







药物-靶点亲和力预测是药物研发中的核心环节。借助AI大模型,可以在海量数据中快速筛选出潜在的药物-靶点组合,大幅提升研发效率。本教程旨在提供一个从数据准备、模型构建到结果分析的全流程指导,适合药物研发人员、生物信息学研究者以及制药公司的技术团队。
适合阅读本文的人群是:
- 药物研发人员:快速筛选候选药物,缩短研发周期。
- 生物信息学研究者:分析药物作用机制,探索新的治疗靶点。
- 制药公司:优化药物组合,提升市场竞争力。
- 学术研究者:开展前沿研究,发表高影响力论文。
适合的应用场景是:
- 药物筛选:快速筛选出高潜力的药物候选者,缩短研发周期。
- 靶点发现:发现新的药物作用靶点,拓展治疗领域。
- 个性化医疗:根据患者蛋白质序列的特定靶点,定制个性化药物组合。
- 学术研究:支持生物学机制研究,促进科学发现。
数据准备与处理
数据收集
首先,我们需要收集药物和靶点的数据。药物通常使用SMILES(Simplified Molecular Input Line Entry System)表示化学结构,靶点则使用氨基酸序列的FASTA格式。
药物示例:
CC(C)Cc1ccc(cc1)C(C)C(=O)O
COC(=O)c1ccccc1C(=O)O
靶点序列示例:
>Target1
MVLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHF...
>Target2
MGLSDGEWQLVLNVWGKVEADIAGHGQEVLIRLFKSHPEELHKL...
需要更多药物或者靶点信息可以参考:
- 药物数据:DrugBank数据库
- 靶点数据:UniProt数据库
数据清洗
为了提高预测的准确性,需要对数据进行清洗:
- 去除低丰度蛋白质:剔除丰度过低的蛋白质序列,确保数据质量。
- 标准化数据格式:
- 药物使用SMILES表示,每行一个化合物。
- 蛋白质序列按FASTA格式输入,每行一个序列。
数据加载
将清洗后的数据加载到预测模型中。通常,左侧输入药物的SMILES表示,右侧输入蛋白质序列。点击“预测”按钮,等待模型输出结果。
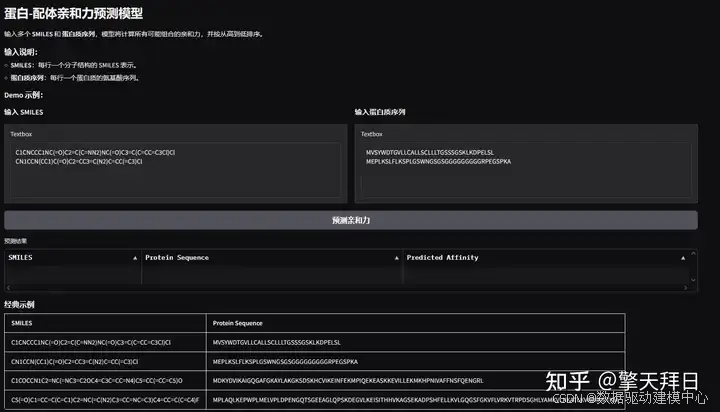
结果可视化分析
预测模型运行后,会输出药物与靶点之间的亲和力评分。为了更好地理解结果,可以使用以下几种可视化方法:
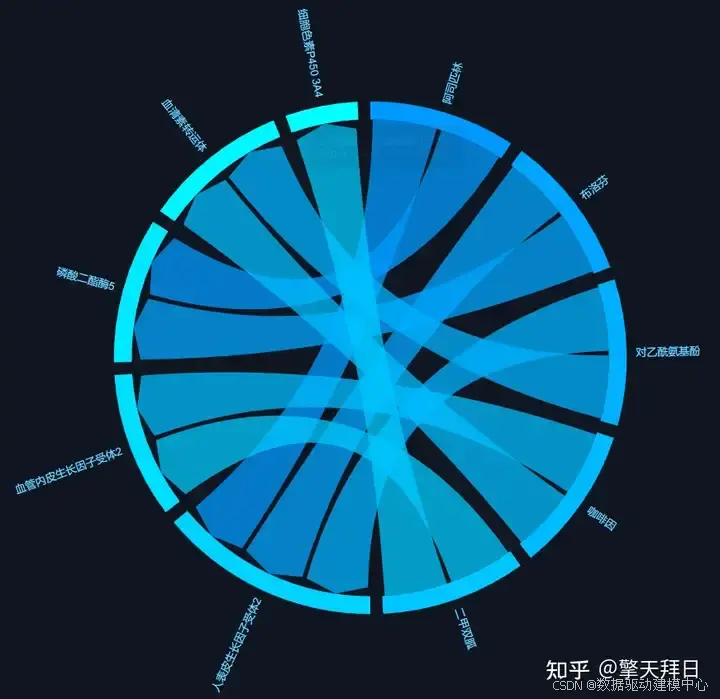
弦图
弦图展示了不同药物和靶点的交叉亲和力关系,直观且具有视觉冲击力。
示例解读:
- 每个扇区代表一种药物或靶点。
- 弦的粗细表示亲和力大小。
- 可以快速发现高效药物与靶点组合。
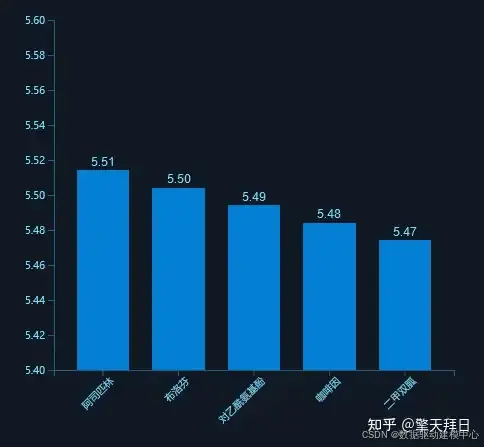
柱状图
柱状图用于展示某一靶点对不同药物的亲和力,便于筛选新药。
示例解读:
- 横轴为药物,纵轴为亲和力值。
- 柱子高度代表亲和力大小,高柱子意味着更高的亲和力。
热图
热图提供了全局视角下药物与靶点的相互关系,适用于大规模数据集。
示例解读:
- 每个单元格的颜色深浅表示亲和力的高低。
- 行代表靶点,列代表药物。
- 方便快速定位强相互作用区域。

本文所用到的预测模型和可视化工具来自【数据驱动建模中心】

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









