







作者:Dmytro Mishkina, Nikolay Sergievskiyb, Jiri Matasa
DOI: 10.1016/j.cviu.2017.05.007
@Article{CaffeNetBench2017,
Title = {Systematic evaluation of convolution neural network advances on the Imagenet },
Author = {Dmytro Mishkin and Nikolay Sergievskiy and Jiri Matas},
Journal = {Computer Vision and Image Understanding },
Year = {2017},
Doi = {https://doi.org/10.1016/j.cviu.2017.05.007},
ISSN = {1077-3142},
Keywords = {CNN},
Url = {http://www.sciencedirect.com/science/article/pii/S1077314217300814}
}1、 本文作出了以下贡献:
1.1 广泛调查研究了当时的模型架构和超参数选择(独立及联合),提出一些对建立深度卷积网络的建议。
1.2 证明了ImageNet-128px(144×N,N≥128)是快速可靠的基准模型。
1.3 所有试验可重复,代码和数据均已上线:GitHub - ducha-aiki/caffenet-benchmark: Evaluation of the CNN design choices performance on ImageNet-2012.
2、评估框架
2.1 模型架构
2.1.1 分辨率越低,准确度越低。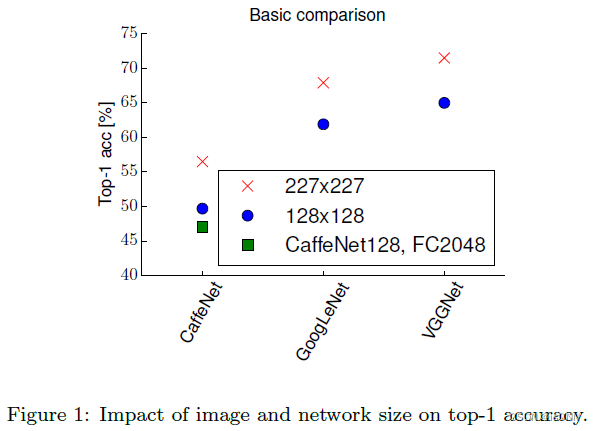
2.1.2 学习过程
SGD带0.9动量,初始学习率0.01,
3、单一超参数实验
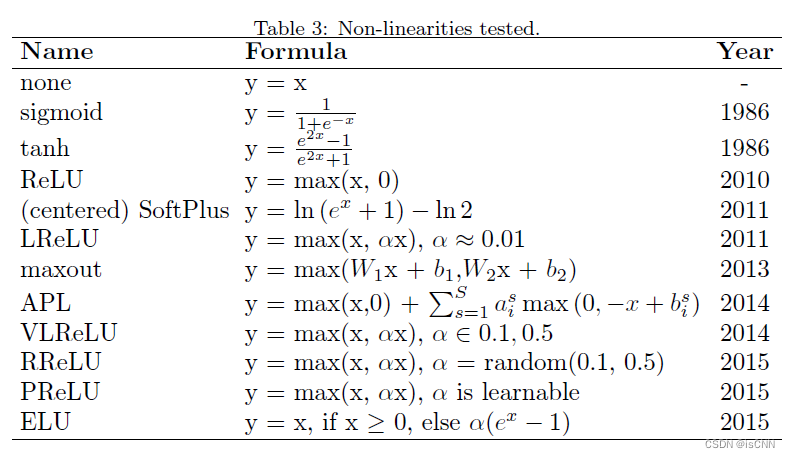
3.1 激活函数
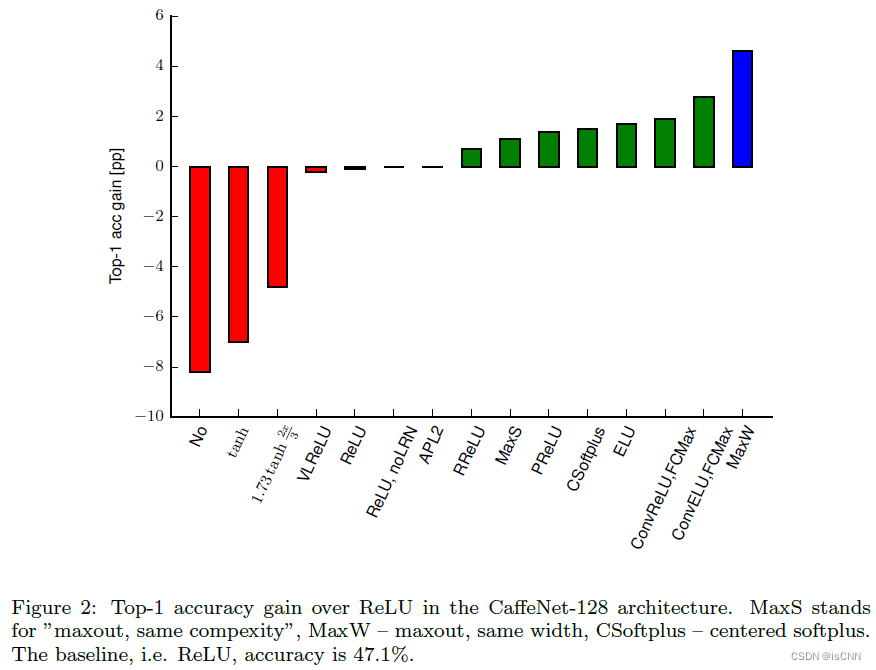
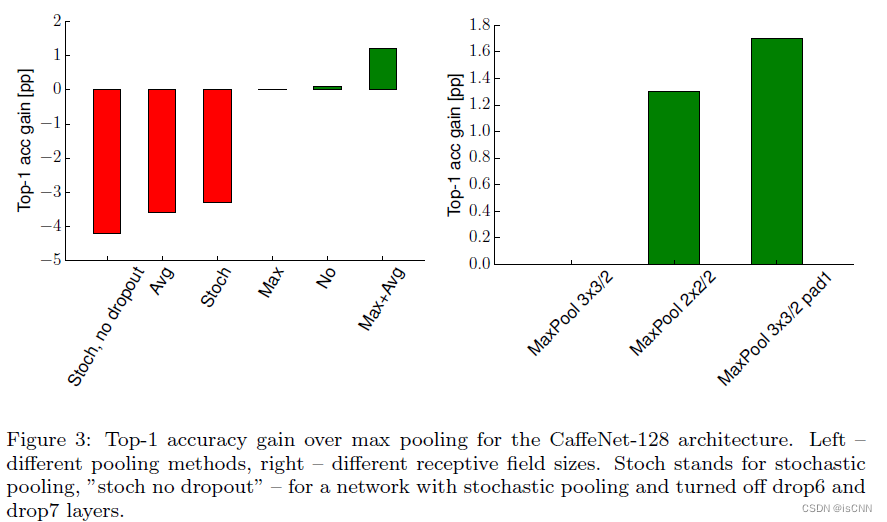
3.2 池化

3.3 学习率
学习率极其重要,实践中行之有效、基于经验的策略是“当验证损失停止下降时,学习率降低到原来的十分之一”。
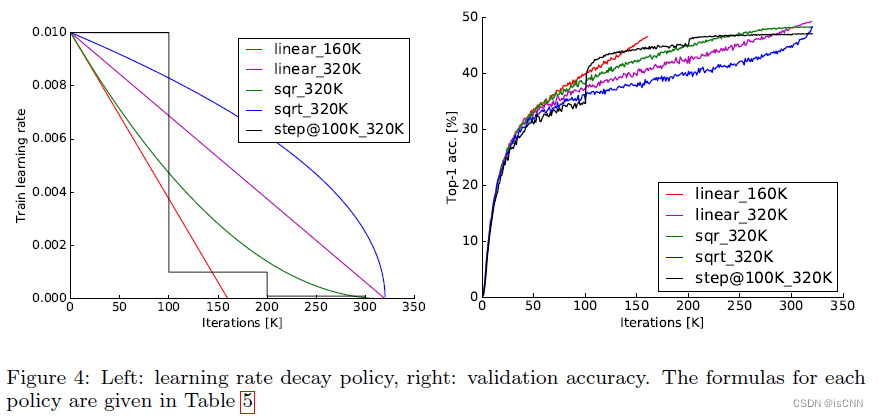

学习率线性下降的实验结果最好。
3.4 图像预处理
对于CNN,RGB通道最合适。
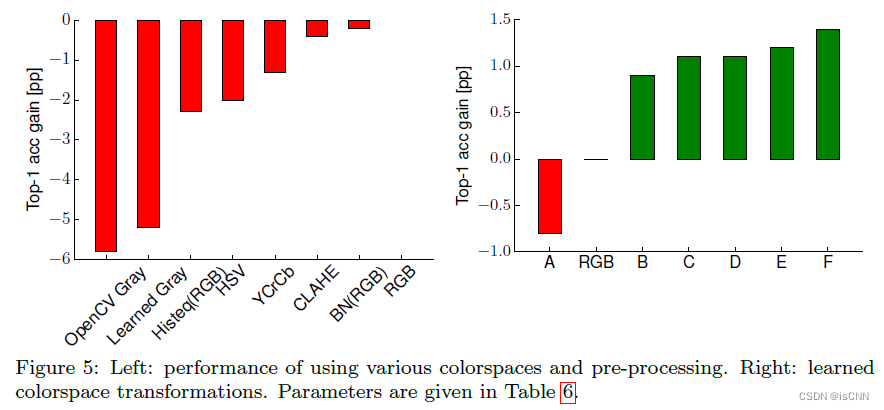
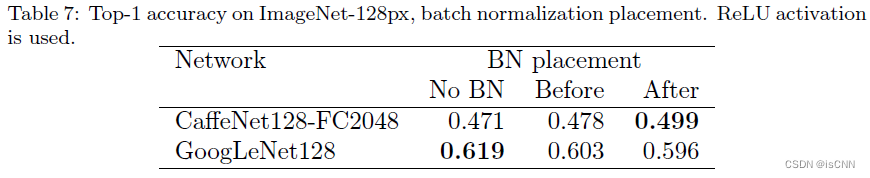
3.5 批次归一化
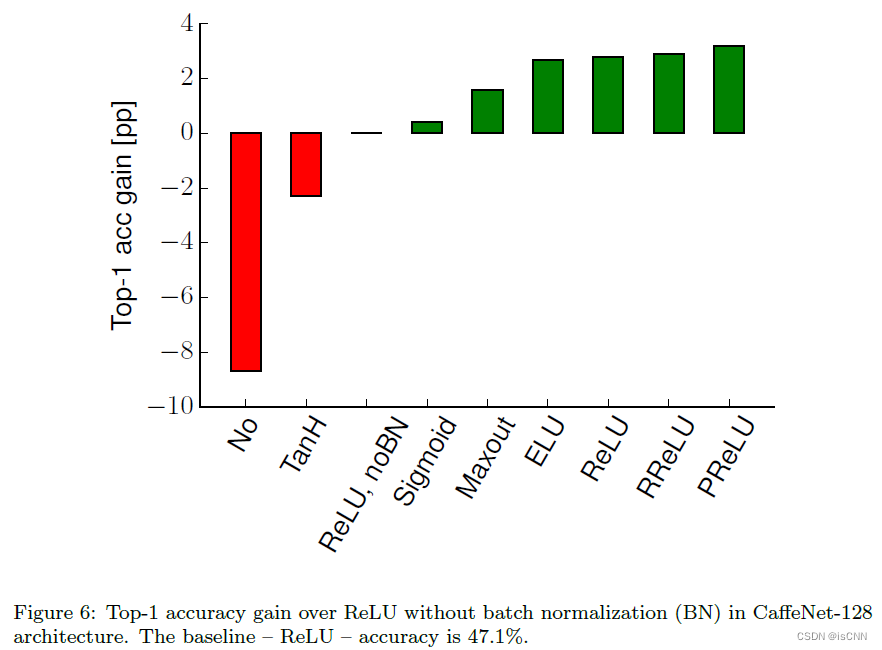
BN抹平了ReLU家族函数间的差距,所以没必要使用复杂的ReLU激活函数(如果BN了的话)。
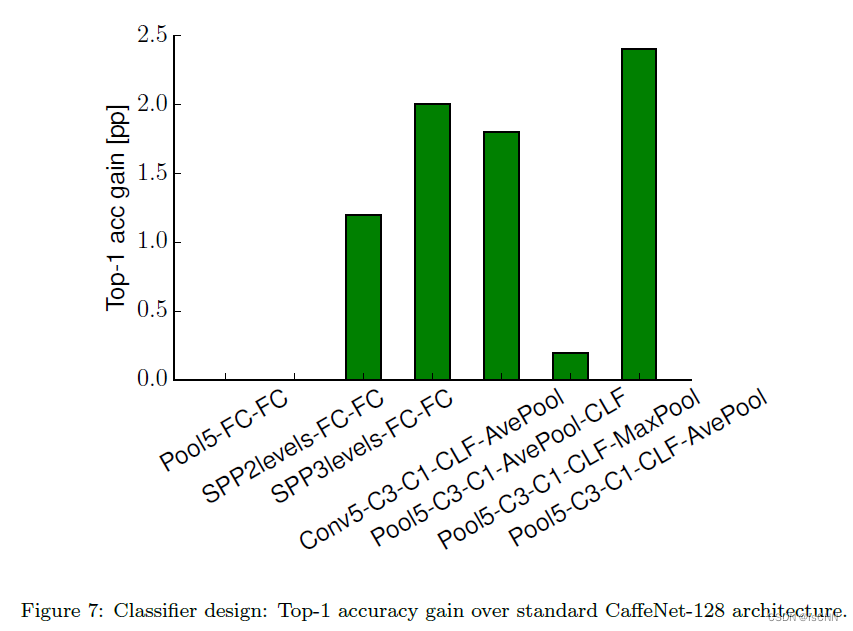
3.6 分类器设计
CNN可视为由特征提取器和分类器构成。
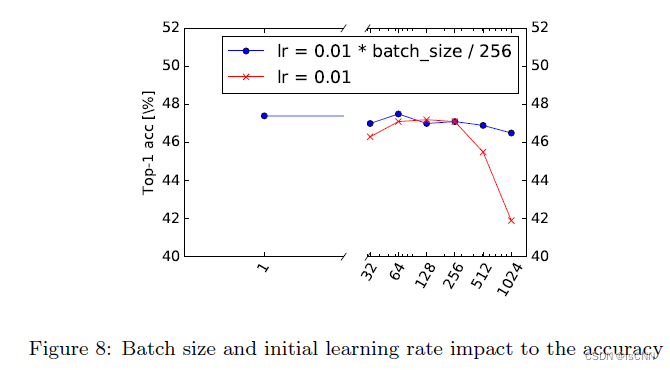
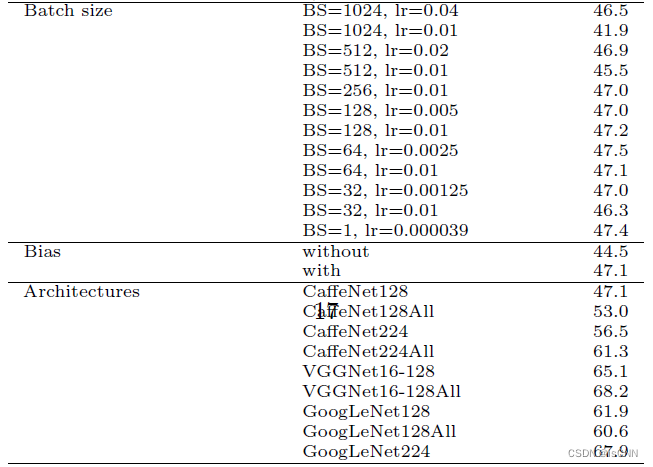
3.7 批大小和学习率
若不同大小的批次使用相同的学习率,效果不好。
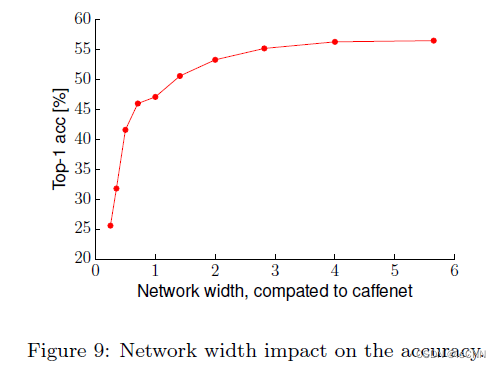
3.8 网络宽度
3.9 输入图像尺寸
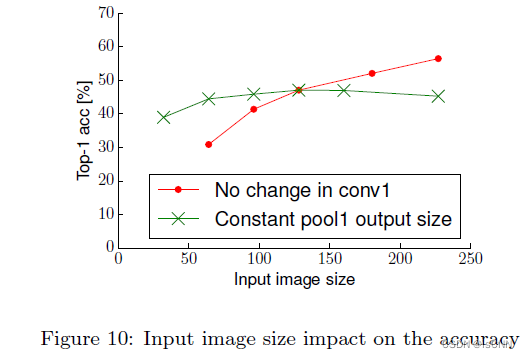
准确度随图像尺寸线性增长,然而计算成本是平方增长。
从大尺寸图像中获得的准确性增长主要是因为可以获得更深的卷积层数,而不是因为包含了更多不可见的图像细节。
3.10 数据集大小和噪声标签
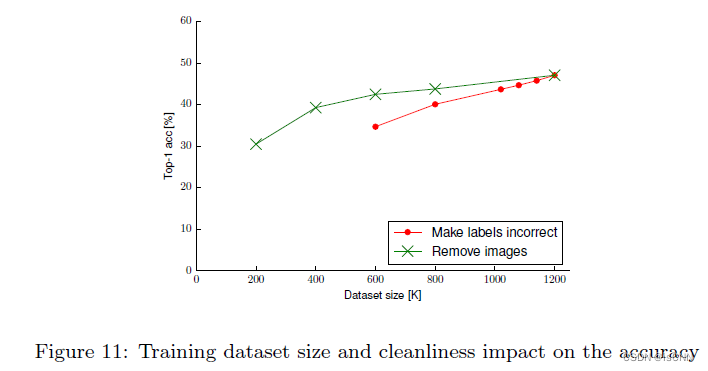
更大、更多样的数据集可以改进准确度。小而干净的数据集要比更大但噪声更多的数据集表现好。
3.11 卷积层中是否有偏差参数(bias)

4. 单一最优参数组合实验
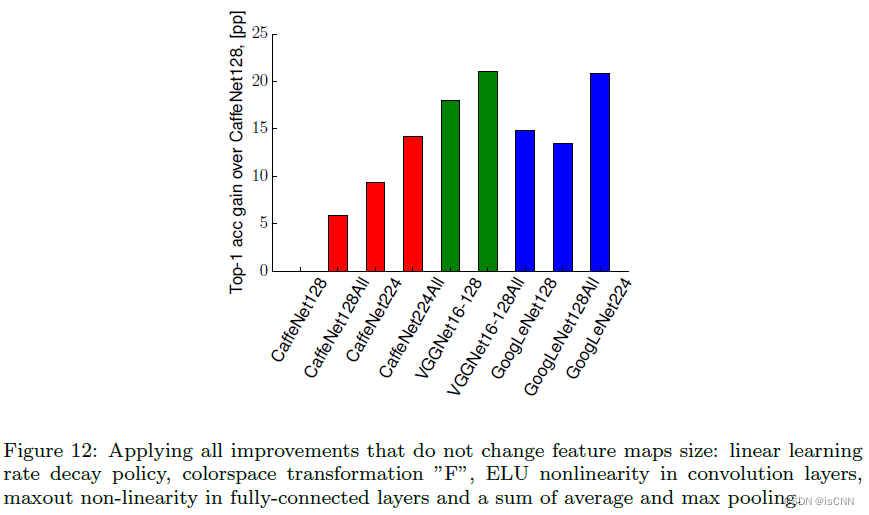
结合图像预处理方式F、卷积层使用ELU激活函数、全连接层使用maxout函数,学习率线性下降策略,平均结合最大池化。
CaffeNet128, CaffeNet224, VGGNet128均有提高,而GoogLeNet表现下降,VGGNet224训练成本过高,GPU时间长达一月,故未在实验中使用该模型。
5. 结论
use ELU non-linearity without batchnorm or ReLU with it.
apply a learned colorspace transformation of RGB.
use the linear learning rate decay policy.
use a sum of the average and max pooling layers.
use mini-batch size around 128 or 256. If this is too big for your GPU, decrease the learning rate proportionally to the batch size.
use fully-connected layers as convolutional and average the predictions for the final decision.
when investing in increasing training set size, check if a plateau has not been reach.
cleanliness of the data is more important then the size.
if you cannot increase the input image size, reduce the stride in the consequent layers, it has roughly the same effect.
if your network has a complex and highly optimized architecture, like e.g. GoogLeNet, be careful with modifications.
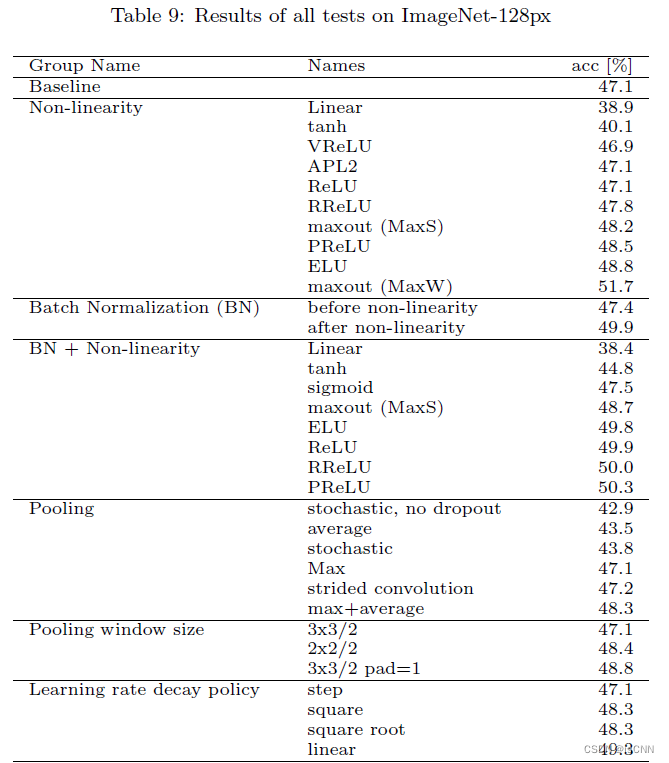
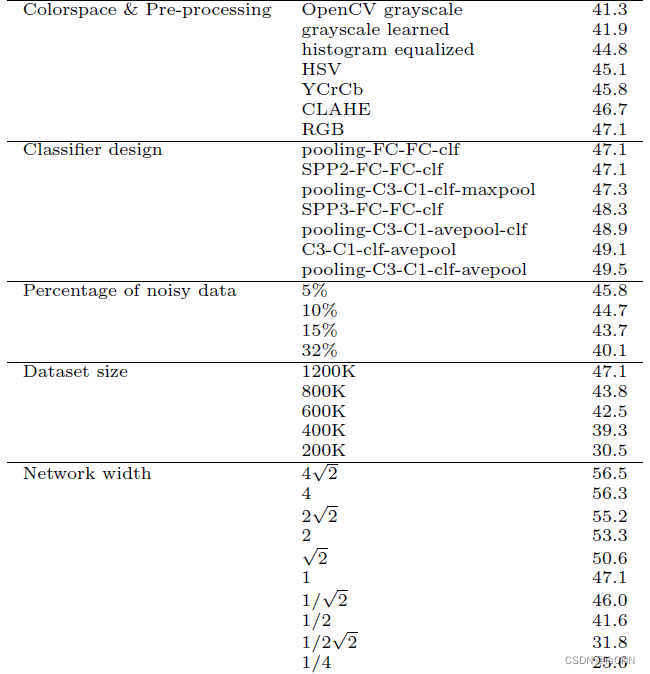















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









