







 本文介绍了BERT模型的原理及其在人力资本领域的应用,包括情感分析、实体识别和名词短语识别。通过领域内的无监督训练,创建了专有的CV预训练模型,提高了模型在特定任务中的准确性和迁移能力。e成科技借助BERT技术,推动了HR领域的AI升级,实现了AI能力的中台化和开放化,助力人力资本智能化。
本文介绍了BERT模型的原理及其在人力资本领域的应用,包括情感分析、实体识别和名词短语识别。通过领域内的无监督训练,创建了专有的CV预训练模型,提高了模型在特定任务中的准确性和迁移能力。e成科技借助BERT技术,推动了HR领域的AI升级,实现了AI能力的中台化和开放化,助力人力资本智能化。

WHAT'S BERT ?
BERT (Bidirectional Encoder Representations from Transformers),是google于2018年底提出的一个预训练语言模型,它通过无监督的方法对大规模的自然语言的语料进行学习,从中提取出人类语言的内在基本规律,辅助后续的自然语言理解的相关任务。
例如,对于一段文本:e成科技是HR+AI赛道的领跑者,在NLP领域有很多的技术积累。
用通俗的语言理解,BERT在学习的是以下两方面的能力:
1.当输入了“e成科技是一家HR+AI__的领跑者”的时候,模型要学习到填入”赛道”是最佳答案,而不是其他的任何的无关词。
2.当输入了“e成科技是HR+AI赛道的领跑者”的时候,模型要学习到”在NLP领域有很多的技术积累”是最佳的下一句,而不是其他的任何句子。
以上两方面的能力,可以理解为是人类语言的基本规律,那么当模型学习到这种规律之后,有什么用呢?
BERT的强大能力
以BERT模型为基础,通过fine tune的方式,可以在BERT已经习得的语言知识的基础上,快速构建对其他自然语言任务的学习和理解,相比于普通的模型,其中的增益主要体现在两个方面:
1.理解更深入。
由于已经在大量的自然语言中习得了基本的语言规律,当模型面临一个新的自然语言任务的时候,模型可以利用的知识就包含了已经习得的海量语言规律+新任务里的知识,使得模型能够更加深入新任务所表达的规律。
2.更少的样本依赖。
在BERT以前,凡是涉及自然语言理解的任务,需要少则数万,多则数十万的训练样本,才能达到一个基本的效果,而训练样本不是自然就有的,大多需要人工标注。BERT出现之后,BERT可以基于已经习得的语言规律,更好的利用样本,使依赖的标注数量降低至少一个量级,极大加快模型的理解速度。

BERT原理和BERT升级
BERT自2018年底诞生后,在业界和学术界迅速激起一层研究热潮,不断的出现以BERT为基础的改良模型,这其中典型的中文模型代表包括来自哈工大的bert_wwm以及来自百度的 ernie模型。下面我们将简单介绍BERT-base\BERT_wwm\ernie模型的基本原理。
BERT-base
BERT综合考虑了以往语言模型(例如ELMo\GPT)的缺点,基本组件使用Transformer模块,并将单向的语言模型改进成双向模型,其结构如图1所示。
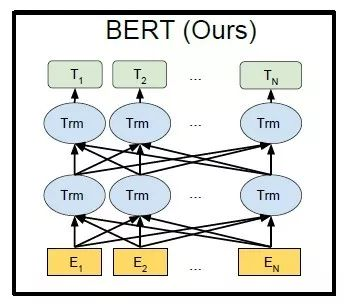
图1 BERT: Bidirectional EncoderRepresentations from Transformers
BERT所提出的双向预训练模型提出了两个预训练目标,分别是Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM随机选取15%的词进行掩码,被选中的词中,80%的词用[MASK]标记替代,10%的情况用随机挑选的词替代,另外10%的情况维持不变。由于在使用预训练模型时,输入的文本不会有[MASK]标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









