









 超级会员免费看
超级会员免费看
简介
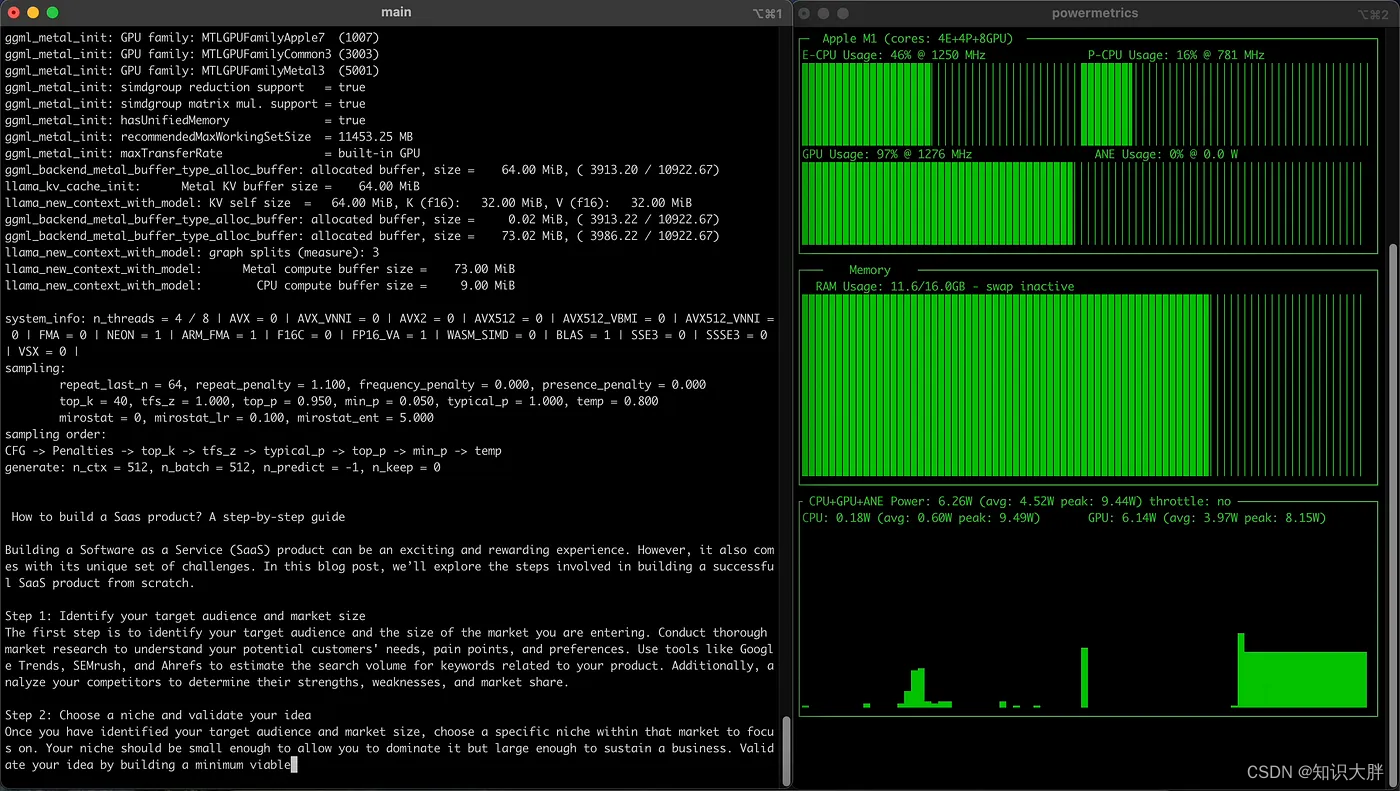
Mistral-7B 和 Phi-2 实验跨库的最快推理/生成速度。
介绍
在 NLP 部署方面,推理速度是一个至关重要的因素,特别是对于支持 LLM 的应用程序而言。随着 Apple M1 芯片等移动架构数量的不断增长,评估 LLM 在这些平台上的性能至关重要。在本文中,我比较了三个流行的 LLM 库(MLX、Llama.cpp和Hugging Face 的Candle Rust)在Apple M1 芯片上的推理/生成速度。旨在方便开发人员选择最合适的库在本地机器上部署 LLM,同时考虑性能、实现的便利性以及与可用工具和框架的兼容性。对于推理速度测试,我使用了两种先进的 LLM 模型;来自 Microsoft 的 Mistral-7B 和 Phi-2。根据结果,为想要提高其 LLM 性能的开发人员提供了一些建议,特别是在 Apple M1 芯片上。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











