







作者:
Zou, Q (Zou, Qin) [1] ; Jiang, HW (Jiang, Hanwen) [2] ; Dai, QY (Dai, Qiyu) [3] ; Yue, YH (Yue, Yuanhao) [1] ; Chen, L (Chen, Long) [4] ; Wang, Q (Wang, Qian) [1]
DOI
10.1109/TVT.2019.2949603
@article{zou2019tvt,
title={Robust lane detection from continuous driving scenes using deep neural networks},
author={Q. Zou and H. Jiang and Q. Dai and Y. Yue and L. Chen and Q. Wang},
journal={IEEE Transactions on Vehicular Technology},
volume={69},
number={1},
pages={41--54},
year={2020},
}3. 本文提出的方法
结合DCNN和DRNN,用于车道检测任务。
3.1 系统总览
实际驾驶场景中,车载摄像头捕捉到的画面是连续的, 连续帧之间的车道标志往往重叠,使得车道检测是基于时间的预测任务。RNN适用于连续信号处理、特征提取和整合。CNN适用于处理大型图像。通过连续卷积和池化,输入图像可抽取得到(多个)较小尺寸的特征图。连续帧的特征图包含了时间属性,可以用RNN结构得到较好处理。
为了整合CNN和RNN作为端到端网络,本文使用了编码器-解码器架构,如下图。

编码器CNN以一系列连续帧作为输入,处理每一帧图像获得以时间为序列的特征图;随后传入LSTM网络进行车道信息预测;LSTM的结果再输入到解码器CNN,得到车道预测的概率图。车道概率图的尺寸与输入图像相同。
3.2 神经网络设计
1)LSTM网络:LSTM效果一般优于传统RNN模型,因其可以遗忘不重要的信息并保留本质特征。
本文采用了双层LSTM模型,一层用于连续特征提取,另一层用于整合。
传统全连接LSTM费时且需要大量计算,本文神经网络采用了ConvLSTM[X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W. chun Woo, “Convolutional LSTM network: A machine learning approach for precipitation nowcasting,” in Proc. Adv. Neural Inf. Process. Syst., 2015, pp. 802–810.]
本文网络中,ConvLSTM的输入输出尺寸与编码器生成的特征图相同。对于Unet-ConvLSTM是8×16,SegNet-ConvLSTM是4×8. 卷积核大小是3×3. ConvLSTM有2个隐藏层,每层有512个维度。
2) 编码器-解码器网络:编码器-解码器架构将车道检测任务抽象为语义分析任务。受SegNet[V. Badrinarayanan, A. Kendall, and R. Cipolla, “Segnet: A deep convolutional encoder-decoder architecture for image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 12, pp. 2481–2495, Dec. 2017.]和U-Net[O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Proc. Int. Conf. Med. Image Comput. Comput. Assisted Intervention, 2015, pp. 234–241.]架构启发,本文将ConvLSTM模块嵌入到编码器解码器之间。编码器-解码器为全卷积网络,因此,架构设计的核心问题是卷积层数、卷积核大小及数量。SegNet的编码器用了VGGNet的16层卷积-池化结构。本文的编码器参考了SegNet和U-Net并精简了卷积核数量和卷积-池化层数,以取得准确度和效率之间的平衡。编码器结构如下图。
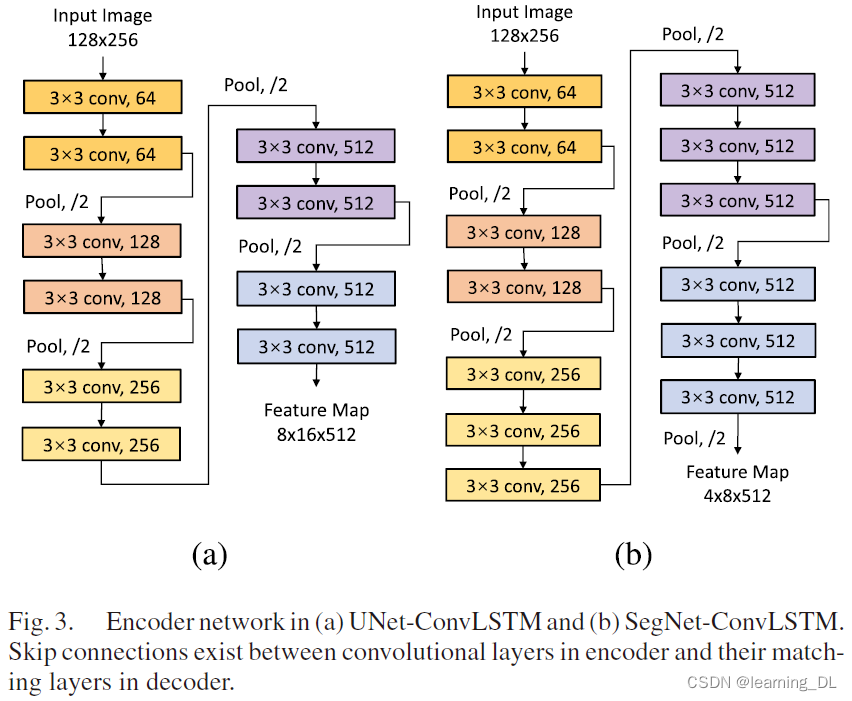
对编码器、解码器CNN,文章总体采用Convolution-BatchNorm-ReLU作为卷积操作过程,所有卷积采用相同padding策略。
3.3 训练策略
考虑以下四个方面:
1) 初始权重采用了SegNet和U-Net在ImageNet数据集上的预训练权重。
2) N帧连续的驾驶场景作为输入以判定车道,因此,反向传播中,ConvLSTM的每次权重更新都要除以5. 本文实验以N=5作为基准,并研究了N对模型表现的影响。
3) 使用带权重的交叉熵作为误差函数。

4) 为更高效地训练模型,文章在不同训练阶段采用了不同的优化器。初期采用了Adam优化器。当网络达到一定准确度后,使用SGD优化器,更小的学习率以找到全局最优解。

当训练精度达到90%时改变优化器。
4. 实验及结果
4.1 数据集
文章构架了基于TuSimple和自制的数据集。TuSimple数据集包含了3626个视频,每个视频长度1秒,含20帧,,第20帧标记有车道实际位置。为增加数据集,文章另外标记了每个视频的第13帧。作者另外增加了1148个乡村道路视频到数据集中。

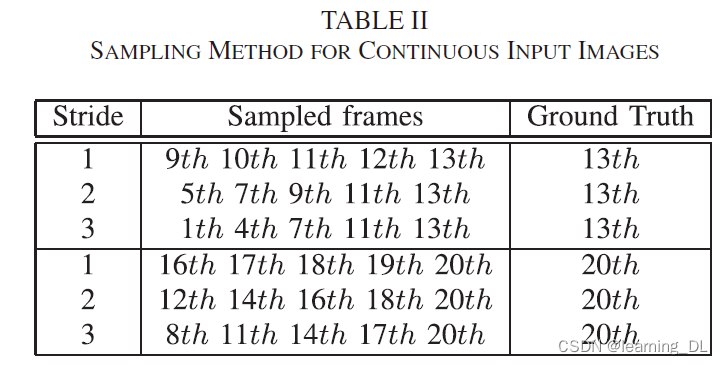
训练过程中,作者选取了5个视频(最后一帧含车道真实位置),并在最后一帧预测车道,基于第13帧和20帧的图像,可以建立起训练集。同时,为了增强网络在不同车速下车道加测的普适性,作者以3种不同的步长(即间隔1帧、2帧、3帧)取样视频图像,如下表。
数据集增强,采用了旋转、翻转、裁剪等方式,生成19096个视频,包含了38192张带标签图像。输入图像会随机改变亮度,使数据集更加多样。
对于测试过程,作者同样选取5个视频,最后一帧预测车道,并与真实位置对比。作者构建了2套测试集,测试集1基于TuSimple,用于正常测试,测试集2由各种情景下更加困难的样本构成,用于评估鲁棒性。
由于车道线的多样性,如虚线、单实线、双实线等,标注真实车道线位置时需要统一标准,文章使用单实线标注车道线。然而,对于语义分析任务,模型从像素级别识别目标边界,使用线条标记似乎不够合适。图像中的车道线在近景会比远景更宽,所以作者降低了输入图像的分辨率。考虑到车道检测的目的是避免车辆偏离车道,没有必要准确识别出车道图形的边界。在实验中,作者降低了场景图像的分辨率,这样图像中的车道线将会变得较细,接近1像素。下图展示了一个实例。另外,使用低分辨率的图像可以使模型免受复杂背景材质的影响。

4.2 实施细节
实验用图像分辨率为256×128,硬件是Intel Core Xeon E5-2630@2.3GHz,64GB RAM,和两块GeForce GTX TITAN-X GPU. 为验证低分辨率图像的适用性和模型表现,测试集场景包含了雨天、多云、晴天等场景。训练批次大小为16,迭代次数100.
4.3 性能表现和比较
文章做了两个实验,一,从视觉和定量角度评价所提出网络的性能;二、困难场景下该框架的鲁棒性验证。
1) 总体表现:UNet-ConvLSTM和SegNet-ConvLSTM分别与其原基准及一些改进版本进行了对比,具体包含以下方法。
SegNet:用于语义分析的经典编码-解码神经网络架构,编码器与VGGNet相同。
SegNet_1×1:在编码解码器之间加入了4×8卷积核,生成1×1×512的特征图。
SegNet_FcLSTM:在SegNet_1×1的编码器网络后使用全连接LSTM(FcLSTM),用于提取连续画面中的时序特征。
SegNet_ConvLSTM:作者提出的一种混合神经网络,编码器网络后使用卷积LSTM(ConvLSTM)。
SegNet_3D:通过堆叠连续画面,将其视为3D结构,进而使用3D卷积核,同时获得空间和时序特征。
Five UNet-based networks:用调整的U-Net代替SegNet的编码和解码器,如第三章中所介绍的,据此生成了另外五种网络。
以上模型的训练结果将通过视觉和定量分析的方式进行比较,以体现出本文所提框架的先进之处。
视觉检查:优秀的语义分析神经网络应该事无巨细的将输入图像精确分割为不同部分。
宏观角度而言,模型应正确预测出车道总数。具体来说,车道检测要避免两个错误,一、漏检,将车道识别为图像背景;二、误检,将背景中的其他物体误认为是车道。
微观角度而言,在满足宏观目标的前提下,尽可能减小预测与真实车道线间的位置、长度偏差。更进一步,预测图应避免大的线段断点和模糊。
实验证实本文模型表现优于其他网络。如下图。

首先,本文框架既不漏检也不误检车道线。其他方法容易将路肩等误检测为车道线。文章所提方法的预测途中,每条白细线代表了真实的一条车道线,展现了强大的边界区分能力,保证了车道线数量准确。
其次,本文方法检测的车道线位置与实际位置非常接近,有利于真实场景下的ADAS系统应用。
第三,本文的模型使用细白线标记,不会产生模糊区域。
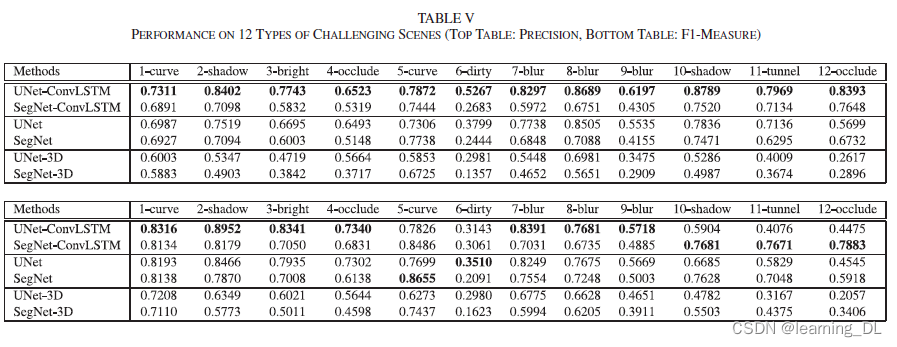
定量分析:最简单的定量评估标准是准确度,通过每个像素是否分类正确来衡量。
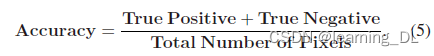
如下表,ConvLSTM比UNet提高约1%,比SegNet提高1.5%左右。

精确度和召回率更加公平合理,定义如下:

车道检测任务中,车道线是正类别,背景是负类别。
本文方法更细的实线标记车道,降低了将图像中车道线附近的背景像素误认为是车道线的可能性,
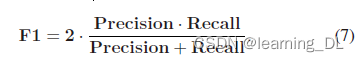
在语义分割框架中,ConvLSTM处理时序数据更有效。
3D卷积在光流(optical-flow)预测中展现了强大能力。但在车道检测任务中表现不好,可能是因为3D卷积核不易描述时序特征。
相比于其他方法,本文所提模型训练时间稍长。
鲁棒性实验使用了2号数据集——一个全新的更多样的真实驾驶场景数据集。下图展示了部分未做后处理的检测结果。

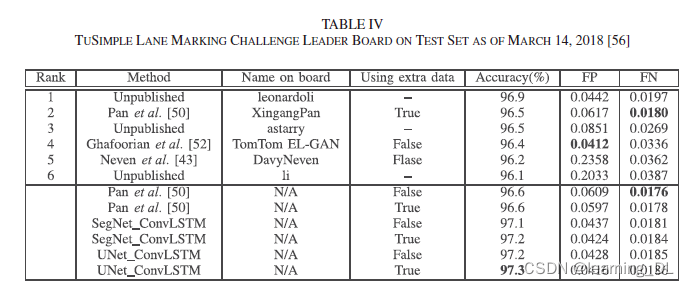
下表显示出UNet-ConvLSTM在准确性上完胜其他方法
作者还在急剧变化的驾驶环境中测试了所以方法,如,车辆进出大桥的影子。下图展示了该方法的鲁棒性。

4.4 参数分析
主要有两个参数影响本文方法。一、输入视频的帧数,二、取样的步长。
帧数增加可以使模型生成更多预测图,对于最终结果可能有所帮助,但另一方面,过多的之前帧会使得预测结果偏离当前帧。不同帧数和取样步长参数组合实验结果见下表。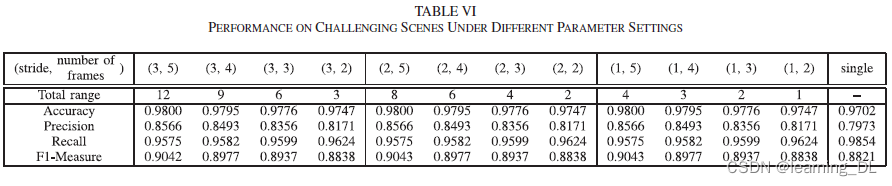
取样步长似乎没有影响。
5. 结论
本文提出了一种结合CNN和RNN的混合神经网络。网络框架基于编码器-解码器框架,使用多帧连续图像作为输入,基于语义分割预测当前帧图像的车道位置。首先,每帧图像进入CNN编码器,连续的编码特征进入ConvLSTM处理,最后,进入CNN解码器进行信息重建和车道预测。性能评估使用了两套驾驶视频数据集。
相比使用一张图像作为输入的架构,本文提出的架构表现显著提高,验证了使用多张连续帧作为输入的有效性。同时,实验展示在时序特征学习和车道检测任务下目标信息预测,ConvLSTM相比比FcLSTM的优越性。本文提出的方法在准确度和鲁棒性均有提高。
在有强干扰的昏暗环境中,SegNet-ConvLSTM表现比UNet-ConvLSTM好,这需要进一步研究。

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









