







| 序号 | 名称 |
|---|---|
| 1 | 第一章 项目背景与实现思路 【农村人居环境整治】 |
| 2 | 第二章 Anaconda+Pycharm+Yolov8开发环境搭建与检测验证 |
| 3 | 第三章 AI垃圾监测识别系统【系统实施方案+数据集制作+模型训练】 |
| 4 | 第四章 AI垃圾监测识别系统【模型导出+模型使用+系统展现】 |
| 5 | 第五章 持续更新 |
| ` | |
| ` |
第三章 AI垃圾监测识别系统【系统实施方案+数据集制作+模型训练】
本章训练数据及标注工具夸克网盘下载地址
文章目录
系统实施方案
一、系统概述
本垃圾监测系统旨在利用先进的 AI 摄像头和无人机巡逻技术,对农村村庄公共区域及垃圾收集点的垃圾状况进行实时、精准的监测与分析,以便及时发现垃圾堆积、乱扔乱放等问题,并采取相应的清理和管理措施,从而有效提升农村人居环境质量,推动美丽乡村建设。
二、硬件部署
AI 摄像头安装在村庄的主要道路、广场、公园等公共区域,每隔一定距离(例如 100 - 200 米,根据村庄实际情况调整)安装具备高清图像采集功能和智能分析能力的 AI 摄像头,确保对公共区域的全面覆盖。摄像头应安装在高处,如路灯杆、建筑物外墙等位置,以获取更广阔的监测视野,并避免被人为破坏或遮挡。在每个垃圾收集点,安装专门针对垃圾监测的 AI 摄像头,重点监控垃圾的堆放情况,包括垃圾桶是否满溢、周边是否有垃圾散落等。摄像头的角度和位置应能够清晰捕捉到垃圾收集点的全貌,并保证在不同光照条件下(白天、夜晚、阴天等)都能正常工作。
无人机巡逻系统配置:配备若干台适合农村环境飞行的无人机,无人机应搭载高清摄像头、GPS 定位系统、图传设备以及具备图像识别功能的边缘计算模块(或与地面控制中心的 AI 分析系统实时连接)。规划合理的无人机巡逻路线,确保能够定期对村庄的各个角落,尤其是一些较为偏远、不易通过摄像头直接监测到的区域进行全面巡查。巡逻频率可根据村庄的垃圾产生情况和管理需求设定,例如每周进行 2 - 3 次全域巡逻,重点区域(如垃圾易堆积的河道附近、农田交界处等)可适当增加巡逻次数。
三、软件功能
图像识别与分析:基于深度学习算法,对 AI 摄像头和无人机采集的图像进行实时分析,识别出不同类型的垃圾,如生活垃圾(塑料瓶、纸张、果皮等)、建筑垃圾(砖块、石块、废弃木材等)、农业废弃物(秸秆、农药瓶等)。同时,能够判断垃圾的堆积体积、分布范围以及是否存在违规倾倒等情况。利用目标检测技术,检测垃圾桶的状态,包括是否满溢、有无损坏、是否被移位等,并及时发出警报信息。
数据存储与管理:建立一个专门的数据库,用于存储所有摄像头和无人机采集到的图像数据、分析结果以及相关的时间、地点等信息。这些数据应按照一定的时间序列和地理位置进行分类存储,以便后续查询、统计和分析使用。开发数据管理平台,具备数据录入、查询、导出、备份等功能,方便管理人员对垃圾监测数据进行日常管理和维护。同时,能够生成各类数据报表和图表,直观展示村庄垃圾的产生趋势、分布情况以及清理效果等信息,为决策制定提供数据支持。
实时预警与通知:当系统检测到垃圾堆积超过预设阈值、垃圾桶满溢或者发现有新的垃圾堆放点时,立即通过短信、APP 推送等方式向村庄管理人员、清洁人员发送预警信息,告知垃圾问题的具体位置和严重程度,以便他们能够及时安排清理工作。预警信息应包含详细的地理位置信息(可通过地图链接直接导航到问题地点)、问题描述(如垃圾类型、堆积面积等)以及建议的处理措施,确保接收人员能够快速了解情况并采取有效的应对措施。
四、人员培训与操作流程
人员培训:对村庄管理人员和清洁人员进行系统的培训,使其熟悉垃圾监测 AI 系统的操作流程、预警信息接收与处理方式、数据分析报告的解读等内容。培训方式可以包括现场演示、视频教程、操作手册发放以及实际操作演练等,确保相关人员能够熟练掌握系统的使用方法。针对无人机操作人员,进行专业的飞行培训和安全知识教育,使其具备熟练的无人机操控技能,能够按照预定的巡逻路线安全、高效地完成飞行任务。同时,培训无人机的日常维护和保养知识,确保无人机处于良好的运行状态。
操作流程
日常监测阶段:AI 摄像头和无人机按照设定的参数和程序自动进行图像采集和数据传输。系统自动对采集到的图像进行分析处理,将监测结果实时存储到数据库中,并与预设的阈值进行对比。如未发现异常情况,系统继续进行下一轮监测;若发现垃圾问题,则进入预警通知流程。
预警处理阶段:当管理人员和清洁人员收到预警信息后,应立即响应,根据预警内容组织清理工作。清理人员到达现场后,通过手机 APP 或其他终端设备对垃圾清理情况进行拍照上传,系统自动更新该地点的垃圾监测状态,确认问题是否得到解决。如问题未彻底解决,系统将持续发出预警,直至问题得到妥善处理。
数据分析与报告阶段:定期(如每月或每季度)对垃圾监测数据进行汇总分析,生成详细的数据分析报告,包括垃圾产生量的变化趋势、不同区域的垃圾分布情况、各类垃圾的占比等信息。管理人员根据数据分析报告,评估当前垃圾管理措施的有效性,制定针对性的改进方案,如调整垃圾桶的分布位置、增加垃圾清理频次、加强环保宣传教育等。
五、系统维护与升级
硬件维护:定期对 AI 摄像头和无人机进行巡检,检查设备的外观是否损坏、安装是否牢固、电源供应是否正常等。对于出现故障的设备,及时进行维修或更换,确保硬件系统的稳定运行。清洁摄像头镜头和无人机的机身、螺旋桨等部件,防止灰尘、污垢等影响图像采集质量和飞行性能。同时,对无人机的电池进行定期充放电维护,延长电池使用寿命。
软件升级:关注 AI 图像识别算法、数据分析模型以及系统软件的更新情况,及时从开发商处获取最新的软件版本,并进行升级安装。软件升级主要包括算法优化,以提高垃圾识别的准确率和速度;功能增强,如增加对新类型垃圾的识别能力、改进预警通知方式等;以及系统稳定性和兼容性的提升,确保系统能够适应不断变化的农村环境和技术发展需求。
通过以上方案的实施,利用 AI 摄像头和无人机巡逻系统实现对农村垃圾的全面、高效监测,为农村人居环境整治提供有力的技术支持,助力打造干净、整洁、美丽的乡村环境。你可以根据实际情况对上述方案进行进一步的细化和调整,如有其他具体要求或补充信息,欢迎评论区留言。
开始学习
经由对系统实施方案的研读,想必诸位已然明晰了该系统的架构组成以及人工智能在其中所承担的关键职能。此系统涵盖了无人机飞行操控、图像数据传输、人工智能图像解析等多个专业领域,并且不可避免地涉及到软硬件协同作业的复杂问题。然而,在本章节的学习进程中,我们将聚焦于人工智能图像分析这一核心板块(监控垃圾的堆放情况,包括垃圾桶是否满溢、周边是否有垃圾散落),深入探究如何运用特定的技术手段和算法来训练垃圾识别模型,进而实现对垃圾的精准、高效识别。至于系统所涉及的其他方面,诸如无人机飞行控制技术细节、图像传输过程中的优化策略以及软硬件结合时的调试与适配等内容,我们会在后续具备充足时间与精力的情况下,再进行详尽的补充与完善,以及构建对整个系统更为全面且深入的认知体系。
那么如何实现监控垃圾的堆放情况,包括垃圾桶是否满溢、周边是否有垃圾散落呢?
一,训练数据集制作
本系统功能主要是为了及时发现垃圾堆积、乱扔乱放等问题(本章先不讲垃圾分类识别的问题)。
1,数据准备
- 为了识别垃圾堆积问题准备了20张关于垃圾堆积的图,片并用ps软件图片处理为固定尺寸固定格式(我这里使用jpg格式,尺寸为640*640像素)。

- 为了识别垃圾桶的中的垃圾是否满准备了10张未满图片和10张已满的图片,并用ps软件图片处理为固定尺寸固定格式(我这里使用jpg格式,尺寸为640*640像素)。

2,数据标注
使用标注软件进行标注。我用LabelImg是图形图像注释工具。它是用Python编写的,并将Qt用于其
图形界面。
第一步:软件安装
Win下可以直接下载简易版exe文件,
下载地址:https://github.com/tzutalin/labelImg/releases
选择windows_v1.8.1.zip,下载并解压,直接双击exe文件点开即用,下载后,发个快捷方式到桌面就可了。

第二步:增加要标注的标签(我这里增加了”满“,”空“两个标签表示垃圾桶空或满)
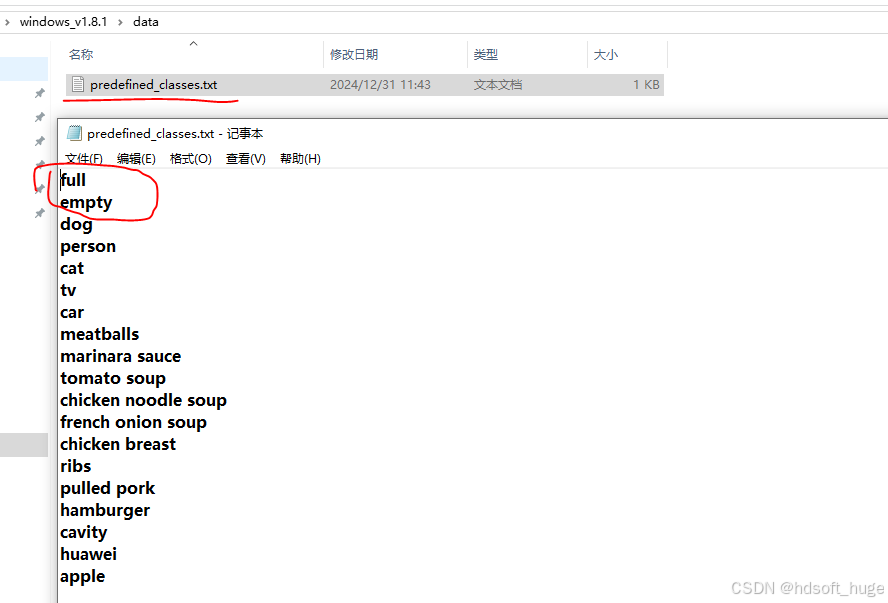
第三步:启动软件进行标注

标注完成
3,制作数据(处理为yolov8能够加载的数据集)
- 在ultralytics工程的datasets目录下创建一个自己的数据集目录 Identify_garbage
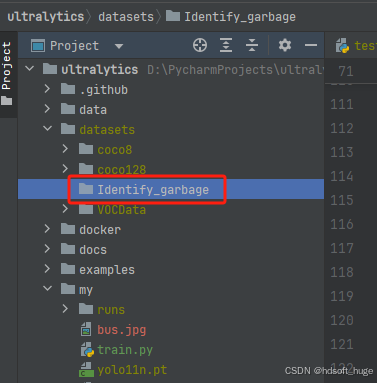
- 在 “Identify_garbage” 目录中,我们需要编写(CreateDataSet.py)用于创建数据目录结构的代码(当然也可以手动创建)
import os
if __name__ == '__main__':
# 获取当前路径
wd = os.getcwd()
# 创建相应VOC模式文件夹
voc_path = os.path.join(wd, "voc_dataset")
if not os.path.isdir(voc_path):
os.mkdir(voc_path)
#标签目录
annotation_dir = os.path.join(voc_path, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
#原始图片目录
image_dir = os.path.join(voc_path, "JPGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
#数据集划分
voc_file_dir = os.path.join(voc_path, "ImageSets/")
if not os.path.isdir(voc_file_dir):
os.mkdir(voc_file_dir)
#标签目录
if not os.path.exists(os.path.join(voc_path, 'Labels/')):
os.makedirs(os.path.join(voc_path, 'Labels'))
train_file = open(os.path.join(voc_path, "litter_train.txt"), 'a')
test_file = open(os.path.join(voc_path, "litter_test.txt"), 'a')
train_file.close()
test_file.close()
运行完成结果如下:
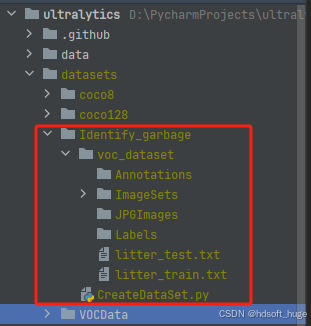
- 接下来所有原始图片拷贝至JPGImages目录下,XML标签文件拷贝到Annotations文件夹下

- 将 PascalVOC2格式的标注文件转换为 YOLO 格式标注的代码。尽管 LabelImg 工具本身支持直接输出 YOLO格式,但为了更清晰地展示数据处理过程,我们在这里仍选择了 PascalVOC2格式的标注文件进行转换操作。完成这些代码编写与数据转换后,下一章节我们将基于YOLO格式的数据来制作训练数据,以便后续深入开展相关模型的训练与研究工作。
编写代码VocToYolo.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
classes = ["full", "empty"]
def clear_hidden_files(path):
"""
清除指定路径下的隐藏文件。
参数:
path (str): 要清除隐藏文件的路径。
返回:
None
"""
# 获取指定路径下的所有文件和目录
dir_list = os.listdir(path)
# 遍历所有文件和目录
for i in dir_list:
# 获取文件或目录的绝对路径
abspath = os.path.join(os.path.abspath(path), i)
# 如果是文件
if os.path.isfile(abspath):
# 如果文件名以 "._" 开头,则删除该文件
if i.startswith("._"):
os.remove(abspath)
# 如果是目录,则递归调用 clear_hidden_files 函数
else:
clear_hidden_files(abspath)
def convert(size, box):
"""
将边界框的坐标从原始图像的尺寸转换为归一化的尺寸。
参数:
size (tuple): 包含图像宽度和高度的元组。
box (tuple): 表示边界框的四个坐标值的元组,格式为 (xmin, xmax, ymin, ymax)。
返回:
tuple: 包含归一化后的边界框中心坐标 (x, y) 以及宽度和高度 (w, h) 的元组。
"""
# 计算宽度和高度的缩放比例
dw = 1. / size[0]
dh = 1. / size[1]
# 计算边界框的中心点坐标
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
# 计算边界框的宽度和高度
w = box[1] - box[0]
h = box[3] - box[2]
# 将中心点坐标和宽度、高度进行归一化
x = x * dw
w = w * dw
y = y * dh
h = h * dh
# 返回归一化后的边界框坐标
return x, y, w, h
def convert_annotation(image_id, voc_labels, yolo_labels):
"""
将VOC格式的标注文件转换为YOLO格式的标注文件。
参数:
image_id (str): 图像ID。
voc_labels (str): VOC标注文件的路径。
yolo_labels (str): YOLO标注文件的路径。
返回:
None
"""
# 打开VOC标注文件
print(voc_labels)
in_file = open(os.path.join(voc_labels + '%s.xml') % image_id)
print(in_file)
# 打开YOLO标注文件
out_file = open(os.path.join(yolo_labels + '%s.txt') % image_id, 'w')
# 解析XML文件
tree = ET.parse(in_file)
# 获取XML文件的根节点
root = tree.getroot()
# 获取图像的尺寸
size = root.find('size')
# 打印图像的高度
print(size.find('height').text)
# 获取图像的宽度
w = int(size.find('width').text)
# 获取图像的高度
h = int(size.find('height').text)
# 遍历所有的object节点
for obj in root.iter('object'):
# 获取difficult节点的值
difficult = obj.find('difficult').text
# 获取name节点的值
cls = obj.find('name').text
# 如果类别不在classes列表中或者difficult的值为1,则跳过该object
if cls not in classes or int(difficult) == 1:
continue
# 获取类别的索引
cls_id = classes.index(cls)
# 获取bndbox节点
xml_box = obj.find('bndbox')
# 获取边界框的坐标
b = (float(xml_box.find('xmin').text), float(xml_box.find('xmax').text), float(xml_box.find('ymin').text),
float(xml_box.find('ymax').text))
# 将边界框的坐标转换为YOLO格式
bb = convert((w, h), b)
# 将转换后的坐标写入YOLO标注文件
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 关闭VOC标注文件
in_file.close()
# 关闭YOLO标注文件
out_file.close()
if __name__ == '__main__':
# 获取当前路径
wd = os.getcwd()
# 创建相应VOC模式文件夹
voc_path = os.path.join(wd, "voc_dataset")
if not os.path.isdir(voc_path):
os.mkdir(voc_path)
annotation_dir = os.path.join(voc_path, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(voc_path, "JPGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
voc_file_dir = os.path.join(voc_path, "ImageSets/")
if not os.path.isdir(voc_file_dir):
os.mkdir(voc_file_dir)
voc_file_dir = os.path.join(voc_file_dir, "Main/")
if not os.path.isdir(voc_file_dir):
os.mkdir(voc_file_dir)
VOC_train_file = open(os.path.join(voc_path, "ImageSets/Main/train.txt"), 'w')
VOC_test_file = open(os.path.join(voc_path, "ImageSets/Main/test.txt"), 'w')
VOC_train_file.close()
VOC_test_file.close()
if not os.path.exists(os.path.join(voc_path, 'Labels/')):
os.makedirs(os.path.join(voc_path, 'Labels'))
train_file = open(os.path.join(voc_path, "litter_train.txt"), 'a')
test_file = open(os.path.join(voc_path, "litter_test.txt"), 'a')
VOC_train_file = open(os.path.join(voc_path, "ImageSets/Main/train.txt"), 'a')
VOC_test_file = open(os.path.join(voc_path, "ImageSets/Main/test.txt"), 'a')
image_list = os.listdir(image_dir) # list image files
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
for i in range(0, len(image_list)):
path = os.path.join(image_dir, image_list[i])
if os.path.isfile(path):
image_path = image_dir + image_list[i]
image_name = image_list[i]
(name_without_extent, extent) = os.path.splitext(os.path.basename(image_path))
voc_name_without_extent, voc_extent = os.path.splitext(os.path.basename(image_name))
annotation_name = name_without_extent + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
probo = random.randint(1, 100)
print("Probobility: %d" % probo)
if (probo < 75):
print(annotation_path)
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
VOC_train_file.write(voc_name_without_extent + '\n')
yolo_labels_dir = os.path.join(voc_path, 'Labels/')
print(yolo_labels_dir)
convert_annotation(name_without_extent, annotation_dir, yolo_labels_dir)
else:
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
VOC_test_file.write(voc_name_without_extent + '\n')
yolo_labels_dir = os.path.join(voc_path, 'Labels/')
convert_annotation(name_without_extent, annotation_dir, yolo_labels_dir)
train_file.close()
test_file.close()
VOC_train_file.close()
VOC_test_file.close()
- 编写代码SubData.py 转好的数据分成训练集和验证集。
import os
import shutil
import random
ratio=0.1
img_dir= 'voc_dataset/JPGImages' #图片路径
label_dir= 'voc_dataset/labels' #生成的yolo格式的数据存放路径
train_img_dir= 'voc_dataset/images/train_litter' #训练集图片的存放路径
val_img_dir= 'voc_dataset/images/val_litter'
train_label_dir= 'voc_dataset/labels/train_litter' #训练集yolo格式数据的存放路径
val_label_dir= 'voc_dataset/labels/val_litter'
if not os.path.exists(train_img_dir):
os.makedirs(train_img_dir)
if not os.path.exists(val_img_dir):
os.makedirs(val_img_dir)
if not os.path.exists(train_label_dir):
os.makedirs(train_label_dir)
if not os.path.exists(val_label_dir):
os.makedirs(val_label_dir)
names=os.listdir(img_dir)
val_names=random.sample(names,int(len(names)*ratio))
for name in names:
if name in val_names:
shutil.copy(os.path.join(img_dir,name),os.path.join(val_img_dir,name))
shutil.copy(os.path.join(label_dir, name[:-4]+'.txt'), os.path.join(val_label_dir, name[:-4]+'.txt'))
else:
shutil.copy(os.path.join(img_dir, name), os.path.join(train_img_dir, name))
shutil.copy(os.path.join(label_dir, name[:-4] + '.txt'), os.path.join(train_label_dir, name[:-4] + '.txt'))
- 创建VOC.yaml文件
train: D:/PycharmProjects/ultralytics/datasets/Identify_garbage/voc_dataset/images/train_litter #训练集路径
val: D:/PycharmProjects/ultralytics/datasets/Identify_garbage/voc_dataset/images/val_litter #验证集路径
test: D:/PycharmProjects/ultralytics/datasets/Identify_garbage/voc_dataset/images/val_litter #测试集路径
# Classes 标注的类型
names:
0: "full"
1: "empty"
- 开始训练
cd D:\PycharmProjects\ultralytics\datasets\litter\voc_dataset #cd 到自己的数据集目录下
yolo train data=VOC.yaml model=yolov8n.pt #开始训练

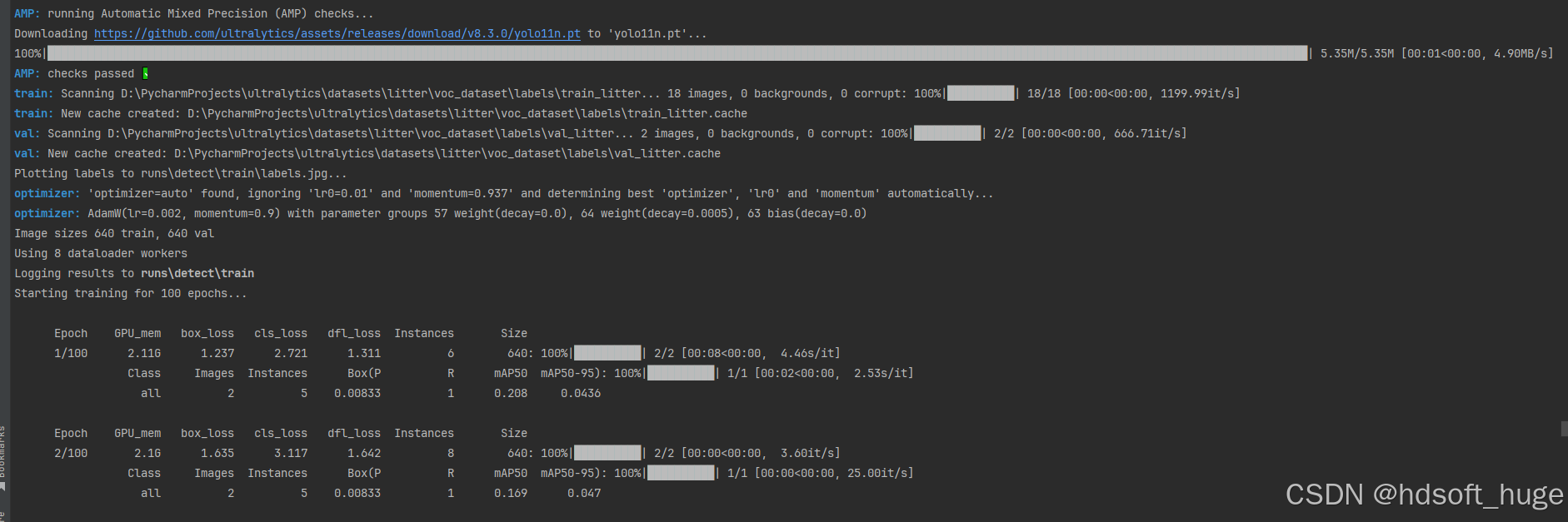
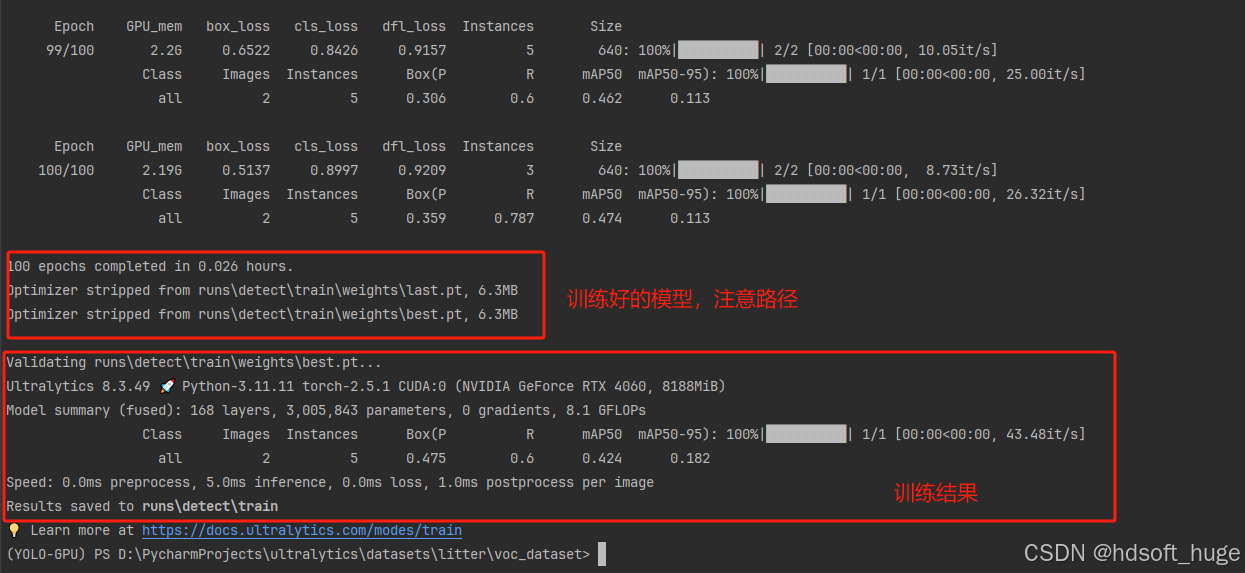
至此,我们已然成功完成了一个模型的训练工作。不过,对于当前的训练成果,我们暂不做深入的剖析与探讨。在后续的内容中,我们将会用心筹备并撰写一个独立的章节,该章节将重点聚焦于训练结果的查看方式以及针对这些结果的优化策略与方法。我们致力于通过详细且精准的阐述,为整个模型训练流程构建一套全面、深入且具有高度实用性的指导体系,以此确保模型训练的高效性和有效性,进而持续推动模型性能的稳步提升与优化,使其能够更好地满足实际应用的需求和挑战。
- 测试
yolo predict model=runs/detect/train/weights/best.pt source='D:\PycharmProjects\ultralytics\data\lj.jpg'
执行结果如下


9. 垃圾识别模型训练 (练手)
垃圾识别模型的训练流程亦遵循类似的方式与逻辑。对于那些对模型训练充满热情且渴望深入探索的同学而言,不妨尝试亲自动手训练属于自己的垃圾识别模型,这无疑是一个绝佳的实践机会,既能加深对相关知识与技术的理解,又能有效提升自身的动手操作能力,从而在实际操作中积累宝贵的经验,为今后涉足更为复杂的模型训练项目筑牢根基,开启人工智能实践探索的精彩旅程。
下面是我的训练结果
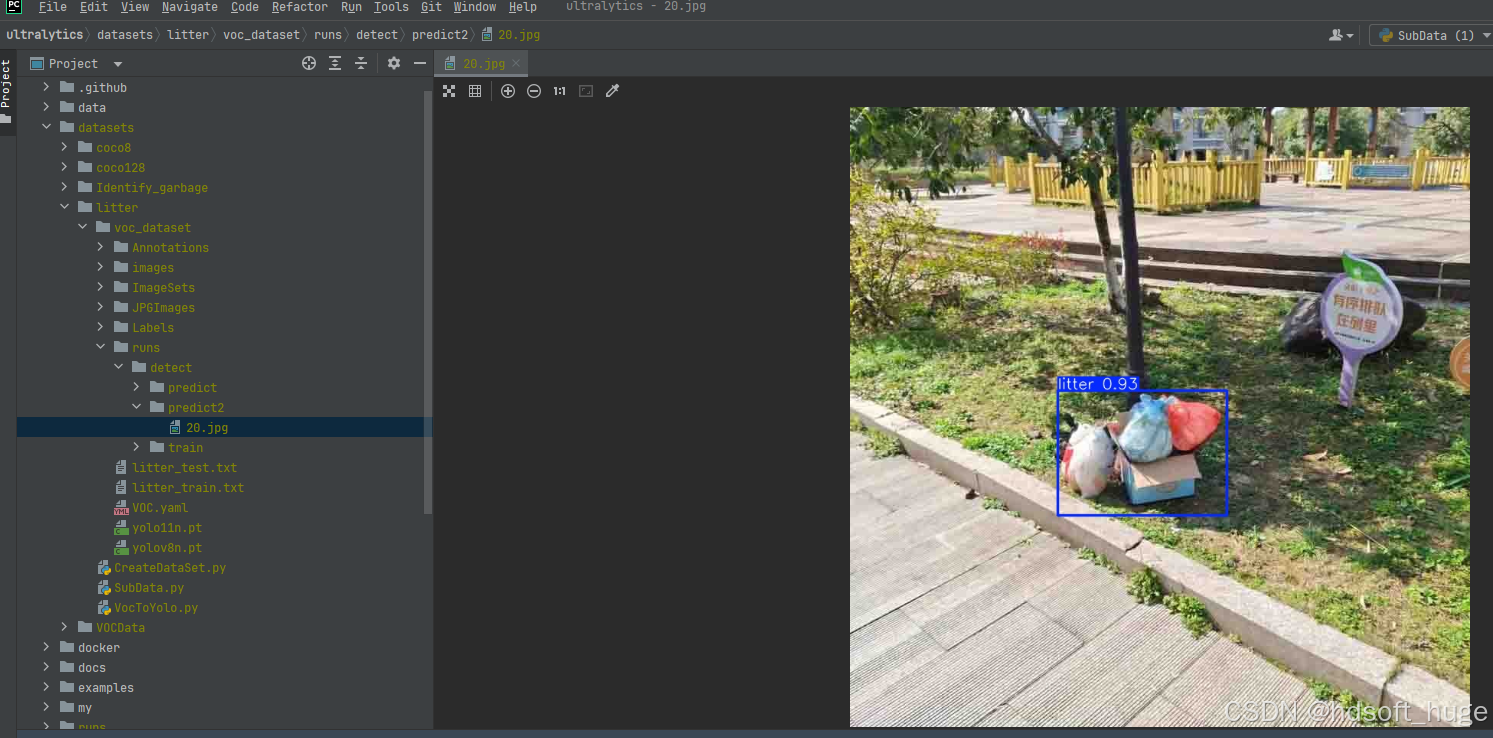
截至目前,我们所构建的模型已具备识别垃圾桶状态(空或满)的能力,这意味着我们在将模型应用于实际项目的道路上迈出了关键一步。同时,我们也成功掌握了训练模型以实现其在实际项目中特定功能的有效方法,这不仅是技术上的突破,更是我们将理论知识转化为实践应用能力的有力证明,为进一步拓展模型在更多实际场景中的应用奠定了坚实基础,也为后续深入优化模型性能、拓展其功能边界提供了宝贵的经验和技术支撑。

















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









