







在上一篇笔记中学习了使用信息熵选择最好的划分方式,本篇就要开始构建决策树了。
本文在上一篇的代码的基础扩展,先贴上代码
# coding:utf-8
from math import log
import operator
##创建训练数据集
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']] #数据集的最后一个元素作为该数据的标签,是否是鱼
labels = ['no surfacing','flippers'] #不浮出水面是否可以生存、是否有脚蹼
return dataSet, labels
##计算信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #计算每一个标签出现的次数
currentLabel = featVec[-1] #数据集的最后一个元素是该数据的标签,表示是否是鱼
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts: #计算信息熵
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
##分割数据集 axis即为在每一行中第axis个元素作为特征值划分并选出值与value相等的那一行,但要除去第axis个元素
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #输出的数据中要剔除该行第axis个元素
reducedFeatVec.extend(featVec[axis+1:])#输出的数据中要剔除该行第axis个元素
retDataSet.append(reducedFeatVec)
return retDataSet
###################################选择最好的数据集划分方式#########################
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #每一行的最后一个元素作为该行的标签
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #遍历每一个特征
featList = [example[i] for example in dataSet]#取出特征值数组,即取出数据集每行的第i列组成一个数组
uniqueVals = set(featList) #使用set数据类型来去除重复项
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value) #分割数据集
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #计算数据集的基础信息熵与所选特征信息熵的差值,越大表示选择的特征所具有的信息熵越小,就选择该特征
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回能最好划分数据集的特征, 如dataSet = [[1, 1, 'yes'], [1, 1, 'yes'],[1, 0, 'no'], [0, 1, 'no'],[0, 1, 'no']] 一行中的第一个元素或第二个元素
##以下为本文新增的代码
def majorityCnt(classList):#返回出现次数最多的类别
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#类别相同则停止继续划分
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类别
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #为了保证每次调用createTree时不改变原有labels的值,创建新变量代替元素列表
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
dataSet, labels=createDataSet()
mytree=createTree(dataSet,labels)
print mytree运行的结果为
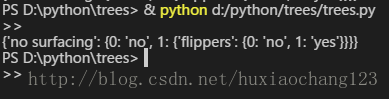
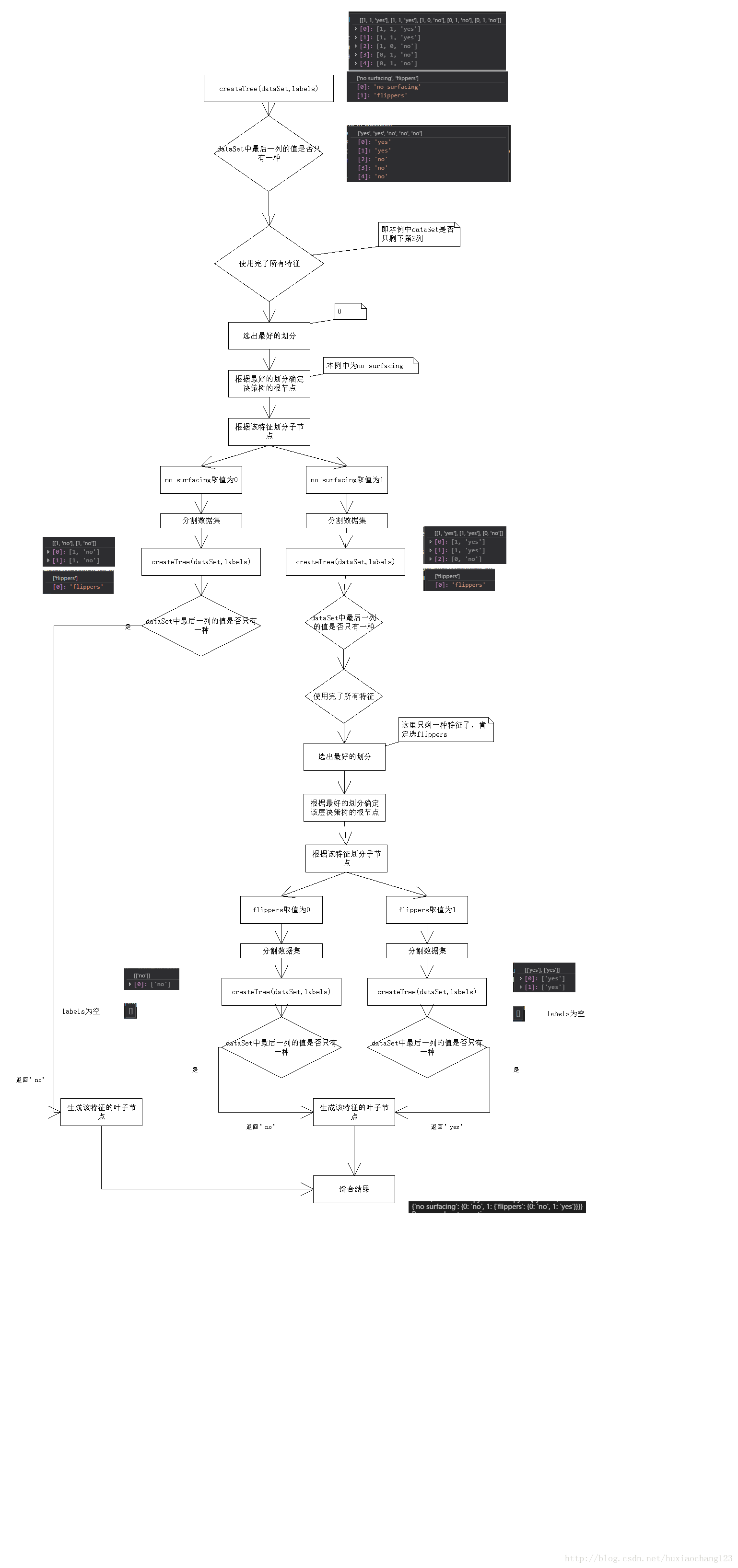
下面使用流程图说明决策树的构造过程
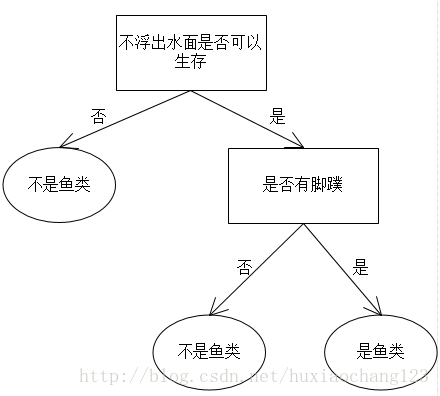
最后构造出的决策树就如下图所示















 3503
3503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









