







论文:https://arxiv.org/abs/2103.00020
代码:https://github.com/openai/CLIP
参考视频:CLIP讲解
参考博客:https://blog.csdn.net/weixin_47228643/article/details/136690837
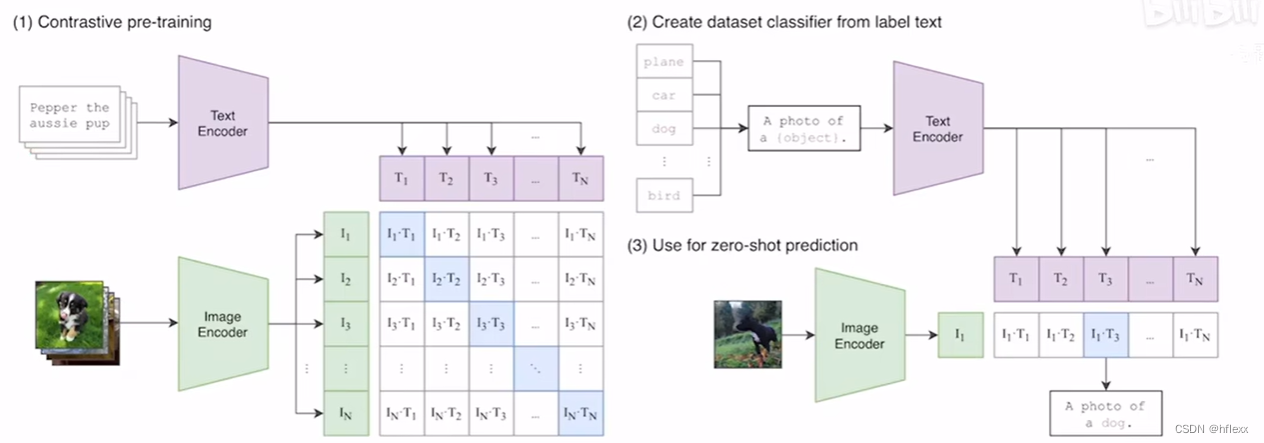
该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
- 这种表示使得文本描述和图像内容可以在同一个嵌入空间中进行比较和匹配。只需要预先标注文本数据对,正负样本是在batchsize中被内部构造出来的。
- 在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。
Motivation
- Generality of Vision Systems: 现有的计算机视觉系统通常被训练来预测一组预定义的对象类别,这种限制形式的监督限制了它们的通用性和可用性。
- Alternative Supervision: 直接从图像的原始文本描述中学习是一个有前景的替代方案,因为它利用了更广泛的监督源。
Contributions
-
CLIP Model:在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。能够从互联网收集的大规模数据集中学习。
-
Zero-Shot Transfer: 展示了CLIP在多种下游任务上的零样本迁移能力,包括OCR、视频动作识别、地理定位和细粒度物体分类。模型在不需要有仍何数据集训练的情况下(zero-shot),仍然有很好的结果
-
Benchmarking: 在30多个不同的计算机视觉数据集上对CLIP的性能进行了基准测试,显示了其在多种任务上的通用性。
-
Large-scale Dataset: 构建了一个包含4亿对(图像,文本)的数据集,用于模型的预训练。训练规模大大上升
-
文本作为监督信号,将输出变为多模态特征而不是单纯的视觉特征
Methods
contrastive learning
- 从预测确切单词到整体配对:传统的图像生成模型试图预测与图像直接相关的确切文本单词,这在面对多样的描述、评论和相关文本时变得非常困难。CLIP改变了这一目标,预测整体文本与图像的配对关系。
- 对比学习:CLIP采用了对比学习目标(contrastive objective),这种方法通过比较正例(正确的图像-文本配对)与负例(错误的配对)来学习更好的特征表示。
- batchsize是随机得到的,训练样本也是随机的
- 具体来说,先分别对图像和文本提特征,这时图像对应生成 I 1 , I 2 . . . I n I_1,I_2 ... I_n I1,I2...In 的特征向量,文本对应生成 T 1 , T 2 . . . T n T_1,T_2 ... T_n T1,T2...Tn 的特征向量
- 然后中间对角线为正样本,其余均为负样本。这样的话就形成了 n n n个正样本, n 2 − n n^2 - n n2−n个负样本。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。
- 模型训练思路:模型中使用visual_embedding 叉乘 text_embedding,得到一个[N, N]的矩阵
- 那么对角线上的值便是成对特征内积得到的,如果visual_embedding和对应的text_embedding越相似,那么它的值便越大。
- 选取[N, N]矩阵中的第一行,代表第1个图片与N个文本的相似程度,其中第1个文本是正样本,将这一行的标签设置为1,那么就可以使用交叉熵进行训练,尽量把第1个图片和第一个文本的内积变得更大,那么它们就越相似。


CLIP STEPS
- 特征提取
- image_encoder 和 text_encoder 分别是用于图像和文本的编码器,可以是ResNet、Vision Transformer、CBOW或Text Transformer等架构。
- 输入:图片(image)输入和文本(text)输入
- 图片: I [ n , h , w , c ] I[n, h, w, c] I[n,h,w,c], n n n是batchsize
- 文本: T [ n , l ] T[n, l] T[n,l], l l l是序列长度
- 多模态嵌入和相似度计算
I e I_e Ie 和 T e T_e Te 是经过投影和L2归一化后的特征表示,然后计算文本向量和图像向量之间的余弦相似度。 - 计算损失函数,对比学习
通过比较计算得到的 logits 和 labels 来计算交叉熵损失,用于区分正负样本

原文对应的伪代码如下:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts ,l对应于序列长度
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
#通过编码器得到对应的特征
I_f = image_encoder(I) #[n, d_i] #图片
T_f = text_encoder(T) #[n, d_t] # 文本
# joint multimodal embedding [n, d_e]
#通过映射(得到多模态的特征)和归一化后得到最终用于去比对的特征
I_e = 12_normalize(np.dot(I_f, W_i), axis=1)
T_e = 12_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t) #算相似度
# symmetric loss function
labels = np.arange(n) #对角线上的是正样本
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
Image Encoder
- 一种是使用ResNet50 作为基础架构,并在此基础上根据ResNetD的改进和抗锯齿rect-2模糊池对原始版本进行了修改。同时,还将全局平均池化层替换为注意力池化机制。注意力池化机制通过一个单层的“transformer式”多头QKV注意力,其中查询query是基于图像的全局平均池表示。
- 第二个架构使用Vision Transformer(ViT)进行实验。只进行了小修改,即 在transformer之前对 combined patch 和 position embeddings添加了额外的层归一化,并使用稍微不同的初始化方案。

- 首先对图片进行分块patch,并加入位置信息,将特征图展开为序列,输入到transformer编辑器中进行特征提取,通过自注意机制关注每个图像块的重要程度;
- 自注意结构根据查询、键、值(这三个处理通过对输入的线性变换的到)得到输出: Attention ( Q , K , V ) = s o f t m a x ( Q K T d K ) V \text{Attention}(\mathbf{Q},\mathbf{K},\mathbf{V})=\mathrm{softmax}\left(\frac{\mathbf{Q}\mathbf{K}^{T}}{\sqrt{d_{K}}}\right)\mathbf{V} Attention(Q,K,V)=softmax(dKQKT)V
- 同时,ViT模型引入了多头注意机制,投影n次, d k = d v = d m o d e l / h d_k=d_v=d_{model}/h dk=dv=dmodel/h,每个投影上并行计算,提高了计算效率。
Text Encoder
-
文本编辑器是Transformer架构,作为基础尺寸,文章使用12层512宽的模型,有8个注意头
-
transformer执行对文本的小写字节对编码(BPE)的表示。Byte Pair Encoding(BPE)是一种文本的子词单元编码方式,它可以将文本分解为更小的单元,有助于模型更好地理解词汇的构成和语义。
-
文本序列用[SOS]和[EOS]令牌括起来
- [SOS](Start Of Sentence)和[EOS](End Of Sentence)是序列开始和结束的特殊标记,它们帮助模型识别文本序列的边界
- 在Transformer的每一层,自注意力机制后通常会跟一个前馈网络和层归一化(Layer Normalization)。在CLIP中,使用[EOS]标记对应的最高层激活输出作为文本的特征表示。
-
PROMPT ENGINEERING AND ENSEMBLING
Prompt Engineering 和 Ensembling 通过定制化提示文本(prompt text)来指导模型学习特定任务,可以提高模型在零样本学习任务上的准确性。可以帮助解决多义性(polysemy)和上下文缺失(lack of context,推理的时候输入单个单词)的问题。

- 在处理多义词时,通过在文本提示中加入额外的描述性词汇或短语,可以为模型提供更多的上下文信息,帮助模型理解特定情境下的词义。例如,如果类别名称是“boxer”,并且它指的是一种狗的品种:{boxer}->{“A photo of a boxer, a type of dog”}
- 使用模版:采用特定的模板来构造文本提示,{label}->{“a photo of a {label}”},这样的模板可以帮助模型理解输入文本是关于图像内容的描述。这种方法可以减少模型对于类别名称的歧义,并提供更清晰的指导。
- 定制化提示:对于不同的任务和数据集,可以定制化文本提示以适应特定需求。例如,在细粒度图像分类数据集(如花卉或飞机型号分类)中,指定类别的上下文(如“A photo of a {label}, a type of flower”)可以提高模型的识别能力。
- 用常识和先验知识:在构造提示时,可以融入常识和先验知识,帮助模型更好地理解词汇的含义。例如,如果类别是“crane”,并且数据集中同时包含起重机和飞鹤,那么可以分别使用“construction crane”和“flying crane”作为提示。
Zero-shot Transfer
计算机视觉中,零样本学习通常指的是对图像分类中未见过的对象类别进行泛化的研究
CLIP训练好后得到两个编码器(Image Encoder和Text Encoder),图片输出的特征和由单词通过prompt engineering变成一个句子后对应的文本特征计算相似度后经过softmax得到概率分布,相似度对应最大的大概率就是照片对应的句子。
实验结果
不足
- Performance on Specific Tasks: 在某些细粒度分类任务和更抽象的任务上,CLIP的性能仍然较弱。
- Generalization to Out-of-Distribution Data: CLIP对于真正分布外的数据泛化能力仍然有限。
- Computational Efficiency: 尽管CLIP在效率上有所提高,但与图像标题生成等其他方法相比,仍有改进空间。
- Social Biases: 由于训练数据的未筛选性,CLIP模型可能会学习到并再现社会偏见。
零样本学习性能评估
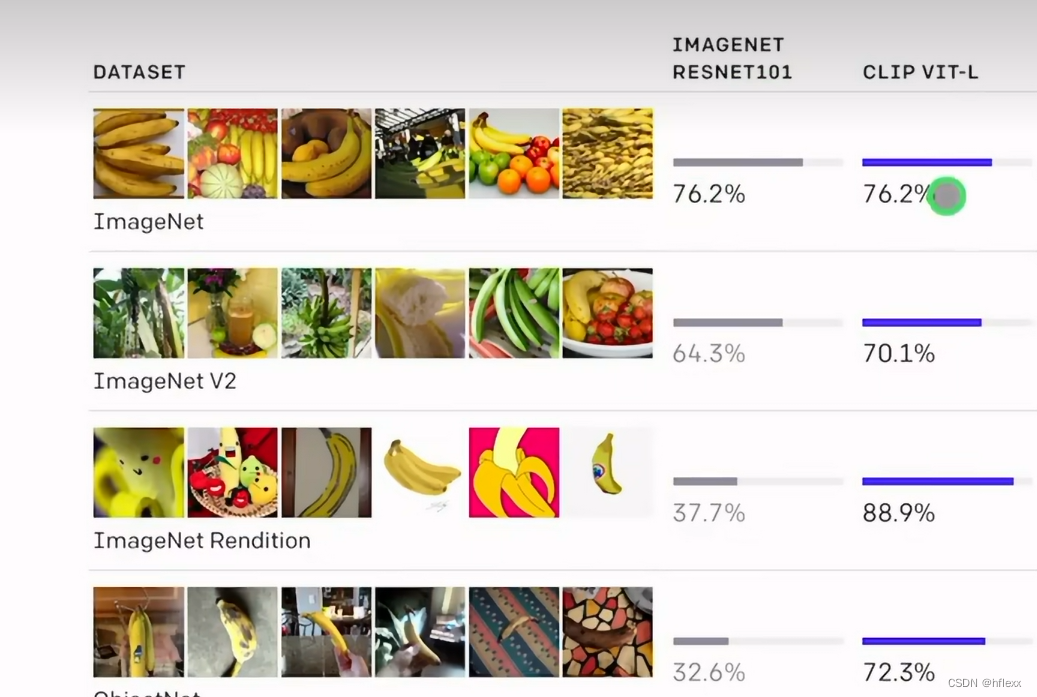
具体来说,Figure 5 展示了 CLIP 模型在 27 个不同数据集上的零样本学习性能,并与在 ResNet-50 特征上训练的完全监督线性分类器(base进行了比较。结果表明,CLIP 模型在 16 个数据集上超越了 ResNet-50 的完全监督线性分类器,包括 ImageNet。
zero-shot CLIP与ResNet50(有监督,linear probe),对于物体分类数据集,表现较好。对于更难的数据集CLIP表现的不好(不好用标签信息,因为需要很多特定知识)

零样本学习与少样本学习的比较
零样本 CLIP 与在相同特征空间上训练的 4 样本线性分类器的平均性能相匹配,并且几乎与公共可用模型中 16 样本线性分类器的最佳结果相匹配。 对于 BiT-M 和 SimCLRv2,突出显示了性能最佳的模型。 浅灰色线是评估套件中的其他模型。 此分析中使用了 20 个数据集,每类至少有 16 个示例。
(其中 Linear Probe 的意思是指训练的时候把预训练好的模型权重冻住,直接用其提取特征,然后只是去训练最后的 分类头,linear probe用于评估迁移能力)

零样本与linear probe
样本性能与线性探针性能之间存在强烈的相关性。这意味着当一个模型在零样本设置下表现良好时,它在使用线性探针进行评估时也很可能会有良好的表现,反之亦然。尽管存在相关性,零样本性能通常比线性探针性能低10到25个百分点。这表明零样本方法还有改进的空间,它并没有达到通过线性探针评估时所能达到的最佳性能。在少数情况下(只有5个数据集),零样本性能与线性探针性能非常接近,差异小于或等于3个百分点。这表明在这些特定的数据集上,零样本方法已经相当优化,几乎能够达到与有监督学习(通过线性探针)相似的结果。

CLIP在不同数据集上的性能
CLIP 的功能在各种数据集上都优于最佳 ImageNet 模型的功能。 在 27 个数据集中的 21 个数据集上,在 CLIP 的特征上拟合线性分类器优于使用 Noisy Student EfficientNet-L2。

code
Text encoder——transformer
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
# layers个ResidualAttentionBlock串联
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
class ResidualAttentionBlock(nn.Module):
# 定义一个残差注意力块,继承自PyTorch的nn.Module类
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
# 调用基类的构造函数
self.attn = nn.MultiheadAttention(d_model, n_head)
# 初始化多头注意力机制,d_model是模型的维度,n_head是注意力头的数量
self.ln_1 = LayerNorm(d_model)
# 初始化第一个层归一化模块,用于多头注意力之前
self.mlp = nn.Sequential(OrderedDict([
# 定义一个顺序容器,包含一个前馈神经网络(FeedForward Neural Network)
("c_fc", nn.Linear(d_model, d_model * 4)),
# 第一层线性变换,将维度扩大4倍
("gelu", QuickGELU()),
# 使用GELU(高斯误差线性单元)激活函数
("c_proj", nn.Linear(d_model * 4, d_model))
# 第二层线性变换,将维度缩小回原始维度d_model
]))
# 这种设计可以增加模型的表示能力,使得模型能够学习更复杂的函数映射关系
self.ln_2 = LayerNorm(d_model)
# 初始化第二个层归一化模块,用于前馈网络之前
self.attn_mask = attn_mask
# 可选参数,用于存储注意力掩码,可以控制注意力机制中的可见性
def attention(self, x: torch.Tensor):
# 定义注意力函数
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
# 确保注意力掩码的数据类型和设备与输入x一致,如果掩码不存在则设置为None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
# 应用多头注意力机制,输入和输出都是x,不需要权重,使用之前设置的掩码
def forward(self, x: torch.Tensor):
# 定义前向传播函数
x = x + self.attention(self.ln_1(x))
# 经过层归一化、多头自注意力和残差连接
x = x + self.mlp(self.ln_2(x))
# 经过层归一化、前馈网络和残差连接
return x
# 返回最终的输出
Image encoder-ViT/ModifiedResNet
在CLIP中,图像编码器有两种选择,分别是Vision Transformer和Resnet
ViT
Transformer结构基础上,在输入上把图像划分成一个个的patch, 然后将每个图像patch经过一个线性层投影后,添加位置编码和类别编码
class VisionTransformer(nn.Module):
# 定义一个视觉Transformer类,继承自PyTorch的nn.Module类
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
# 调用基类的构造函数
self.input_resolution = input_resolution
# 保存输入图像的分辨率
self.output_dim = output_dim
# 保存输出维度
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width,
kernel_size=patch_size, stride=patch_size, bias=False)
# 初始化一个卷积层,用于将输入图像划分成多个patch,没有偏置项
scale = width ** -0.5
# 计算缩放因子,用于初始化参数
self.class_embedding = nn.Parameter(scale * torch.randn(width))
# 初始化类别嵌入,使用缩放的正态分布随机数
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
# 初始化位置编码,考虑了所有可能的patch位置以及一个额外的类别token
self.ln_pre = LayerNorm(width)
# 初始化Transformer前的第一个层归一化模块
self.transformer = Transformer(width, layers, heads)
# 初始化Transformer模型,包含多个层和注意力头
self.ln_post = LayerNorm(width)
# 初始化Transformer后的一个层归一化模块
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
# 初始化投影参数,用于将Transformer的输出映射到目标维度
def forward(self, x: torch.Tensor):
# 定义前向传播函数,x是输入的四维张量,形状为(b, 3, h, w)
x = self.conv1(x) # 通过卷积层划分图像为patch
# shape = [b, width, grid, grid] 其中grid=h/patch_size
x = x.reshape(x.shape[0], x.shape[1], -1) # 调整形状为[b, width, grid ** 2]
x = x.permute(0, 2, 1) # 调整形状为[b, grid ** 2, width]
# 添加类别token
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1)
# shape = [b, grid ** 2 + 1, width]
# 添加位置编码
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x) # 应用层归一化
# 调整维度顺序以适应Transformer的输入要求
x = x.permute(1, 0, 2) # 从NLD (batch, sequence length, features) 转换为 LND
x = self.transformer(x) # 应用Transformer处理
# 再调整回NLD以继续后续处理
x = x.permute(1, 0, 2) # 从LND转换回NLD
# 获取类别token的信息
x = self.ln_post(x[:, 0, :]) # 取类别token通过层归一化
if self.proj is not None:
x = x @ self.proj # 应用投影参数,将特征映射到输出维度
# @ 是矩阵乘法运算符
return x # 返回最终的输出张量,形状为[b, output_dim]
ModifiedResNet
图像编码器的另外一种实现方式ModifiedResNet
它一个类似于torchvision的ResNet类,但包含以下更改:
- 现在有3个"stem"卷积,而不是1个,其中包含一个平均池化而不是最大池化。
- 执行 anti-aliasing stride卷积,其中在步幅大于1的卷积之前加上了一个平均池化。
- 最终的池化层是一个QKV注意力,而不是平均池。
class ModifiedResNet(nn.Module):
def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):
super().__init__()
self.output_dim = output_dim
self.input_resolution = input_resolution
# the 3-layer stem
self.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)
# (b,3,h,w)->(b,width/2,h/2,w/2)
self.bn1 = nn.BatchNorm2d(width // 2)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)
# (b,width/2,h/2,w/2)->(b,width/2,h/2,w/2)
self.bn2 = nn.BatchNorm2d(width // 2)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)
# (b,width/2,h/2,w/2)->(b,width/2,h/2,w/2)
self.bn3 = nn.BatchNorm2d(width)
self.relu3 = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(2)
# residual layers
self._inplanes = width # this is a *mutable* variable used during construction
self.layer1 = self._make_layer(width, layers[0]) # Layers[0]个bottleneck
self.layer2 = self._make_layer(width * 2, layers[1], stride=2)# Layers[1]个bottleneck
self.layer3 = self._make_layer(width * 4, layers[2], stride=2)# Layers[2]个bottleneck
self.layer4 = self._make_layer(width * 8, layers[3], stride=2)# Layers[3]个bottleneck
embed_dim = width * 32 # the ResNet feature dimension
self.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)
def _make_layer(self, planes, blocks, stride=1): # Blocks个BottleNeck串联
layers = [Bottleneck(self._inplanes, planes, stride)]
self._inplanes = planes * Bottleneck.expansion
for _ in range(1, blocks):
layers.append(Bottleneck(self._inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x): # x: (b,3,h,w)
def stem(x):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.relu2(self.bn2(self.conv2(x)))
x = self.relu3(self.bn3(self.conv3(x)))
x = self.avgpool(x)
return x
x = x.type(self.conv1.weight.dtype) # 转换x的数据类型
x = stem(x) # (b,width/2,h/2,w/2)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.attnpool(x) # AttentionPool2d
return x
- Bottleneck:ModifiedResNet 中的layer1~4使用的就是Bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1):
super().__init__()
# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1
self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.relu2 = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()
self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu3 = nn.ReLU(inplace=True)
self.downsample = None
self.stride = stride
if stride > 1 or inplanes != planes * Bottleneck.expansion:
# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1
self.downsample = nn.Sequential(OrderedDict([
("-1", nn.AvgPool2d(stride)),
("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),
("1", nn.BatchNorm2d(planes * self.expansion))
]))
def forward(self, x: torch.Tensor):
identity = x
# 1*1 conv -> BatchNorm2d ->Relu
out = self.relu1(self.bn1(self.conv1(x))) # (b,inplanes,h,w)->(b,planes,h,w)
# 3*3 conv -> BatchNorm2d ->Relu
out = self.relu2(self.bn2(self.conv2(out))) # (b,planes,h,w)->(b,planes,h,w)
out = self.avgpool(out) # AvgPool2d 二维平均池化
out = self.bn3(self.conv3(out))# (b,planes,h,w)->(b,planes*expansion,h,w)
if self.downsample is not None:
identity = self.downsample(x) # 进行下采样操作
out += identity # 残差连接
out = self.relu3(out)
return out # (b,planes*expansion,h,w)
- AttentionPool2d:ModifiedResNet 的最后一层使用的就是AttentionPool2d。
class AttentionPool2d(nn.Module):
def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):
super().__init__()
self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)
self.num_heads = num_heads
def forward(self, x): # (b,c,h,w)
x = x.flatten(start_dim=2).permute(2, 0, 1) # (b,c,h*w)->(h*w,b,c)
x = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (h*w+1,b,c)
x = x + self.positional_embedding[:, None, :].to(x.dtype) # 添加位置编码 (h*w+1,b,c)
x, _ = F.multi_head_attention_forward( # 多头注意力机制
query=x[:1], key=x, value=x,
embed_dim_to_check=x.shape[-1],
num_heads=self.num_heads,
q_proj_weight=self.q_proj.weight,
k_proj_weight=self.k_proj.weight,
v_proj_weight=self.v_proj.weight,
in_proj_weight=None,
in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),
bias_k=None,
bias_v=None,
add_zero_attn=False,
dropout_p=0,
out_proj_weight=self.c_proj.weight,
out_proj_bias=self.c_proj.bias,
use_separate_proj_weight=True,
training=self.training,
need_weights=False
)
return x.squeeze(0)
CLIP
init
初始化函数
def __init__(self,
embed_dim: int,
# vision
image_resolution: int,
vision_layers: Union[Tuple[int, int, int, int], int],
vision_width: int,
vision_patch_size: int,
# text
context_length: int,
vocab_size: int,
transformer_width: int,
transformer_heads: int,
transformer_layers: int
):
super().__init__()
self.context_length = context_length
# 图像编码器的两种形式
# 当输入的vision_layer 的格式是(tuple,list), 则用ResNet实现
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else: # 否则用Vision Transformer对图像进行编码
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
# 文本编码器用Transformer实现
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width) # vocab_size 表示词汇表的大小,transformer_width 表示每个 token 被映射成的向量的维度。
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
encode_image
图像编码器,调用self.visual对图像进行编码
def encode_image(self, image):
return self.visual(image.type(self.dtype))
# 先转换image的数据类别,然后再输入到图像编码器中进行编码
'''@property
def dtype(self):#用于获取图像编码器中conv1的权重的数据类别
return self.visual.conv1.weight.dtype'''
encode_text:文本编码器
def encode_text(self, text):
# 每个句子前面有两个特殊符号 [CLS] 和 [Seq]
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype) # 添加位置编码
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD [batch_size, n_ctx, d_model]
x = self.ln_final(x).type(self.dtype) # LayerNorm
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
forward函数:CLIP模型的前向传播过程,首先编码图像和文本信息,然后对图像和文本特征进行归一化,将归一化后的特征计算相似度得分
def forward(self, image, text):
image_features = self.encode_image(image) # 编码图像特征
text_features = self.encode_text(text) # 编码文字特征
# 对特征进行归一化
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp() # 可学习参数
logits_per_image = logit_scale * image_features @ text_features.t() # 每个图像与每个文本之间的相似度得分。
logits_per_text = logits_per_image.t() # 每个文本与每个图像之间的相似度得分。
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text


















 6534
6534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









