










摘要:文本分类是NLP最常见的应用之一,有了BERT之后更是可以通过小批量数据精调达到不错的效果。但在对速度要求高、没有钱买GPU、移动设备部署的场景下,还是得用浅层网络。今天就跟大家介绍Google最近新出的一个模型—— ...
人工智能学习离不开实践的验证,推荐大家可以多在FlyAI-AI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
文本分类是NLP最常见的应用之一,有了BERT之后更是可以通过小批量数据精调达到不错的效果。但在对速度要求高、没有钱买GPU、移动设备部署的场景下,还是得用浅层网络。
今天就跟大家介绍Google最近新出的一个模型——pQRNN,只利用监督数据(无蒸馏),以约1/300的参数量达到了接近BERT的效果。pQRNN是Google去年更小模型PRADO的一个改进版本,下面从PRADO讲起,来看看它们是如何以小博大的叭。
pQRNN官方博客:
PRADO论文:
PRADO代码:
PRADO模型
Embedding
对于我们常用的NLP模型来说,Embedding词表往往是参数量占比较大的一块儿。中文如果选用字级别的词表,大概在一两万级别,词级别则会几万或者更大,还会出现OOV。英文多出了子词级别,但无论哪种粒度的划分都是存在缺点的:
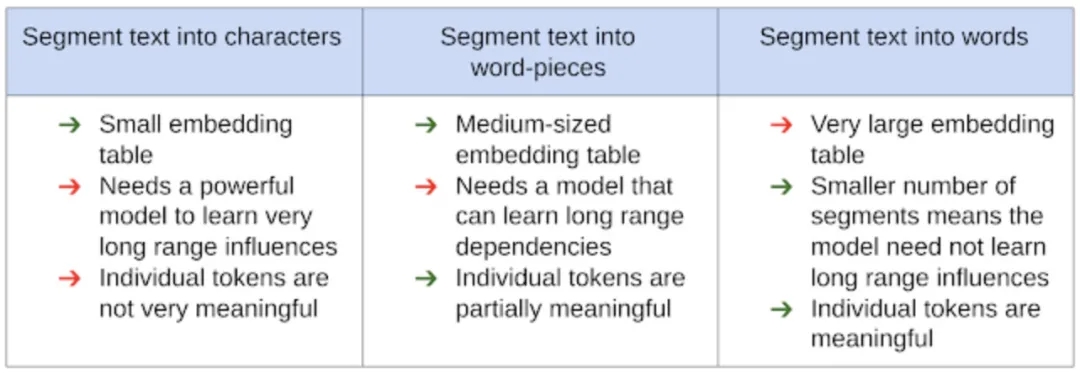
太细了就对模型要求很高,单独的词也不具有太大意义,而太粗了又没法涵盖所有词汇。
这就需要我们在不同的任务上选取不同的粒度。PRADO的作者认为,对于文本分类这样的简单任务,很多词汇是和任务无关的,比如 a, the等。另外,也不需要embedding可以准确的表示每个词,只需要大概表示出词所属的类目就可以了。比如在情感分析任务中,只需要让模型知道“超棒”和“太赞了”都是一个positive的词汇,而不用知道这两个词的区别在哪里,甚至用一个embedding去表示这两个词都是可以的。
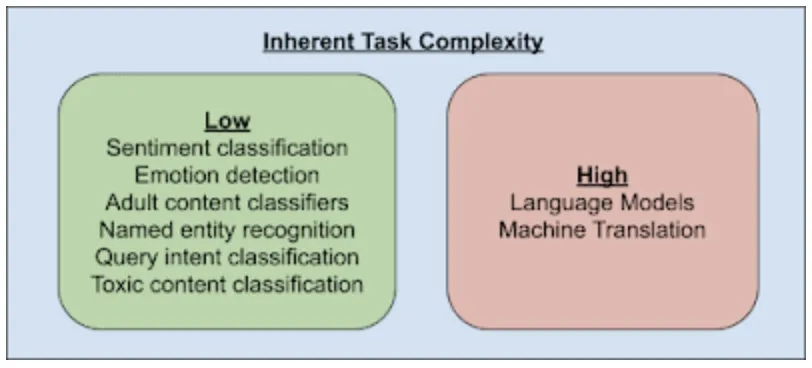
下面是不同任务和细粒度词表示的相关性,对于语言模型和翻译任务,就需要准确地区分每个词:
那PRADO是如何压缩embedding的呢?
以往在拿到token之后,我们会有一个转one-hot向量的操作,向量的大小是词表维度V,然后再经过lookup table得到embedding。而PRADO则是将向量进行了压缩,具体的操作是:
对token进行哈希,得到 2B bits 的哈希值,比如 011001010
用一个投影函数P,将每2个连续的bit映射到 {-1, 0, 1} 中
得到B维的三元向量,比如 [-1, -1, 1, 0, 1] 这样
将 1xB 的三元向量和 Bxd 的矩阵相乘,得到 d维embedding表示
这样,我们就得到了一个压缩后的token表示,不用准确地用one-hot来表示每个token。作者把B的维度限制在 [128, 512],d的维度限制在[32, 96],从词表参数量上比BERT小了三四个数量级。
整体结构
PRADO主要的创新就在Embedding部分,后续就比较普通,选择了性价比较高的CNN+Attention。这里Attention其实是对CNN的结果进行了Pooling:先计算了一路CNN的结果,再计算softmax得到每个step的权重,然后把另一路CNN的结果加权起来,得到一个向量。
最后把不同尺寸kernel输出的向量concat,再过classifier(我们熟悉的套路又渐渐回来了)。
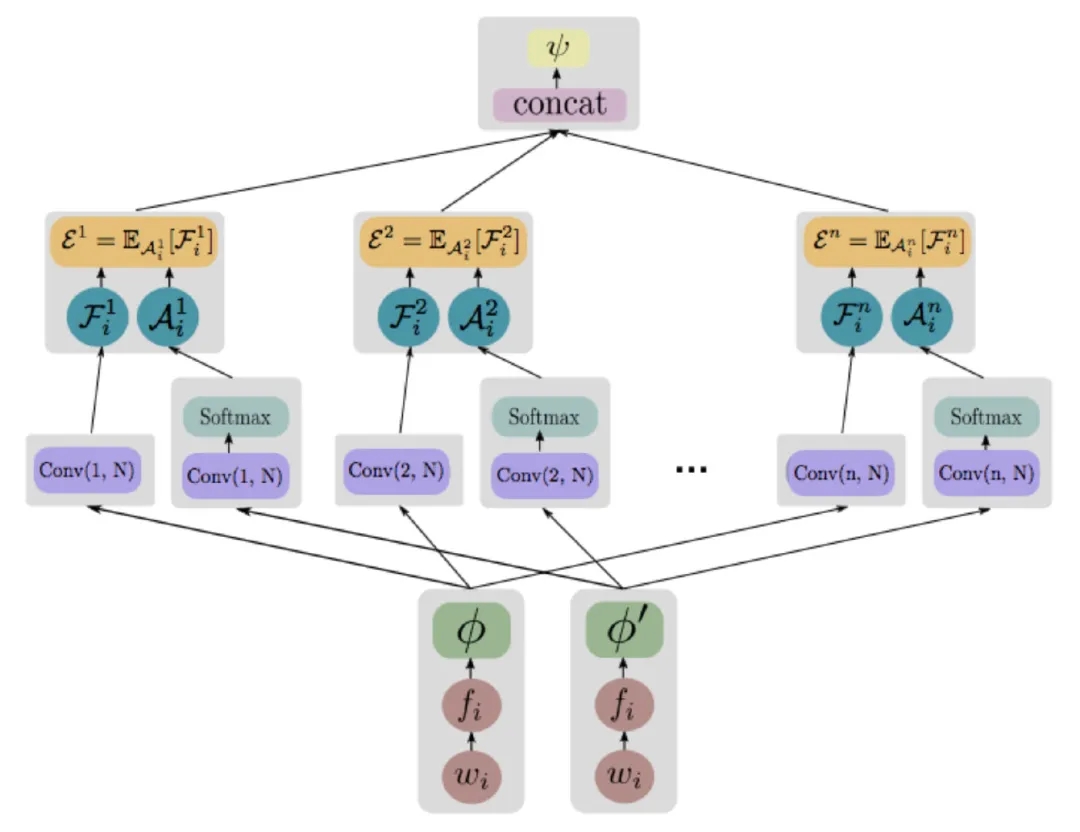
PRADO模型结构
实验效果
在效果上,PRADO肯定是比之前的浅层模型要好,然而我去看了一眼每个数据集的SOTA,emm。。效果上还需努力鸭
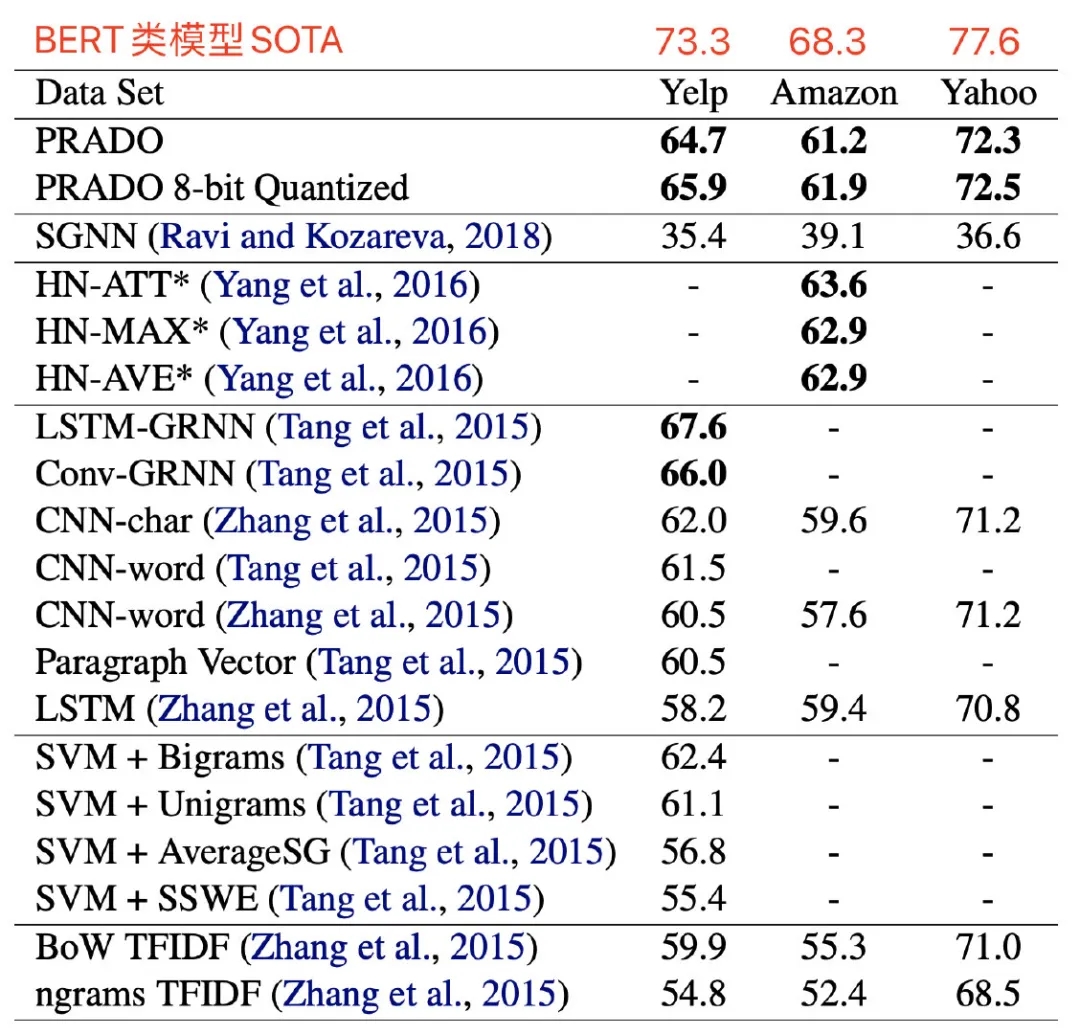
PRADO效果
令我感兴趣的是,8-bit量化之后的PRADO居然效果更好!作者认为主要是量化减少了过拟合,在数据越少的数据集上效果提升就更明显。
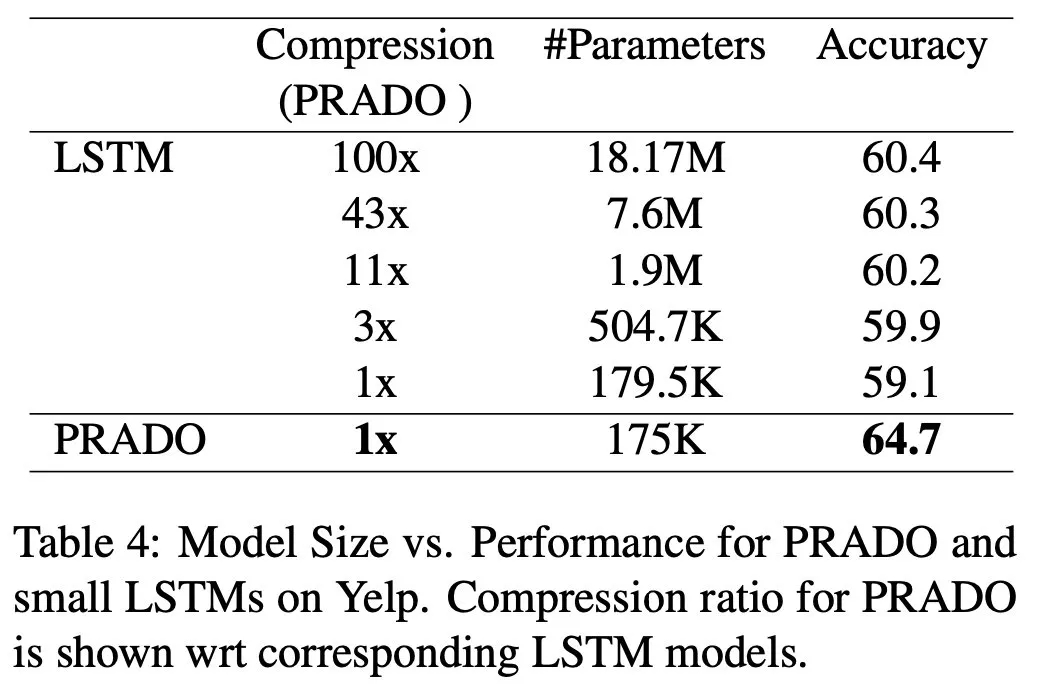
对比实验,性价比吊打LSTM:
最后,作者还做了迁移实验,证明这种embedding改进的可迁移性,发现只freeze上embedding和encoder,只finetune分类器就收敛得很快:
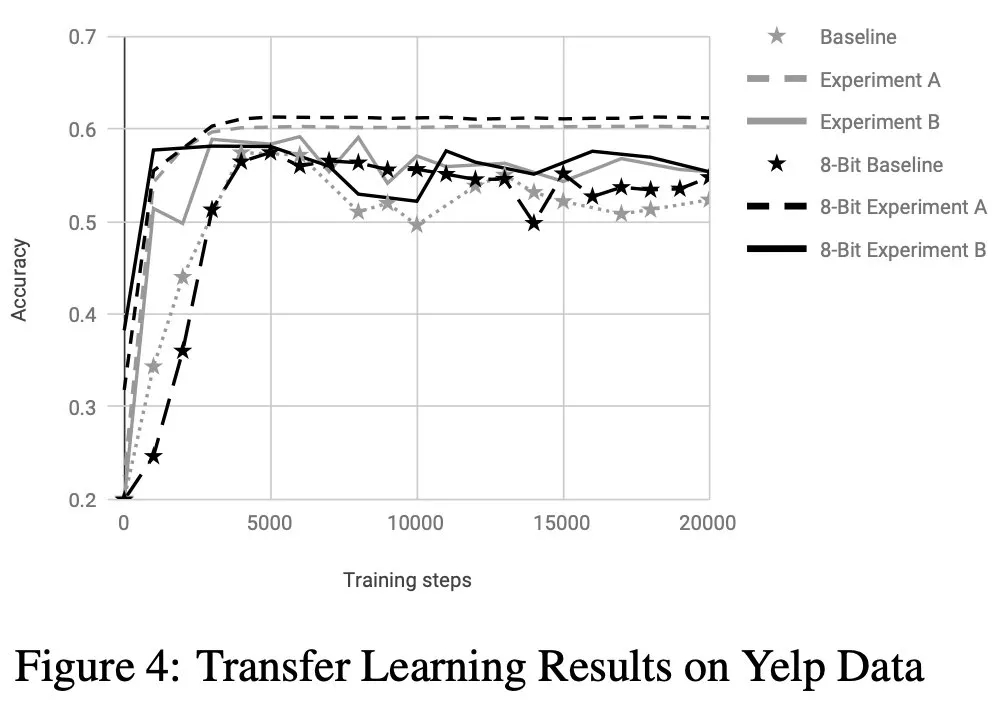
PRADO迁移学习实验
pQRNN
介绍完了PRADO,再来看谷歌新出的pQRNN就很好懂了,实际上只是把encoder换成了QRNN(quasi-RNN):

pQRNN模型结构
这里的Projection就是得到三元的过程,Bottleneck就是将三元向量embedding。
虽然没什么太大创新,但比较激动的是pQRNN的效果接近了BERT(之前PRADO都是惨不忍睹):
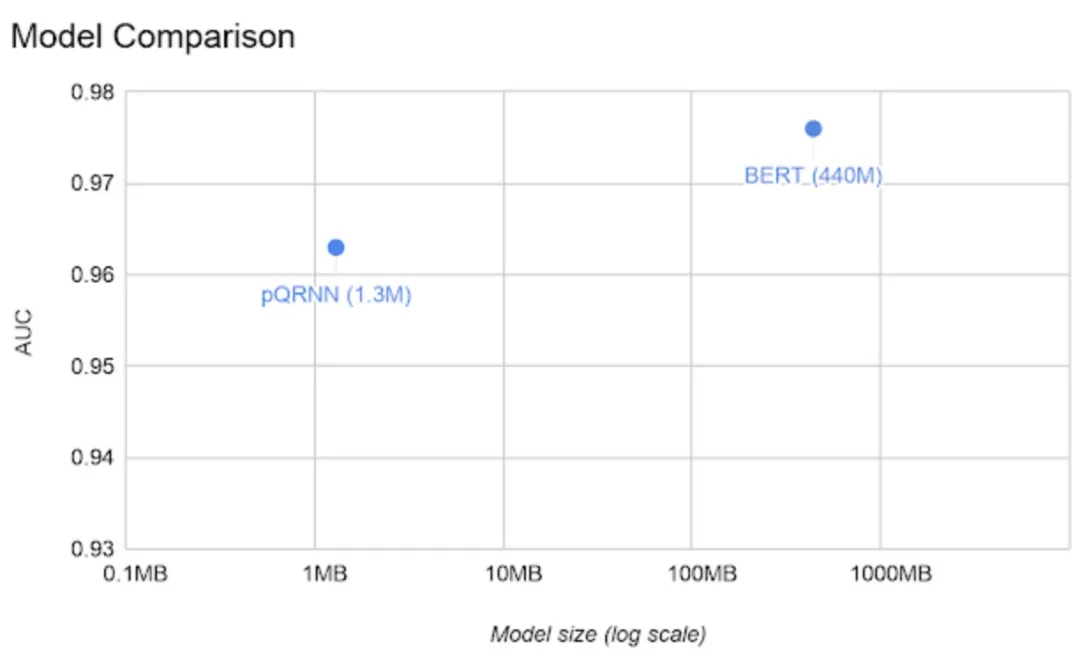
pQRNN
不过这个结论只在一个数据集上验证了,其他数据上的表现未可知。
总结
PRADO/pQRNN的主要改进点就在embedding部分,确实文本分类对于token的粒度要求不高,只用抓住句子里最主要的一两个词就行了,所以max-pooling经常会比mean-pooling效果要好。
但这里有个需要探讨的点,就是如何迁移到中文任务上。单纯的哈希是没法将相似的词映射到相似的三元向量的,这里我认为应该是进行字粒度的tokenization,这样相似的“好赞”、“超赞”的表示就很接近了,再过CNN就可以捕获到词级别的信息。
去年PRADO就出来了,但20年8月底才放出源码,同学们赶紧试用起来呀。

更多精彩内容请访问FlyAI-AI竞赛服务平台;为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台;每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
挑战者,都在FlyAI!!!















 175
175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









