




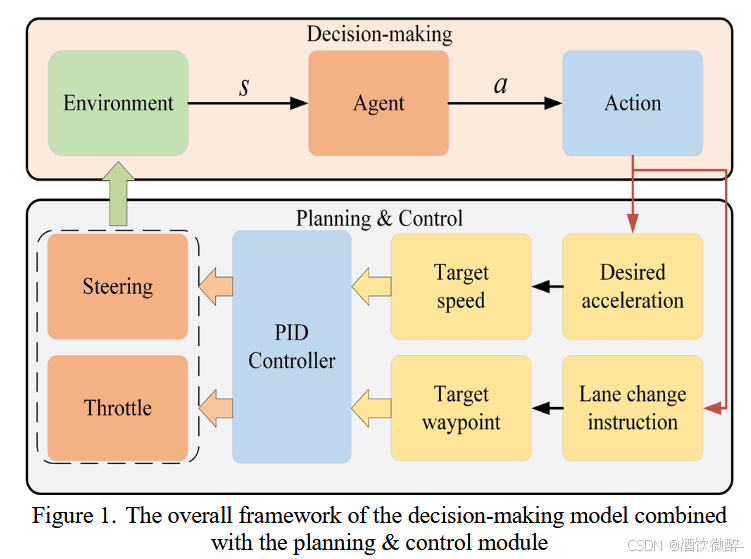
 此图展示了结合规划与控制模块的强化学习(RL)决策模型的总体框架。这个框架说明了决策模型输出动作后,规划与控制模块如何完成横向和纵向的动作分解,并为动作提供相应的合理路径。在横向控制方面,给定一个目标路径点,路径规划器使用A*算法优化路径并生成一系列目标路径点,这些点随后输入到PID控制器的横向控制模块中,以计算自动驾驶车辆的转向角度。在纵向控制方面,通过决策模型给出的期望加速度来计算每个控制周期的目标速度,并输入到PID控制器的纵向控制模块中,以计算自动驾驶车辆的油门值。
此图展示了结合规划与控制模块的强化学习(RL)决策模型的总体框架。这个框架说明了决策模型输出动作后,规划与控制模块如何完成横向和纵向的动作分解,并为动作提供相应的合理路径。在横向控制方面,给定一个目标路径点,路径规划器使用A*算法优化路径并生成一系列目标路径点,这些点随后输入到PID控制器的横向控制模块中,以计算自动驾驶车辆的转向角度。在纵向控制方面,通过决策模型给出的期望加速度来计算每个控制周期的目标速度,并输入到PID控制器的纵向控制模块中,以计算自动驾驶车辆的油门值。
结合文章理解:该图展示了一个结合了规划与控制模块的强化学习(RL)决策模型的总体框架。这个框架的核心思想是将RL决策模型与车辆的规划和控制模块相结合,以提高自动驾驶车辆在实际应用中的鲁棒性和现实转移性。下面是对图中各个组件和流程的详细解释:
RL决策模型输出(Action Output):
- RL决策模型根据当前的环境状态(包括车辆自身的状态和周围环境的信息)输出一个动作指令。这个动作指令通常包括期望的加速度和变道指令。
规划与控制模块(Planning & Control Module):
- 规划与控制模块接收RL决策模型输出的动作指令,并将其分解为横向控制(Lateral Control)和纵向控制(Longitudinal Control)两个部分。
- 横向控制负责处理车辆的转向,纵向控制负责处理车辆的加速和减速。
横向控制(Lateral Control):
- 横向控制模块使用A*算法来优化路径,并生成一系列目
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









