







目录
广义线性模型
逻辑回归与线性回归都是一种广义线性模型(generalized linear model,GLM)。具体的说,都是从指数分布族导出的线性模型,线性回归假设Y|X服从高斯分布,逻辑回归假设Y|X服从伯努利分布。
伯努利分布:伯努利分布又名0-1分布或者两点分布,是一个离散型概率分布。随机变量X只取0和1两个值,比如正面或反面,成功或失败,有缺陷或没有缺陷,病人康复或未康复。为方便起见,记这两个可能的结果为0和1,成功概率为p(0<=p<=1),失败概率为q=1-p。
高斯分布:高斯分布一般指正态分布。
因此逻辑回归与线性回归有很多相同之处,去除Sigmoid映射函数的话,逻辑回归算法就是一个线性回归。可以说,逻辑回归是以线性回归为理论支持的,但是逻辑回归通过Sigmoid函数引入了非线性因素,因此可以轻松处理0/1分类问题。
这两种分布都是属于指数分布族,我们可以通过指数分布族求解广义线性模型(GLM)的一般形式,导出这两种模型,具体的演变过程如下:
(此部分参考:https://zhuanlan.zhihu.com/p/81723099)

极大似然法
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值。
极大似然估计的原理,用一张图片来说明,如下图所示:

原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。

极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
逻辑回归的假设函数
首先我们要先介绍一下Sigmoid函数,也称为逻辑函数(Logistic function):
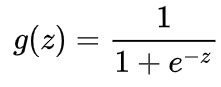
其函数曲线如下:
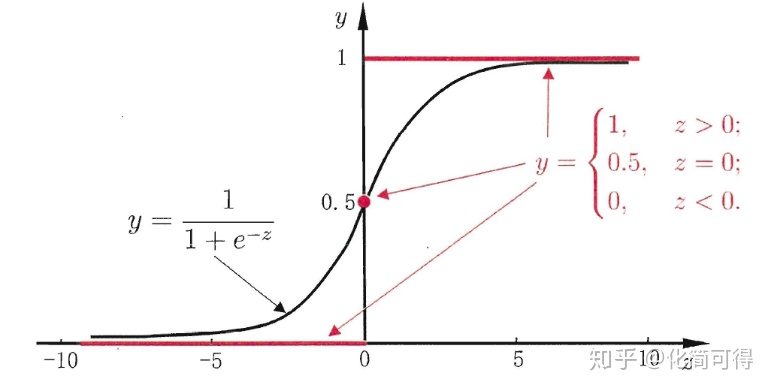
从上图可以看到sigmoid函数是一个s形的曲线,它的取值在[0, 1]之间,在远离0的地方函数的值会很快接近0或者1,它的这个特性对于解决二分类问题十分重要。
逻辑回归的假设函数形式如下:
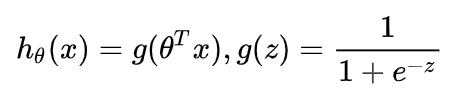
所以:
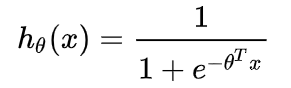
其中 x 是我们的输入,θ 为我们要求取的参数。
一个机器学习的模型,实际上是把决策函数限定在某一组条件下,这组限定条件就决定了模型的假设空间。当然,我们还希望这组限定条件简单而合理。而逻辑回归模型所做的假设是:
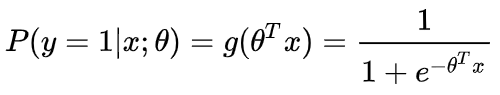
这个函数的意思就是在给定 x 和 θ 的条件下,y = 1的概率。
逻辑回归的损失函数
通常提到损失函数,我们不得不提到代价函数(Cost Function)及目标函数(Object Function)。
损失函数(Loss Function) 直接作用于单个样本,用来表达样本的误差
代价函数(Cost Function)是整个样本集的平均误差,对所有损失函数值的平均
目标函数(Object Function)是我们最终要优化的函数,也就是代价函数+正则化函数(经验风险+结构风险)
概况来讲,任何能够衡量模型预测出来的值 h(θ) 与真实值 y 之间的差异的函数都可以叫做代价函数 C(θ) 如果有多个样本,则可以将所有代价函数的取值求均值,记做 J(θ) 。因此很容易就可以得出以下关于代价函数的性质:
- 选择代价函数时,最好挑选对参数 θ 可微的函数(全微分存在,偏导数一定存在)
- 对于每种算法来说,代价函数不是唯一的;
- 代价函数是参数 θ 的函数;
- 总的代价函数 J(θ) 可以用来评价模型的好坏,代价函数越小说明模型和参数越符合训练样本(x,y);
- J(θ) 是一个标量;
经过上面的描述,一个好的代价函数需要满足两个最基本的要求:能够评价模型的准确性,对参数 θ 可微。
在线性回归中,最
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









