









0.
逻辑回归,回归,千万别被这个名字给骗了。逻辑回归更多的用在分类问题上,就像是贝叶斯那样。逻辑回归的模型分别给出样本的Y是+1和-1的概率,然后根据概率值的大小,对样本的类别进行预测。
1.
逻辑回归,它先计算一个得分(score,简称s),然后通过sigmoid函数(S型函数)将这个得分转换成概率值。这么做有什么道理?请往下看两段。
sigmoid函数: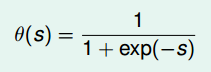
sigmoid函数图像: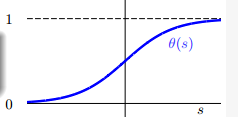
逻辑回归的模型:H(X)=
11+e−WX
这里的得分s通过一个线性模型得到的(s=WX)(沿用之前的写法,常量b写入W向量中)。从某种程度上说,逻辑回归是线性模型的一个拓展。我们在PLA中讲了线性分类器,训练一个超平面,通过判断样本在这个超平面的上方还是下方去进行样本类别的预测。逻辑回归可以类似进行理解,不过要比线性分类器复杂点,训练得到一个超平面,通过超平面得到样本的得分,然后将得分转换成概率值,进而预测样本的类别。PLA和逻辑回归都是先训练得到一个超平面,不同的是之后所做的事情。
接着第一段的讲一下逻辑回归为什么要这么做?在这里只说一下我的直观理解:逻辑回归对那个超平面的要求是正样本的得分大些,负样本的得分小些。而PLA对超平面的要求是正样本要集中在超平面的一侧,负样本要集中在超平面的另外一侧。直观上感觉逻辑回归的要求更为宽松些。这也就是说逻辑回归的抗干扰能力更强,它能处理一些线性分类器处理不好的情况。自己的理解,也不知道对不对。
现在已经知道了逻辑回归的模型了,接下来需要面对的问题是怎么训练得到这个模型?
可以很容易的发现一点,在这个模型中,我们真正需要知道的只有那个W。
我们通过最大化训练集数据(X,Y)出现的概率,求得最终的W。

注:我们可以看一下likelihood(h)这个式子,它的意思就是通过逻辑回归的模型,计算训练集出现的概率。最大化likelihood(h),意思就是要让最终得到的模型在训练集上的误差尽可能小,也就是使
Ein
尽可能小。(如果有什么疑问的话,可以仔细看一下那个式子,回想下概率论的知识)。。。。实际上就是极大似然估计。

根据sigmoid函数的对称性,likelihood(h)=
∏Nn=1h(YnXn)
。然后对似然函数取对数,求最大值。一步步推导如下:

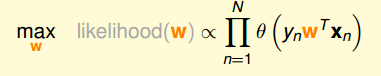
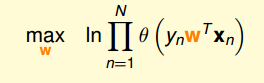

最后转化成了最小化err(w,x,y),这个就是逻辑回归的误差函数,称作cross-entropy error。
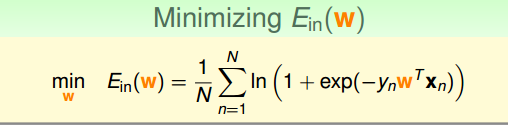
然后接着就是很熟悉梯度下降法。
省略求解梯度的过程,直接给出梯度公式
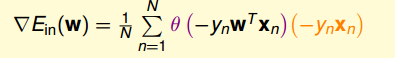
非常类似与PLA,每次W向梯度方向更新。

里面有一些更为细节的东西但并不妨碍你理解逻辑回归的东西,在这里就不去追究了,有很多博客和视频都有更为细致的描述。
2.
又要开始说
Ein≈0和Ein≈Eout
了。
1.在上面最小化
Ein
的步骤中,已经保证了
Ein≈0
。
2.在一开始,我们就说了逻辑回归可以看成是线性模型的拓展,在PLA中我们已经证明了线性分类器的VC维是d+1,这里我们就可以也认为逻辑回归的VC维和线性分类器的VC维差不多(都是基于线性模型),所以就认为
Ein≈Eout
。虽然这样解释有点不严谨,















 3384
3384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









