







基于生成对抗网络的动漫人物生成
- 写在前面
- 先来看看效果吧
- 项目地址
- 原理简介
- 1、角色身份张量
- 2、条件噪声
- 3、基于语义分割和边缘检测的鉴别器
- 写在后面
写在前面
博主特别喜欢二次元,想着毕业前做点自己喜欢的,因此有了这篇paper和项目。
先来看看效果吧
能够根据语义图形生成不同的人物

相比其他方法有更自然的色彩,例如背景和衣服

相比其他方法有更清晰的纹理,例如头发纹理

这是用Unity做的一个AI绘画软件,通过画语义图像生成真实动漫人物图像。
项目地址
论文地址:https://bmvc2024.org/proceedings/508/
论文代码地址:https://github.com/hahahappyboy/Semantic-Image-Synthesis-of-Anime-Characters-Based-on-Conditional-Generative-Adversarial-Networks/tree/main
软件地址:https://blog.csdn.net/iiiiiiimp/article/details/129804794
原理简介
论文已经讲的很清楚了,这里只做核心点阐述。
1、角色身份张量
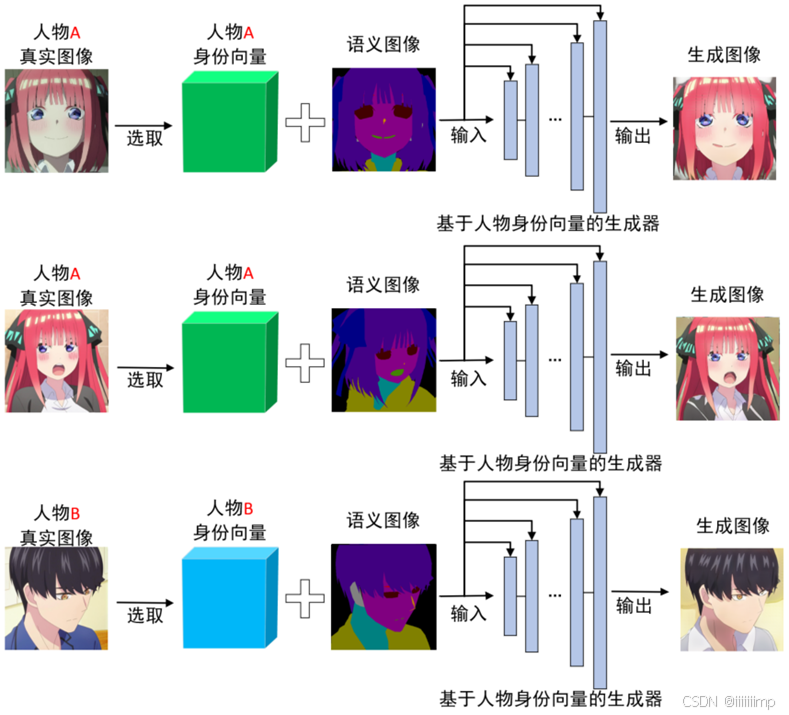
训练时将三维的张量作为生成器的输入,从而实现了通过张量控制网络生成任意角色。
具体而言,我们先为每张训练图像标注其人物身份。然后在每次迭代前根据人物身份选择对应的人物身份张量与语义图拼接后作为生成器的输入。以此让人物身份向量与特定动漫人物进行关联。例如,如果此次迭代的目标是生成角色A,我们就输入角色A身份张量。如果下次迭的目标是生成角色B,就输入角色B的身份张量。通过这种方法让角色身份张量与生成图像的人物身份关联,让生成器认为每次我输入的是角色A身份张量,那就应该生成角色A的图像。
为什么要用三维的张量,二维的不行吗?
因为语义图是三维的,二维的张量容易被网络忽略。
角色身份张量初始为正太分布,为什么不是其他分布?
因为初始化为正太分布好训练
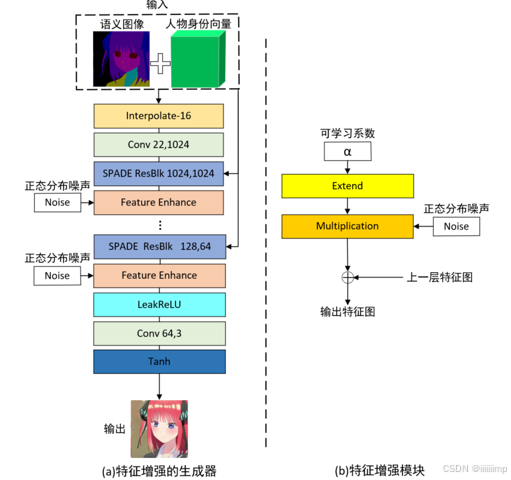
2、条件噪声
不同动漫人物图像间的色彩差异较大,导致生成的图像色彩模糊。我们分析原因是当图像间的色彩差异较大,生成器在训练时无法确定色彩特征拟合的方向,为了应对鉴别的鉴别,于是将训练图像色彩的平均值作为生成结果,这个结果色彩上看起来是模糊的,如下图。

为了增强网络的色彩拟合能力,我们借鉴StyleGAN的noise思想,将三维正态分布的噪声按通道乘以一组可学习的系数后添加到网络的特征图中,因为其系数是可学习的所以该模块自适应调节特征图的分布特征,增强网络对色彩的拟合能力。与StyleGAN不同的是,我们为每一名动漫角色都设置了单独的噪声和可学习的系数,这是考虑到同一个角色的外观色彩往往具有相似性。不同角色使用不同的噪声和可学习的系数效果更好。
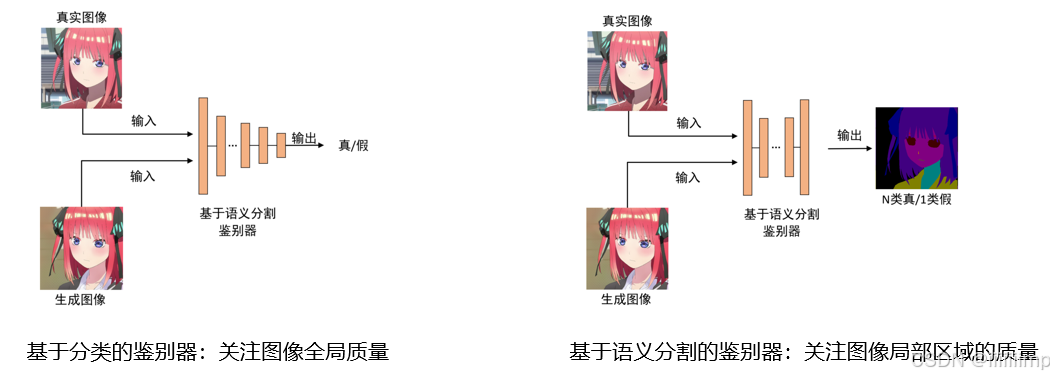
3、基于语义分割和边缘检测的鉴别器
我们分析目前基于分类的鉴别器,因为执行分类任务,所以更关注图像整体质量。 基于语义分割的鉴别器,执行分割任务所以关注图像局部区域的质量。所以的鉴别器从任务目标上就无法关注到更多的细节纹理。
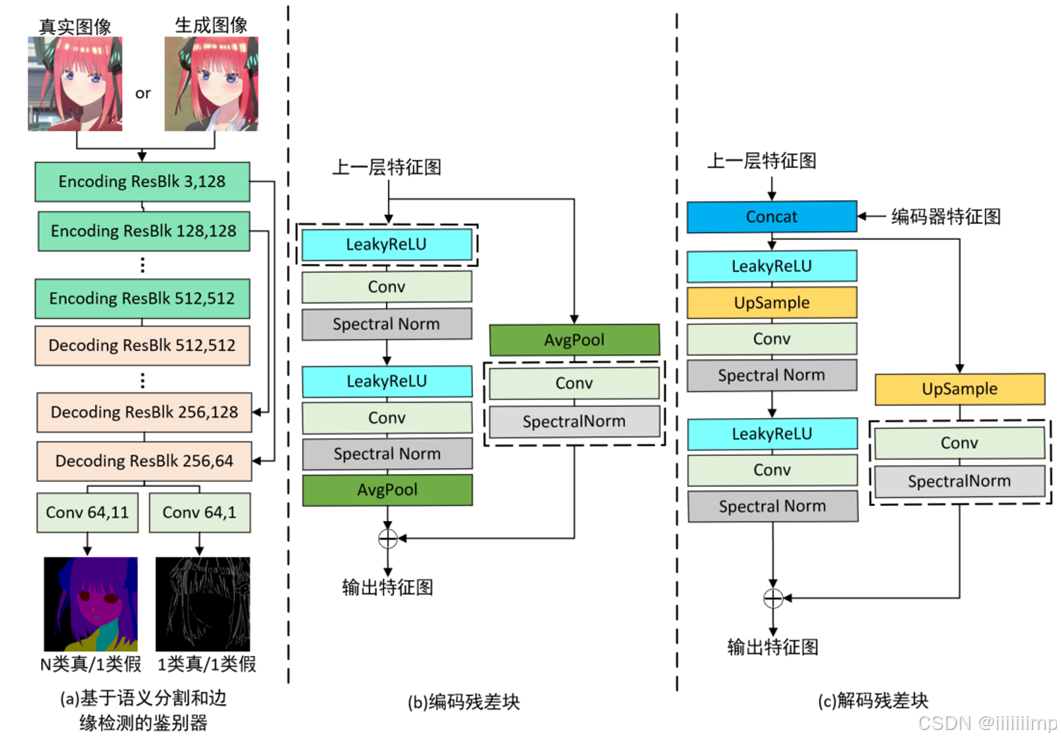
为了使鉴别器关注到到更多的纹理,我们提出了基于语义分割和边缘检测的鉴别器。我们想要通过在鉴别器中引入边缘检测实现对边缘纹理的像素级监督,具体就是在网络末端通过双分支结构同时输出语义图像和边缘图像。
写在后面
感谢二次元在我成长路上的一路陪伴,在我最艰难的时候治愈我,给予了我从未有过的人生。


















 4532
4532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









