







QLib 量化投资平台简介
QLib(Quantitative Investment Library)是一个强大的开源量化投资研究平台,为金融量化分析提供全面解决方案。
核心功能
1. 数据管理
- 高效获取和处理股票历史价格数据
- 支持灵活的数据查询和预处理
- 轻松提取特定股票、特定时间段的价格数据
2. 交易日历管理
- 精确管理交易日期
- 确保回测与实际市场交易日完全对齐
- 处理复杂的日期计算和筛选
3. 策略开发
- 提供标准化的策略开发基类
- 支持模块化策略设计
- 允许自定义交易信号生成逻辑
4. 回测基础设施
- 模拟真实市场交易环境
- 处理交易成本、滑点、手续费等细节
- 提供详细的组合管理和绩效跟踪功能
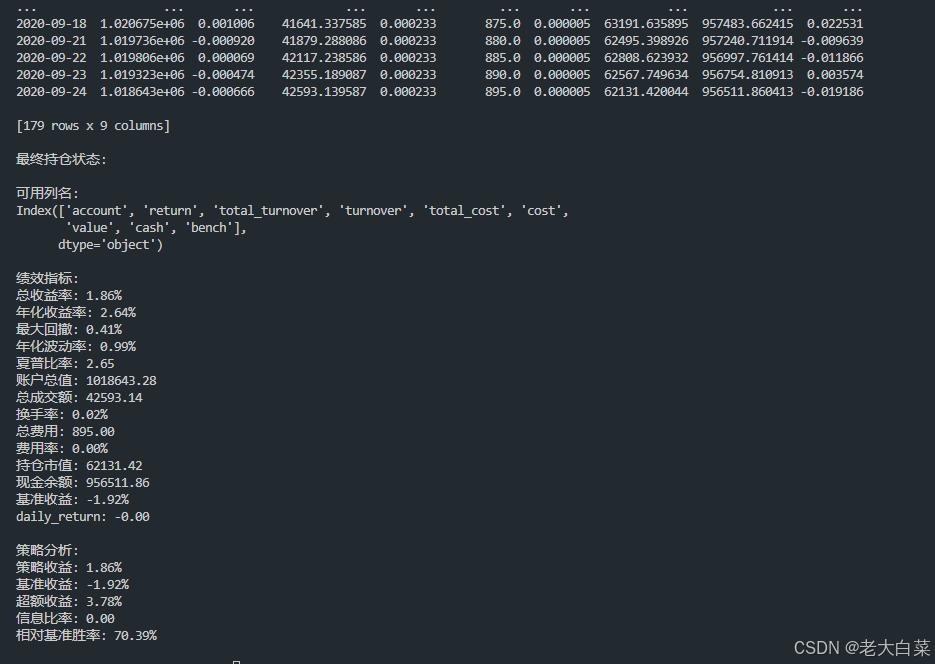
5. 风险与绩效分析
- 自动计算关键财务指标
- 提供专业风险分析工具
- 支持计算:
- 总收益率
- 年化收益率
- 最大回撤
- 夏普比率
- 信息比率
核心优势
- 端到端的量化研究解决方案
- 高度模块化和可扩展
- 简化量化策略开发流程
- 提供专业的金融分析工具
代码示例
# QLib数据提取示例
hist = D.features(
instruments=self.instruments, # 股票代码
fields=["$close"], # 收盘价
start_time=get_date_by_shift(current_date, -self.long_window - 10),
end_time=current_date,
freq='day' # 日频数据
).dropna() # 清理缺失数据
项目特点
- 支持多个市场(中国股市)
- 提供市场特定的配置和参数
- 灵活的数据处理能力
在本项目中的应用
- 使用贵州茅台股票数据
- 实现双移动平均线策略
- 回测时间范围:2020-01-01 到 2021-01-01
- 与沪深300指数进行对比
- 详细分析策略性能
环境要求
- Python >= 3.7 (推荐使用 Python 3.9)
- pip >= 19.1.1
- Anaconda 或 Miniconda
安装步骤
1. 创建虚拟环境
# 创建 Python 3.9 的 QLib 环境
conda create -n qlib python=3.9
# 激活环境
conda activate qlib
2. 安装 QLib
pip install pyqlib
3. 下载数据
QLib 需要使用特定格式的金融市场数据。可以使用以下命令下载中国市场的数据:
# 创建数据存储目录
mkdir -p ~/.qlib/qlib_data/cn_data
# 下载中国市场数据
python -m qlib.run.get_data qlib_data --target_dir ~/.qlib/qlib_data/cn_data --region cn
注意:
- 数据下载可能需要一段时间,取决于网络状况
- 默认下载路径为
~/.qlib/qlib_data/cn_data - Windows 用户可能需要修改路径格式
4. 验证安装
可以运行以下 Python 代码验证安装是否成功:
from qlib import init
from qlib.config import REG_CN
provider_uri = "~/.qlib/qlib_data/cn_data" # 数据路径
init(provider_uri=provider_uri, region=REG_CN)
常见问题
数据下载失败
- 检查网络连接
- 确保有足够的磁盘空间
- 尝试使用代理或 VPN
路径问题
- Windows 用户可能需要使用完整路径,例如:
C:/Users/YourUsername/.qlib/qlib_data/cn_data - 确保目录具有写入权限
参考资源
注意事项
- 首次运行策略时,建议使用小规模数据进行测试
代码:
# 导入必要的库和模块
# 多进程支持库
from multiprocessing import freeze_support
# QLib 量化投资库的核心模块
from qlib import init
from qlib.config import REG_CN # 中国股票市场配置
from qlib.strategy.base import BaseStrategy # 策略基类
from qlib.backtest import backtest, CommonInfrastructure # 回测和基础设施
from qlib.contrib.evaluate import risk_analysis # 风险分析工具
from qlib.utils import init_instance_by_config, get_date_by_shift # 实例初始化和日期处理
from qlib.data import D # 数据处理模块
from qlib.data.data import Cal # 日历模块
from qlib.backtest.decision import TradeDecisionWO, Order # 交易决策和订单
# 数据处理和科学计算库
import pandas as pd
import numpy as np
if __name__ == "__main__":
# 多进程支持:防止在 Windows 环境下出现重复执行问题
freeze_support()
# QLib 初始化配置
# 设置数据提供者路径和区域
provider_uri = "~/.qlib/qlib_data/cn_data" # 本地数据存储路径
init(
provider_uri=provider_uri, # 数据提供者路径
region=REG_CN, # 中国股票市场
calendar_provider={
"class": "LocalCalendarProvider", # 本地日历提供者
"module_path": "qlib.data.data",
"kwargs": {
"remote": False # 不使用远程日历
}
}
)
# 双均线交易策略类:继承自基础策略类
class DoubleMAStrategy(BaseStrategy):
"""
双移动平均线交易策略
策略原理:
1. 计算短期和长期移动平均线
2. 当短期均线穿过长期均线时产生交易信号
3. 短期均线在长期均线上方时买入
4. 短期均线在长期均线下方时卖出
参数:
- instruments: 交易标的列表
- short_window: 短期移动平均线窗口期
- long_window: 长期移动平均线窗口期
"""
def  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











