






写在前面
最近在使用ragflow做知识库,对聊天助理的一些参数做了一些探索,这里分享一下,欢迎讨论。
助理设置页面
也就是这个页面
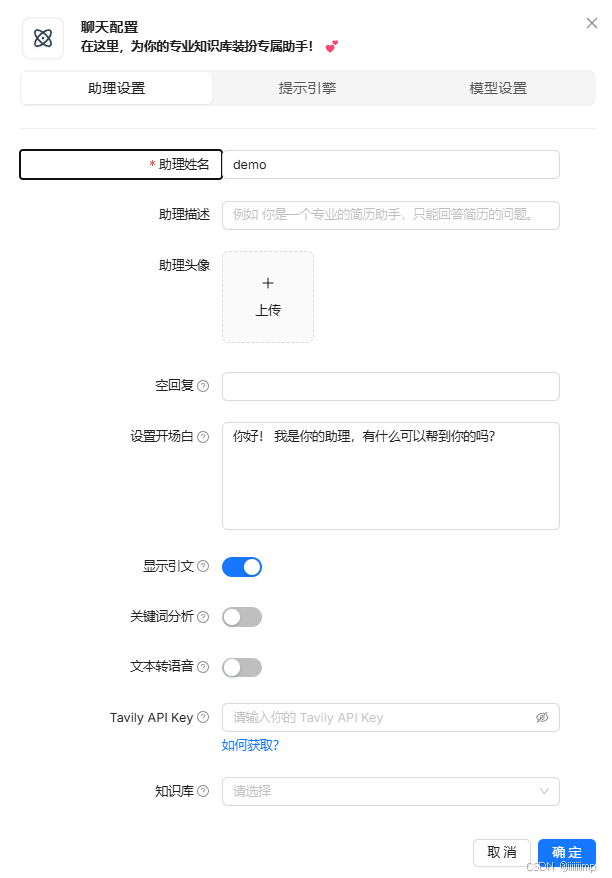
空回复
如果设置了这个值,ragflow在知识库中没有检索到用户的问题,ragflow就直接将空回复的值作为回答,此时不去询问LLM,直接回复。
如果不设置这个值,ragflow在知识库中没有检索到用户的问题,就会去询问LLM这个问题
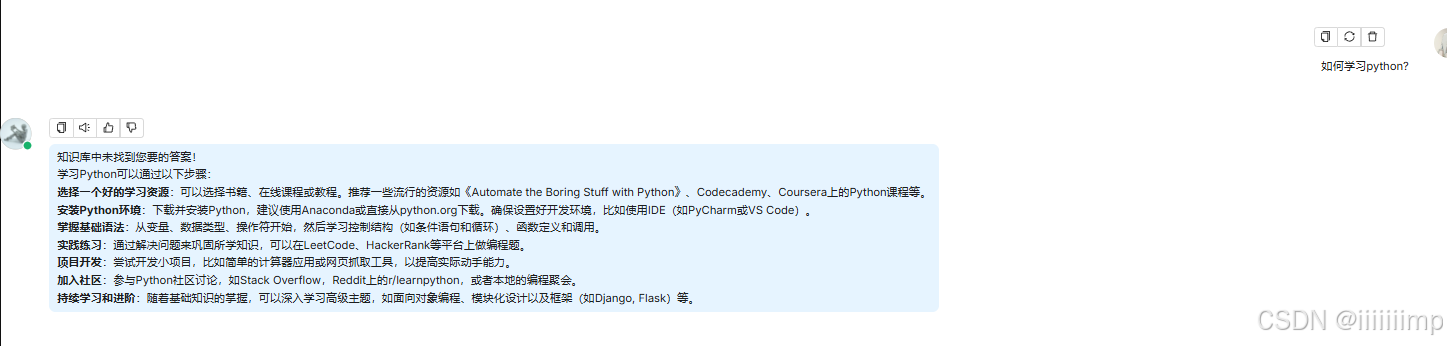
案例:
如下我们设置了空回复

可以看到AI直接回复,在知识库中没有找到

我们不设置空回复
ragflow如果没找到知识库的相关内容,就会去询问LLM我们的问题
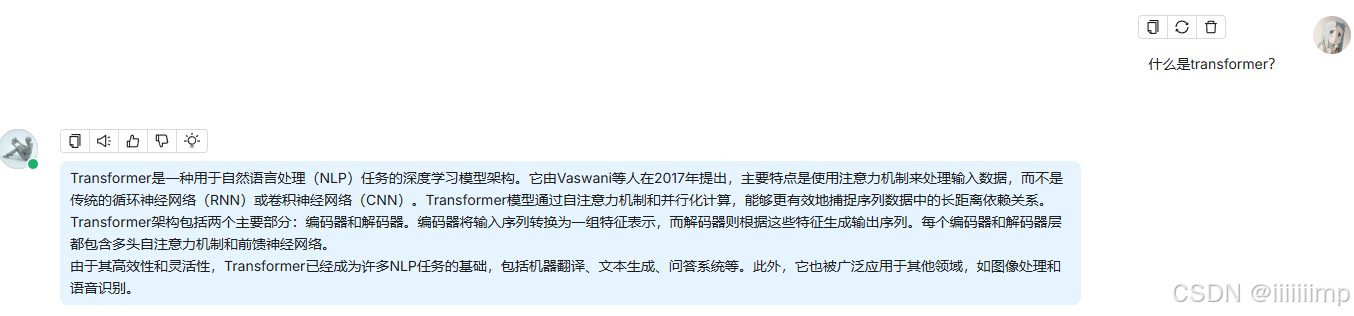
Tavily API Key
开启后,ragflow回答问题,除了检索知识库,还会检索互联网,把检索到的内容输入LLM,注意此时互联网的内容同样会被当做知识库的内容
案例:
不使用Tavily

使用Tavily ,可以看到ragflow搜索了网上的内容
提示引擎设置页面
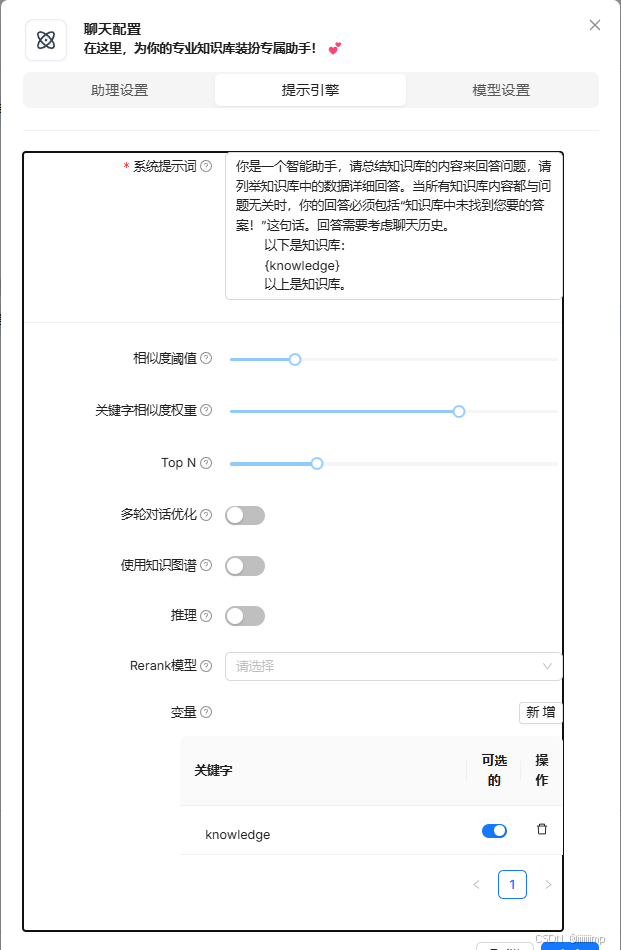
系统提示词
ragflow会将知识库搜索的知识放入提示词的 {knowledge}里,一同输入给LLM
案例:
当我们提示词为:
当所有知识库内容都与问题无关时,你的回答必须包括“知识库中未找到您要的答案!”

当我们提示词为:当所有知识库内容都与问题无关时,你可以根据你已有的知识进行回答。
可以看到AI会有自己的想法,这时就容易产生幻觉

推理
https://ragflow.io/docs/dev/implement_deep_research
一般会结合Tavily联网搜索使用
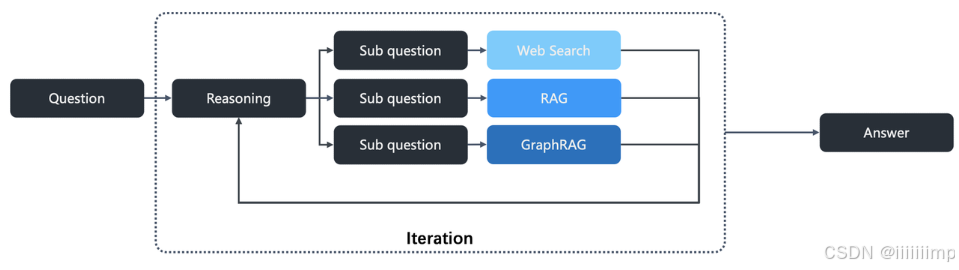
根据ragflow原文,启用后LLM集成Deep Research,Deep Research会将用户的问题拆分为多个子问题去多轮检索(模拟人的思考过程)
案例:
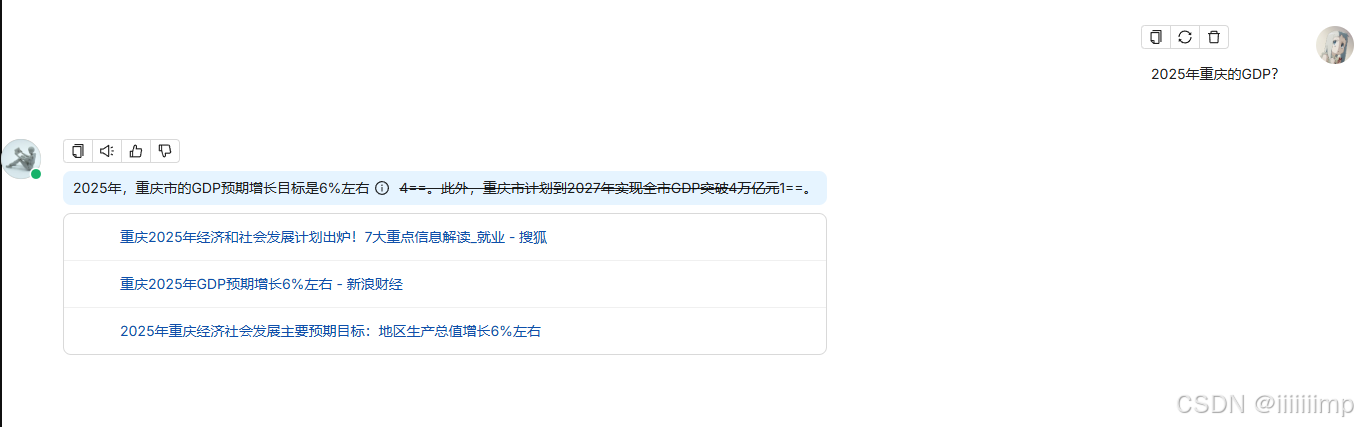
我们开启推理,问特朗普和马斯克谁的儿子更多?可以看到Deep Research会把问题分为特朗普有多少个儿子,马斯克有多少个儿子这两个问题去搜索,然后把搜索的知识给LLM

LLM会根据Deep Research搜索到的知识去回答

如果我们不开启推理,LLM就会根据自己已有的知识去回答

模型设置
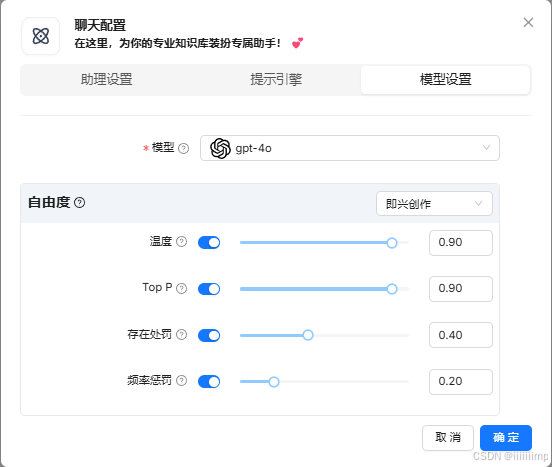
温度和Top P是影响LLM输出的随机性。
存在处罚和频率惩罚就是影响LLM输出的多样性。
强烈建议看这篇文章。
https://blog.csdn.net/u012856866/article/details/140308083
我们需要明确的是模型输出的一个单词的概率,这几个变量本质都是影响模型输出单词的概率,从而影响最终的结果。
例如,
提问:我喜欢___。
模型预测:苹果概率70%,香蕉20%,西瓜%
模型回答:苹果
但通过调节温度、Top P、惩罚。就可能让模型回答:香蕉
温度
对于同一个问题,LLM输出的随机性
值越大,对于同一个问题LLM输出的答案越相似
案例:
如果温度设置为1,那你相同的问题,LLM回答的答案基本就没变化
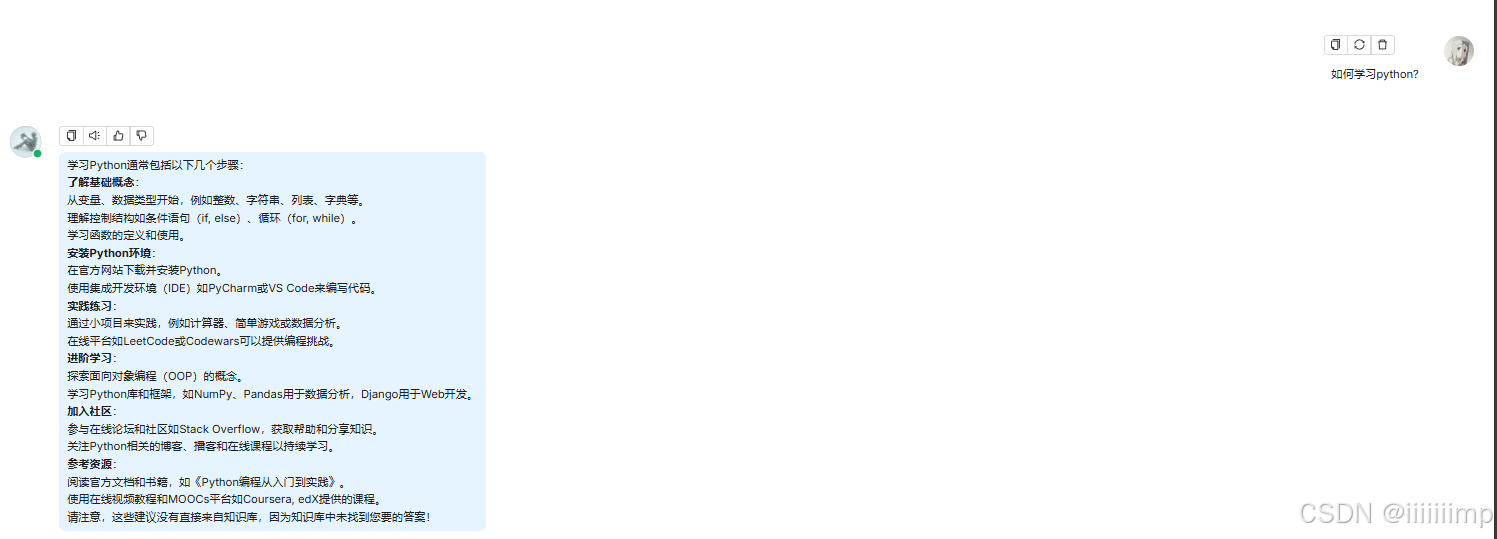
Top P
Top P也是用来控制输出的随机性。
Top P值越大,同一个问题,AI的回答就越随机,相反值越小AI回答的内容就越相同
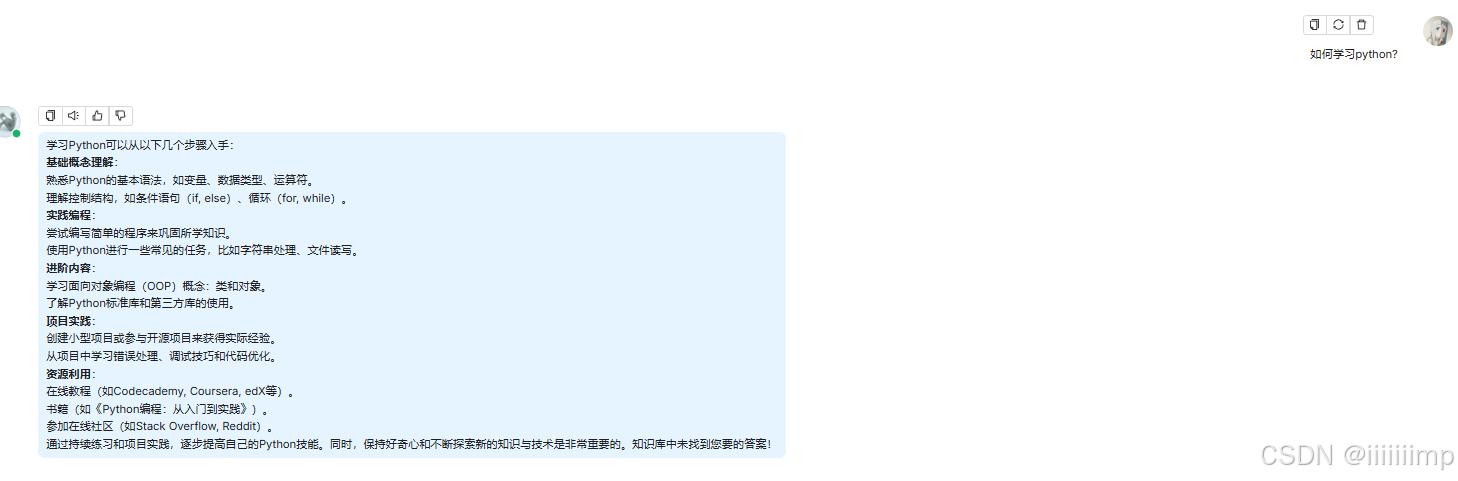
案例
我们设置Top P为1,可以看到同一个问题,两次回答AI的差别很大

存在处罚
这会通过惩罚对话中已经出现的单词来阻止模型重复相同的信息。只要这个单词LLM说过,下次说就会受到乘法
频率处罚
与存在惩罚类似,这减少了模型频繁重复相同单词的倾向。这个单词出现的频率越多,处罚越严重。
一般来说,如果只存在一个正确答案,并且您只想问一次时,就应该将频率惩罚和存在惩罚的数值设为零。但如果存在多个正确答案(比如在文本摘要中),在这些参数上就可以进行灵活处理。
写在后面
还没想好

















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









