = harrisim.max() * threshold
harrisim_t = (harrisim > corner_threshold) * 1
# 得到候选点的坐标
coords = array(harrisim_t.nonzero()).T
# 以及它们的Harris响应值
candidate_values = [harrisim[c[0],c[1]] for c in coords]
# 对候选点按照Harris响应值进行排序
index = argsort(candidate_values)
# 将可行点的位置保存到数组中
allowed_locations = zeros(harrisim.shape)
allowed_locations[min_dist:-min_dist,min_dist:-min_dist] = 1
# 按照min_distance原则,选择最佳Harris点
filtered_coords = []
for i in index:
if allowed_locations[coords[i,0],coords[i,1]] == 1:
filtered_coords.append(coords[i])
allowed_locations[(coords[i,0]-min_dist):(coords[i,0]+min_dist),
(coords[i,1]-min_dist):(coords[i,1]+min_dist)] = 0
return filtered_coords
def plot_harris_points(image,filtered_coords):
'''绘制图像中检测到的角点'''
figure()
gray()
imshow(image)
plot([p[1] for p in filtered_coords],[p[0] for p in filtered_coords],'*')
axis('off')
show()
if __name__ == '__main__':
im = array(Image.open(r'D:\PyCharmProjects\one\image\JMU.jpg').convert('L'))
harrisim = compute_harris_response(im)
filtered_coords = get_harris_points(harrisim, 6)
plot_harris_points(im, filtered_coords)



第一幅阈值为0.1,第二幅阈值为0.05,第三幅阈值为0.01
在图像中寻找对应点
Harris角点检测仅仅能检测出图像中的兴趣点,但是没有给出通过比较图像间的兴趣点来寻找匹配角点的方法。我们需要在每个点加上描绘子信息。
并给出一个比较这些描述子的方法。
兴趣点描绘子是分配给兴趣点的一个向量,描绘该点附近的图像的表观信息。描述子越好,寻找到的对应点越好。我们用对应点或者点的对应来描述相同物体和场景点在不同图像上形成的像素点。
Harris角点的描述子通常是由周围图像像素块的灰度值,以及用于比较的归一化互相关矩阵构成的。图像的像素块由以该像素点为中心的周围矩阵部分图像构成。
通常,两个(相同大小)像素块和
的相关矩阵定义为:
![]()
其中,函数f随着相关方法的变化而变化。上式取像素块中所有像素位置x的和。对于互相关矩阵,函数f (,
)=
*
,因此,c(
,
)=
*,其中*表示向量乘法(按照行或者列堆积的像素)。c(
,
)的值越大,像素块
和
的相似度越高。
归一化的互相关矩阵是互相关矩阵的一种变形,可以定义为:

其中,n为像素块中像素的数目,和
表示每个像素块中平均像素值强度,
和
分别表示每个像素块中的标准差。通过减去均值和除以标准差,该方法对图像亮度变化具有稳健性。
from pylab import *
from PIL import Image
import harris
from imtools import imresize
im1=array(Image.open('C:/Users/Administrator/Desktop/shui.jpg').convert('L'))
im2=array(Image.open('C:/Users/Administrator/Desktop/guo.jpg').convert('L'))
im1 = imresize(im1, (im1.shape[1]//2, im1.shape[0]//2))
im2 = imresize(im2, (im2.shape[1]//2, im2.shape[0]//2))
wid = 5
harrisim = harris.compute_harris_response(im1, 5)
filtered_coords1 = harris.get_harris_points(harrisim, wid+1)
d1 = harris.get_descriptors(im1, filtered_coords1, wid)
harrisim = harris.compute_harris_response(im2, 5)
filtered_coords2 = harris.get_harris_points(harrisim, wid+1)
d2 = harris.get_descriptors(im2, filtered_coords2, wid)
print ('starting matching')
matches = harris.match_twosided(d1, d2)
figure()
gray()
harris.plot_matches(im1, im2, filtered_coords1, filtered_coords2, matches)
show()

该算法存在一些不正确的匹配。这是因为,与现代的一些方法相比,图像像素块的互相关矩阵具有较弱的描述性。实际运用中,我们通常使用更稳健的方法来处理这些对应匹配 。这些描述符还有一个问题,它们不具有尺度不变性和旋转性,而算法中像素块的大小也会影响对应匹配的结果。
二、SLFT(尺度不变特征变换)
SLFT(尺度不变特征变换)是过去十年中最成功的图像局部描述子之一。SIFT特征包括兴趣点检测器和描述子。SIFT描述子具有非常强的稳定性,对于尺度、旋转和亮度都具有不变性,可以用于三维视角和噪声的可靠匹配。
1.兴趣点
SIFT 特征使用高斯差分函数来定位兴趣点:![]()
其中, 是上一章中介绍的二维高斯核,
是使用
模糊的灰度图像,κ 是决定相差尺度的常数。兴趣点是在图像位置和尺度变化下 D(x,σ) 的最大值和最小值点。这些候选位置点通过滤波去除不稳定点。基于一些准则,比如认为低对比度和位于边上的点不是兴趣点,我们可以去除一些候选兴趣点。
2.描述子
上面讨论的兴趣点,位置描述子给出了兴趣点的位置和尺度信息。为了实现旋转不变性,基于每个点周围图像梯度的方向和大小,SIFT描述子又引入了方向。SIFT描述子使用主方向描述参考方向。主方向使用方向直方图(以大小为权重)来度量。
下面我们基于位置,尺度和方向信息来计算描述子。为了对图像亮度具有稳健性,SIFT描述子使用图像梯度。SIFT描述子在每个像素点附近选取子区域网格,在每个子区域内计算图像梯度方向直方图。每个子区域的直方图拼接起来组成描述子向量。SIFT描述子的标准设置使用4*4 的子区域,每个子区域使用8个小区间的方向直方图。会产生共128个小区间的直方图(4*4*8=128)。

(a)一个围绕兴趣点的网络结构,其中网络已经按照梯度主方向进行了旋转;(b)在网格的一个子区域内构造梯度方向的8-bin直方图;(c)在网格的每个子区域内提取直方图;(d)拼接直方图,得到一个长的特征向量
3.检测兴趣点
我们使用开源工具包VLFeat提供的二进制文件来计算图像的SIFT特征。VLFeat工具包的二进制文件可以在所有主要的平台上运行。VLFeat库是用C语言来写的,但是我们可以使用该库提供的命令行接口。
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
import sift
import harris
def process_image(imagename, resultname, params="--edge-thresh 10 --peak-thresh 5"):
"""处理一副图像,将结果保存到文件中"""
if imagename[-3:] != 'pgm':
im = Image.open(imagename).convert('L')
im.save('tmp.pgm')
imagename = 'tmp.pgm'
cmmd = str("sift " + imagename + " --output=" + resultname + " " + params)
os.system(cmmd)
print('processed', imagename, 'to', resultname)
def read_features_from_file(filename):
# 读取特征属性值,然后将其以矩阵的形式返回
f = loadtxt(filename)
return f[:, :4], f[:, 4:] # 特征位置,描述子
# 将特征位置和描述子保存到文件中
def write_features_to_file(filename, locs, desc):
savetxt(filename, hstack((locs, desc)))
def plot_features(im, locs, circle=False):
"""显示带有特征的图像,输入:im(数组图像),locs(每个特征的行,列,尺度和方向角度)"""
def draw_circle(c, r):
t = arange(0, 1.01, .01) * 2 * pi
x = r * cos(t) + c[0]
y = r * sin(t) + c[1]
plot(x,y,'b',linewidth=2)
imshow(im)
if circle:
for p in locs:
draw_circle(p[:2], p[2])
else:
plot(locs[:, 0], locs[:, 1], 'ob')
axis('off')
imname = 'D:\PyCharmProjects\one\image\JMU.jpg'
im1 = array(Image.open(imname).convert('L'))
sift.process_image(imname, 'JMU.sift')
l1, d1 = sift.read_features_from_file('JMU.sift')
figure()
gray()
sift.plot_features(im1, l1, circle=True)
show()

4.匹配描述子
对于将一幅图像中的特征匹配到另一幅图像的特征,一种稳健的准则是使用这两个特征距离和两个最匹配特征距离的比率。相比于图像中的其他特征,该准则保证能够找到足够相似的唯一特征。使用该方法可以使错误的匹配数降低。下面的代码实现了匹配函数。
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
from numpy import *
import os
import sift
def process_image(imagename, resultname, params="--edge-thresh 10 --peak-thresh 5"):
""" 处理一幅图像,然后将结果保存在文件中"""
if imagename[-3:] != 'pgm':
# 创建一个pgm文件
im = Image.open(imagename).convert('L')
im.save('tmp.pgm')
imagename = 'tmp.pgm'
cmmd = str("sift " + imagename + " --output=" + resultname + " " + params)
os.system(cmmd)
print('processed', imagename, 'to', resultname)
def read_features_from_file(filename):
"""读取特征属性值,然后将其以矩阵的形式返回"""
f = loadtxt(filename)
return f[:, :4], f[:, 4:] # 特征位置,描述子
def write_featrues_to_file(filename, locs, desc):
"""将特征位置和描述子保存到文件中"""
savetxt(filename, hstack((locs, desc)))
def plot_features(im, locs, circle=False):
"""显示带有特征的图像
输入:im(数组图像),locs(每个特征的行、列、尺度和朝向)"""
def draw_circle(c, r):
t = arange(0, 1.01, .01) * 2 * pi
x = r * cos(t) + c[0]
y = r * sin(t) + c[1]
plot(x, y, 'b', linewidth=2)
imshow(im)
if circle:
for p in locs:
draw_circle(p[:2], p[2])
else:
plot(locs[:, 0], locs[:, 1], 'ob')
axis('off')
def match(desc1, desc2):
"""对于第一幅图像中的每个描述子,选取其在第二幅图像中的匹配
输入:desc1(第一幅图像中的描述子),desc2(第二幅图像中的描述子)"""
desc1 = array([d / linalg.norm(d) for d in desc1])
desc2 = array([d / linalg.norm(d) for d in desc2])
dist_ratio = 0.6
desc1_size = desc1.shape
matchscores = zeros((desc1_size[0], 1), 'int')
desc2t = desc2.T # 预先计算矩阵转置
for i in range(desc1_size[0]):
dotprods = dot(desc1[i, :], desc2t) # 向量点乘
dotprods = 0.9999 * dotprods
# 反余弦和反排序,返回第二幅图像中特征的索引
indx = argsort(arccos(dotprods))
# 检查最近邻的角度是否小于dist_ratio乘以第二近邻的角度
if arccos(dotprods)[indx[0]] < dist_ratio * arccos(dotprods)[indx[1]]:
matchscores[i] = int(indx[0])
return matchscores
def match_twosided(desc1, desc2):
"""双向对称版本的match()"""
matches_12 = match(desc1, desc2)
matches_21 = match(desc2, desc1)
ndx_12 = matches_12.nonzero()[0]
# 去除不对称的匹配
for n in ndx_12:
if matches_21[int(matches_12[n])] != n:
matches_12[n] = 0
return matches_12
def appendimages(im1, im2):
"""返回将两幅图像并排拼接成的一幅新图像"""
# 选取具有最少行数的图像,然后填充足够的空行
rows1 = im1.shape[0]
rows2 = im2.shape[0]
if rows1 < rows2:
im1 = concatenate((im1, zeros((rows2 - rows1, im1.shape[1]))), axis=0)
elif rows1 > rows2:
im2 = concatenate((im2, zeros((rows1 - rows2, im2.shape[1]))), axis=0)
return concatenate((im1, im2), axis=1)
def plot_matches(im1, im2, locs1, locs2, matchscores, show_below=True):
""" 显示一幅带有连接匹配之间连线的图片
输入:im1, im2(数组图像), locs1,locs2(特征位置),matchscores(match()的输出),
show_below(如果图像应该显示在匹配的下方)
"""
im3 = appendimages(im1, im2)
if show_below:
im3 = vstack((im3, im3))
imshow(im3)
cols1 = im1.shape[1]
for i in range(len(matchscores)):
if matchscores[i] > 0:
plot([locs1[i, 0], locs2[matchscores[i, 0], 0] + cols1], [locs1[i, 1], locs2[matchscores[i, 0], 1]], 'c')
axis('off')
im1f = r'D:\PyCharmProjects\1.jpg'
im2f = r'D:\PyCharmProjects\2.jpg'
im1 = array(Image.open(im1f))
im2 = array(Image.open(im2f))
process_image(im1f, 'JMU1.sift')
l1, d1 = read_features_from_file('JMU1.sift')
figure()
gray()
subplot(121)
plot_features(im1, l1, circle=False)
process_image(im2f, 'JMU2.sift')
l2, d2 = sift.read_features_from_file('JMU2.sift')
subplot(122)
plot_features(im2, l2, circle=False)
matches = match_twosided(d1, d2)
print('{} matches'.format(len(matches.nonzero()[0])))
figure()
gray()
plot_matches(im1, im2, l1, l2, matches, show_below=True)
show()


三.匹配地理标记图像
我们通过图像间是否具有匹配的局部描述子来定义图像间的连接,然后可视化这些连接情况
# -*- coding: utf-8 -*-
from pylab import *
from PIL import Image
import sift
import imtools
import pydot
""" This is the example graph illustration of matching images from Figure 2-10.
To download the images, see ch2_download_panoramio.py."""
# download_path = "panoimages" # set this to the path where you downloaded the panoramio images
# path = "/FULLPATH/panoimages/" # path to save thumbnails (pydot needs the full system path)
download_path = "D:\PyCharmProjects\image" # set this to the path where you downloaded the panoramio images
path = "D:\PyCharmProjects\image" # path to save thumbnails (pydot needs the full system path)
# list of downloaded filenames
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
# extract features
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print('comparing ', imlist[i], imlist[j])
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print('number of matches = ', nbr_matches)
matchscores[i, j] = nbr_matches
print("The match scores is: \n", matchscores)
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
# 可视化
threshold = 2 # min number of matches needed to create link
g = pydot.Dot(graph_type='graph')
root = "D:\\PyCharmProjects\\image"
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = root + str(i) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = root + str(j) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
g.write_png('jmu.png')(代码是对的,但是不知道为什么跑图跑不出来)














 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









