







IP-adapter论文: https://arxiv.org/pdf/2308.06721.pdf
IP-adapter代码:https://github.com/tencent-ailab/IP-Adapter
IP-adapter
IP-Adapter是腾讯团队提出的,用于文本到图像扩散模型的文本兼容的轻量级图像提示适配器,用于预训练的文本到图像扩散模型,以实现使用图像提示生成图像的能力,其关键设计是关键设计是解耦的交叉注意力机制,将交叉注意力层分离为文本特征和图像特征,实现了图像提示的能力。
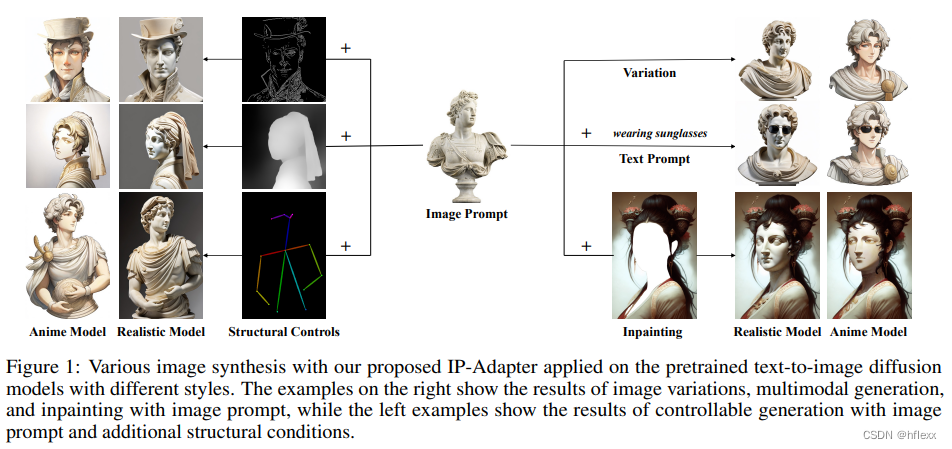
motivation
- 传统的文本到图像扩散模型虽然强大,但依赖于复杂的文本提示工程,这限制了内容创作的灵活性和易用性。当前adapter很难达到微调图像提示模型或从头训练的模型性能,主要原因是图像特征无法有效的嵌入预训练模型中。大多数方法只是将拼接的特征输入到冻结的cross-attention中,阻止了扩散模型捕捉图像图像提示的细粒度特征。
- 先前的工作,例如 SD Image Variations2 和 Stable unCLIP3证明了直接在图像嵌入上微调文本条件扩散模型以实现图像提示功能的有效性,但是它消除了原来使用文本生成图像的能力,且这种微调通常需要大量的计算资源。 其次,微调后的模型通常不可重用,因为图像提示能力无法直接转移到从相同的文本到图像基础模型派生的其他自定义模型。
- 在T2I模型中,跨注意力层的键(k)和值(v)的投影权重是针对文本特征进行训练的。然而,仅仅将图像特征与文本特征对齐可能会丢失一些图像特有的信息,因为模型没有专门针对图像数据进行优化,因此可能无法完全捕捉图像的所有细节和复杂性。用这种合并特征的方法可能导致生成的图像只能实现粗粒度的控制,而无法实现更细致的控制,从而导致生成的图像与参考图像的一致性不足。
contribution
- 提出的IP-adapter可重复使用且灵活。 在基础扩散模型上训练的 IP-Adapter 可以推广到从同一基础扩散模型微调的其他自定义模型。
- IP-Adapter 与 ControlNet 等其他可控适配器兼容,可以轻松地将图像提示与结构控件结合起来。
- 由于解耦的交叉注意策略,图像提示与文本提示兼容,实现多模态图像生成。
related works
文本到图像扩散模型
扩散模型可以基于文本条件生成图像,例如GLIDE、DALL-E 2、Imagen、Stable Diffusion (SD)、eDiff-I和RAPHAEL等。
Adapters for Large Models
适配器是一种在不重新训练整个大型预训练模型的情况下,通过添加少量可训练参数来增强模型能力的高效方法。适配器在自然语言处理(NLP)领域已有应用,并已被引入到视觉-语言理解以及文本到图像模型的控制生成中。
- ControlNet:首个证明适配器可以与预训练的文本到图像扩散模型一起训练,以学习特定于任务的输入条件,- 如边缘检测(canny)。
- T2I-adapter:使用简单轻量级的适配器实现生成图像的颜色和结构的细粒度控制。
- Uni-ControlNet:提出多尺度条件注入策略,学习适配器以实现各种本地控制。
- 一些适配器如T2I-adapter的风格适配器和Uni-ControlNet的全局控制器,通过将CLIP图像编码器提取的图像特征映射到新特征并与文本特征结合,实现了基于参考图像的风格或内容的图像生成。
METHODS
先验知识
L s i m p l e = E x 0 , ϵ ∼ N ( 0 , I ) , c , t ∥ ϵ − ϵ θ ( x t , c , t ) ∥ 2 L_{\mathrm{simple}}=\mathbb{E}_{\boldsymbol{x}_0,\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I}),\boldsymbol{c},t}\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\big(\boldsymbol{x}_t,\boldsymbol{c},t\big)\|^2 Lsimple=Ex0,ϵ∼N(0,I),c,t∥ϵ−ϵθ(xt,c,t)∥2
- x 0 x_0 x0 表示带有附加条件 c 的真实数据
- t ∈ [0, T] 表示扩散过程的时间步
- x t = a ˉ t × x 0 + 1 − a ˉ t × ϵ , ϵ ∼ N ( 0 , I ) x_{t} = \sqrt{\bar{a}_t}\times x_0+ \sqrt{1-\bar{a}_t}\times ϵ , ϵ \sim N(0,I) xt=aˉt×x0+1−aˉt×ϵ,ϵ∼N(0,I)
- 一旦训练了模型 ϵ θ ϵ_θ ϵθ,就可以通过迭代方式从随机噪声中生成图像。
对于条件扩散模型,分类器引导(Classifier Guidance)是一种简单的技术,用于通过利用单独训练的分类器的梯度来平衡图像保真度和样本多样性。 为了消除独立训练分类器的需要,无分类器指导通常被用作替代方法(Classifier-free Guidance)。 在这种方法中,通过在训练期间随机丢弃 c 来联合训练条件和无条件扩散模型。
ϵ
^
θ
(
x
t
,
c
,
t
)
=
w
ϵ
θ
(
x
t
,
c
,
t
)
+
(
1
−
w
)
ϵ
θ
(
x
t
,
t
)
,
\hat{\boldsymbol{\epsilon}}_\theta(\boldsymbol{x}_t,\boldsymbol{c},t)=w\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,\boldsymbol{c},t)+(1-w)\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,t),
ϵ^θ(xt,c,t)=wϵθ(xt,c,t)+(1−w)ϵθ(xt,t),
- w是调整与条件c对齐的标量值,通常称为引导尺度
- 对于文本到图像的扩散模型,无分类器指导在增强生成样本的图像文本对齐方面起着至关重要的作用。
- 在采样阶段,根据条件模型 ϵ θ ( x t , c , t ) ϵ_θ(x_t, c, t) ϵθ(xt,c,t)和无条件模型 ϵ θ ( x t , t ) ϵ_θ(x_t, t) ϵθ(xt,t)的预测来计算预测噪声
图像提示适配器
图像提示适配器的设计目的是使预训练的文本到图像扩散模型能够生成带有图像提示的图像。IP -adapter由两部分组成:一个图像编码器,用于从图像提示中提取图像特征;以及具有解耦交叉注意力的自适应模块,用于将图像特征嵌入到 预训练的文本到图像扩散模型。
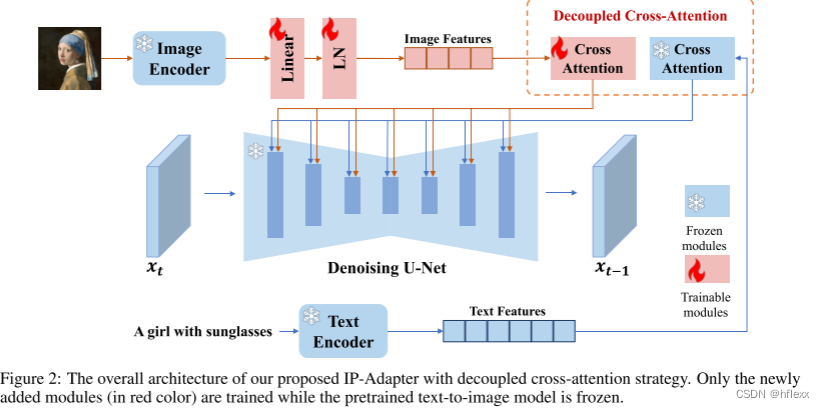
Image Encoder
利用 CLIP 图像编码器的全局图像嵌入,它与图像标题很好地对齐,可以表示图像的丰富内容和风格。 在训练阶段,CLIP 图像编码器被冻结。 为了有效地分解全局图像嵌入,我们使用一个小型可训练投影网络将图像嵌入投影为长度为 N 的特征序列(本研究中我们使用 N = 4),图像特征的维度与 预训练扩散模型中文本特征的维度。 我们在本研究中使用的投影网络由线性层和层归一化层组成
CLIP的讲解可以跳转到这篇博客:CLIP讲解
Decoupled Cross-Attention
在原始 SD 模型中,来自 CLIP 文本编码器的文本特征通过输入交叉注意力层而插入到 UNet 模型中。 给定查询特征 Z 和文本特征 c t c_t ct,交叉注意力 Z ′ Z^′ Z′的输出可以通过以下等式定义:
Z
′
=
Attention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
⊤
d
)
V
,
\mathbf{Z}'=\text{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})=\text{Softmax}(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}})\mathbf{V},
Z′=Attention(Q,K,V)=Softmax(dQK⊤)V,
为原始UNet模型中的每个交叉注意层添加一个新的交叉注意层以插入图像特征。 给定图像特征
c
i
c_i
ci,新交叉注意力 Z′′ 的输出计算:
Z ′ ′ = Attention ( Q , K ′ , V ′ ) = Softmax ( Q K ′ ⊤ d ) V , \mathbf{Z}''=\text{Attention}(\mathbf{Q},\mathbf{K}',\mathbf{V}')=\text{Softmax}(\frac{\mathbf{Q}\mathbf{K}'^{\top}}{\sqrt{d}})\mathbf{V}, Z′′=Attention(Q,K′,V′)=Softmax(dQK′⊤)V,
对图像交叉注意力和文本交叉注意力使用相同的查询(query)。 因此,只需要为每个交叉注意力层添加两个参数
W
k
′
,
W
v
′
W_k' ,W_ v'
Wk′,Wv′ 。 为了加速收敛,
W
k
′
,
W
v
′
W_k' ,W_ v'
Wk′,Wv′ 分别由
W
k
,
W
v
W_k ,W_v
Wk,Wv 初始化。 然后,简单地将图像交叉注意力的输出添加到文本交叉注意力的输出上,最终得到:
Z
n
e
w
=
Z
′
+
Z
′
′
=
S
o
f
t
m
a
x
(
Q
K
⊤
d
)
V
+
S
o
f
t
m
a
x
(
Q
(
K
′
)
⊤
d
)
V
′
w
h
e
r
e
Q
=
Z
W
q
,
K
=
c
t
W
k
,
V
=
c
t
W
v
,
K
′
=
c
i
W
k
′
,
V
′
=
c
i
W
v
′
\boxed{\mathbf{Z}^{new}=\mathbf{Z}'+\mathbf{Z}''=\mathrm{Softmax}(\frac{\mathbf{Q}\mathbf{K}^{\top}}{\sqrt{d}})\mathbf{V}+\mathrm{Softmax}(\frac{\mathbf{Q}(\mathbf{K}^{\prime})^{\top}}{\sqrt{d}})\mathbf{V}^{\prime}}\\\mathrm{where~}\mathbf{Q}=\mathbf{Z}\mathbf{W}_{q},\mathbf{K}=c_{t}\mathbf{W}_{k},\mathbf{V}=c_{t}\mathbf{W}_{v},\mathbf{K}^{\prime}=c_{i}\mathbf{W}_{k}^{\prime},\mathbf{V}^{\prime}=c_{i}\mathbf{W}_{v}^{\prime}
Znew=Z′+Z′′=Softmax(dQK⊤)V+Softmax(dQ(K′)⊤)V′where Q=ZWq,K=ctWk,V=ctWv,K′=ciWk′,V′=ciWv′
Training and Inference
在训练过程中,我们只优化IP-Adapter,同时保持预训练扩散模型的参数固定。 IP-Adapter 还在具有图像文本对的数据集上进行训练,使用与原始 S 相同的训练目标: L s i m p l e = E x 0 , ϵ ∼ N ( 0 , I ) , c , t ∥ ϵ − ϵ θ ( x t , c , t ) ∥ 2 L_{\mathrm{simple}}=\mathbb{E}_{\boldsymbol{x}_0,\boldsymbol{\epsilon}\sim\mathcal{N}(\mathbf{0},\mathbf{I}),\boldsymbol{c},t}\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\big(\boldsymbol{x}_t,\boldsymbol{c},t\big)\|^2 Lsimple=Ex0,ϵ∼N(0,I),c,t∥ϵ−ϵθ(xt,c,t)∥2
我们还在训练阶段随机丢弃图像条件,以便在推理阶段实现无分类器指导,在这里,如果图像条件被丢弃,我们只需将 CLIP 图像嵌入归零。由于文本交叉注意力和图像交叉注意力是分离的,我们还可以在推理阶段调整图像条件的权重:
Z n e w = A t t e n t i o n ( Q , K , V ) + λ ⋅ A t t e n t i o n ( Q , K ′ , V ′ ) \mathbf{Z}^{new}=\mathrm{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})+\lambda\cdot\mathrm{Attention}(\mathbf{Q},\mathbf{K}^{\prime},\mathbf{V}^{\prime}) Znew=Attention(Q,K,V)+λ⋅Attention(Q,K′,V′)
- λ是权重因子,如果λ=0,则模型成为原始文本到图像的扩散模型。
- A t t e n t i o n ( Q , K , V ) \mathrm{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V}) Attention(Q,K,V):文本作为条件
- A t t e n t i o n ( Q , K ′ , V ′ ) \mathrm{Attention}(\mathbf{Q},\mathbf{K}',\mathbf{V}') Attention(Q,K′,V′):图像作为条件
- 把文本特征和图像特征分开cross-attention再相加,之前的想法大多数先将图像特征和文本特征拼接后再cross。
实验效果
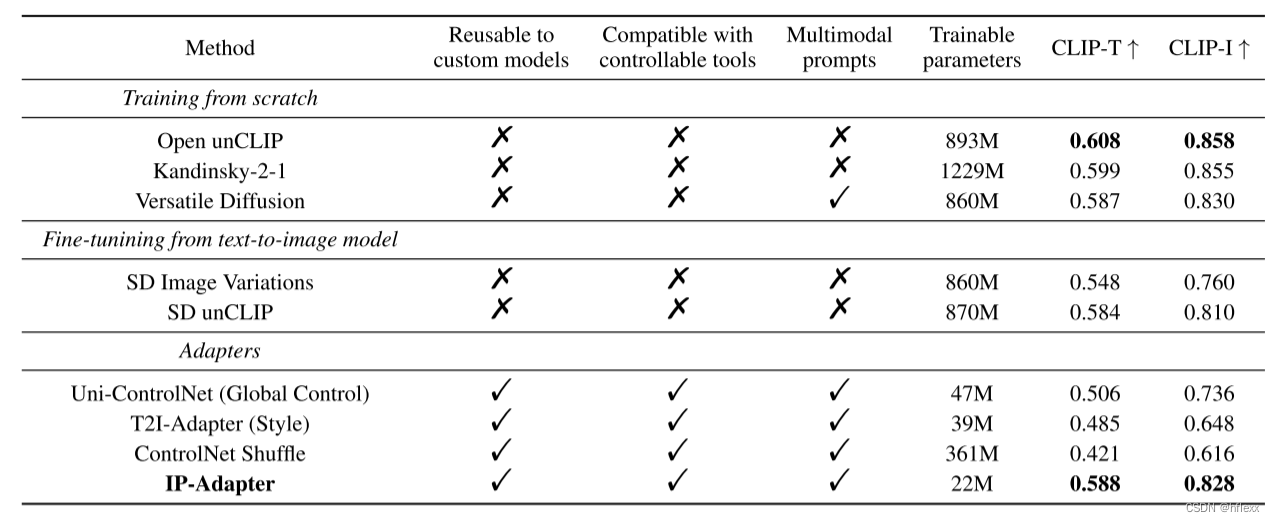
作者使用了COCO2017验证集进行定量评估,该数据集包含5,000张带有标题的图像。为了与其他方法进行公平比较,对于数据集中的每个样本,作者根据图像提示生成了4张图像。因此,对于每种方法,总共生成了20,000张图像,用CLIP-I和CLIP-T作为评估指标
- CLIP-I:这个指标衡量的是生成图像的CLIP图像嵌入与图像提示之间的相似性。它用于评估生成图像在视觉内容上与原始图像提示的一致性。
- CLIP-T:这个指标衡量的是生成图像与图像提示标题的匹配度,使用的是CLIPScore。CLIPScore是一个评估图像与文本描述匹配度的指标。
- 作者观察到,他们提出的IP-Adapter在这些评估指标上的表现不仅远超过其他适配器方法,而且即使只有22M个参数,也与完全微调的模型相当甚至更优。


















 1832
1832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









