







B Ravi Kiran , Ibrahim Sobh , Victor Talpaert , Patrick Mannion , Ahmad A. Al Sallab,
Senthil Yogamani , and Patrick Pérez
调研(D)RL在自动驾驶中的应用。
目录
3.4 基于模型(vs.无模型)和On/Off Policy 方法
5.4 从示例学习(LfD)和逆强化学习(IRL)的自动驾驶应用
1. 绪论
自动驾驶(AD)在感知级别的任务已通过深度学习的方法达到了较高的准确率。然而,除了感知,对于自动驾驶系统中的多个任务,经典的监督学习方法不再适用,如城区最佳驾驶速度优化、碰撞时间预测(TTC)、轨迹优化等,这些任务的智能体更加动态,环境更加不确定。这些问题需要定义的随机成本函数最大。其次,智能体需要学习环境的新变化,以及需要在驾驶环境中做出即时的最佳决策。这需要更高、相对更大的维度空间,以同时观察智能体本身和环境的参数。这些场景的目标是求得序列决策流程,这在经典强化学习(RL)中已正式提出。智能体需要学习、表征其所处环境,并随即优化其行为,最佳行动称为策略(policy)。
本综述涵盖多种强化学习方法,RL在驾驶策略、感知预测、路径运动规划、以及低级控制器设计方面应用广泛。本综述同时聚焦于RL在真实世界自动驾驶领域部署。
综述内容总结如下:
- 汽车领域中强化学习背景。
- 有关RL在不同自动驾驶任务中应用的详细文献调研。
- 真实世界自动驾驶应用RL的关键挑战和机遇。
2. 自动驾驶(AD)系统的组成
下图展示了AD系统的标准模块,从感知流到控制激活。
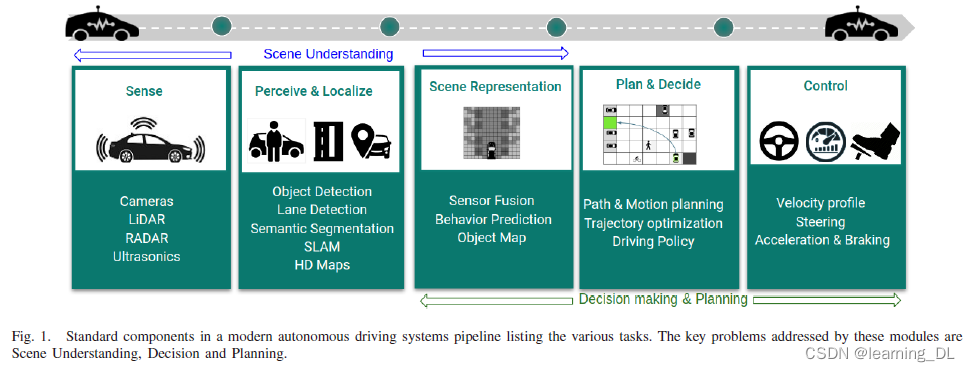
感知模块包括多个摄像头、雷达、激光雷达(LIDAR)、GPS-GNSS、IMU(提供车辆三维姿态)等。感知模块的目标是提供实时环境状态表征(如一幅含周边障碍物和智能体的鸟瞰图),感知结果随后被决策系统使用,最终制定驾驶策略。感知中的不确定性会传递到信息链下游。所以感知模块的鲁棒性很关键,冗余可以增加检测信度。感知由多个任务组成,如语义分割、运动预测、深度预测、地面检测等,这些可以归为多任务模型。
2.1 场景理解
这一模块处于感知模块和更高一级的动作决策模块之中。基于探测或定位算法,理论上,这一模块包含三个任务:场景理解、决策和规划(如图1所示)。通过融合多种传感器,这一模块目标是鲁棒地抽象出场景内容,为决策模块提供通用和简化的内容。
感知融合由传感器提供了环境的不确定表征,为不同类型的传感器(激光雷达、摄像头、雷达、超声波)噪声和不确定性建模,这通常需要一定的原则进行预测。
2.2 定位和建图
建图是自动驾驶的关键支柱。一片区域见图完成,车辆当前在图中的位置即可确定。Google首次可靠的自动驾驶演示即依赖于在预先建好图的区域中定位。传统的建图技术可通过语义目标检测,消除不确定性得到增强。另外,高精地图(HD maps)可前置于目标检测应用。
2.3 规划和驾驶策略
轨迹规划是自动驾驶流程中的关键一环。在车道级地图(基于高精地图或GPS)中,该模块需生成动作级的指令,控制智能体转向。
传统的运动规划在控制智能体姿态时忽略了动态变化和约束条件。一个具备6自由度控制的智能体被称为完整性约束,少于6自由度是非完整的。传统算法,如基于迪杰斯特拉算法的A*算法无法用于非完整约束的自动驾驶。RRT算法可用于非完整约束,通过随机采样和障碍物规避路径生成,寻找到合适的参数配置。当前在自动驾驶运动控制领域,RRT及其多个变种算法广泛应用其中。
2.4 控制
在预建立地图(如Google地图)的每一观察点处,控制器定义了速度、转向角度和刹车动作,或在每一个路点使用相同参数的预定义记录。相对而言,轨迹预测包含了每一时序路点上的车辆瞬时动态模型。
当前车辆控制方法基于经典的优化控制理论,表述为成本函数![]() 的最小化,x(t)是一系列状态,u(t)是控制动作。控制的输入通常定义于有限时间范围,限制于可行状态空间
的最小化,x(t)是一系列状态,u(t)是控制动作。控制的输入通常定义于有限时间范围,限制于可行状态空间![]() 。速度控制基于经典闭环控制方法,如PID、MPC。PID目标是最小化代价函数,其三部分中,比例控制最小化当前误差,积分控制最小化历史误差,微分控制最小化未来误差。MPC方法目标是在追踪定义路径时稳定车辆行为。[W. Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decisionmaking for autonomous vehicles,” Annu. Rev. Control, Robot., Auto. Syst., vol. 1, no. 1, pp. 187–210, May 2018.] 做了控制器、运动规划和基于学习的方法文献综述。优化控制和强化学习联系紧密,优化控制可视为是一种基于模型的强化学习问题,其中车辆动力学模型和环境通过预定义的微分方程定义。强化学习用于处理随机控制,以及奖励和状态转化概率未知的病态姿态问题。自动驾驶随机控制是一个很大的领域,这一课题的综述可以参考[S. Kuutti, R. Bowden, Y. Jin, P. Barber, and S. Fallah, “A survey of deep learning applications to autonomous vehicle control,” IEEE Trans. Intell. Transp. Syst., early access, Jan. 7, 2020, doi: 10.1109/TITS.
。速度控制基于经典闭环控制方法,如PID、MPC。PID目标是最小化代价函数,其三部分中,比例控制最小化当前误差,积分控制最小化历史误差,微分控制最小化未来误差。MPC方法目标是在追踪定义路径时稳定车辆行为。[W. Schwarting, J. Alonso-Mora, and D. Rus, “Planning and decisionmaking for autonomous vehicles,” Annu. Rev. Control, Robot., Auto. Syst., vol. 1, no. 1, pp. 187–210, May 2018.] 做了控制器、运动规划和基于学习的方法文献综述。优化控制和强化学习联系紧密,优化控制可视为是一种基于模型的强化学习问题,其中车辆动力学模型和环境通过预定义的微分方程定义。强化学习用于处理随机控制,以及奖励和状态转化概率未知的病态姿态问题。自动驾驶随机控制是一个很大的领域,这一课题的综述可以参考[S. Kuutti, R. Bowden, Y. Jin, P. Barber, and S. Fallah, “A survey of deep learning applications to autonomous vehicle control,” IEEE Trans. Intell. Transp. Syst., early access, Jan. 7, 2020, doi: 10.1109/TITS.
2019.2962338.]。
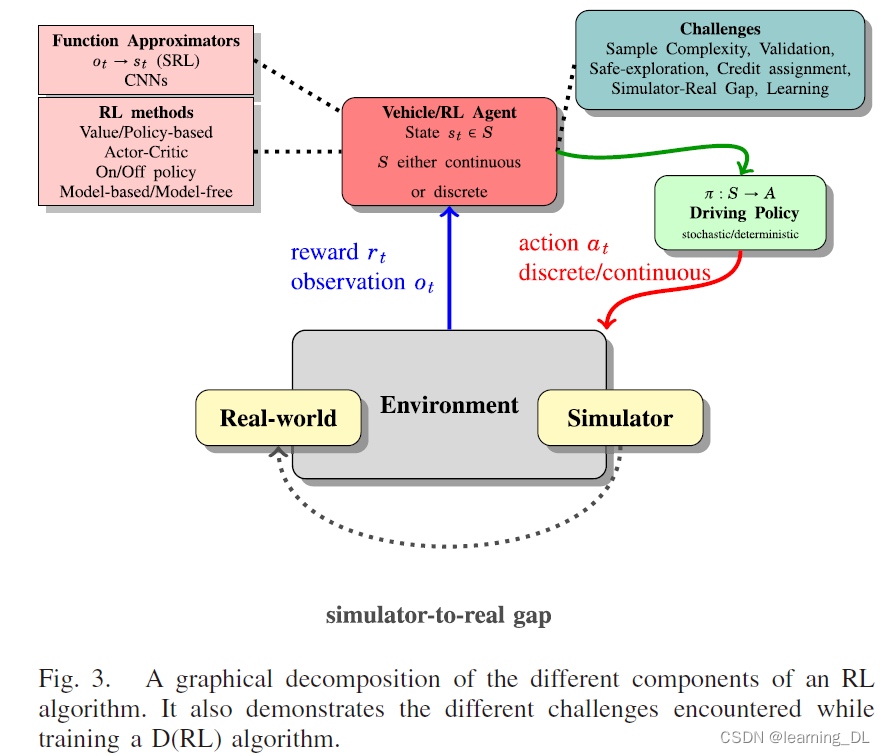
3. 强化学习
机器学习(ML)是计算机从过往经验学习,在某一特定任务提升性能的过程。机器学习算法通常分为三大类:监督学习、无监督学习、强化学习。
RL的智能体不通过专家告诉其如何行动,而是通过奖励函数R评估它的表现。每个状态中,智能体选择一个行动并接收环境所给予的相应奖励。智能体的目标是最大化累积奖励。强化学习的主要挑战之一是平衡开发(exploitation)和探索(exploration)。为最大化其收到的奖励,智能体必须利用其已有的知识,采取能获得最大收益的行动,另一方面,为了探索更大收益的行动,智能体必须冒险尝试新的行动,以求得比当前最优行动更加高的奖励。换言之,智能体必须充分利用已有知识获得奖励,但其也必须探索未知,以便在未来获得更好的行动选择。平衡这两者的策略有ε-greedy和softmax。当采用ε-greedy策略时,智能体或以ε的概率选取行动,或以1-ε的概率贪婪地选择当前状态值最高的行动。直觉而言,智能体在训练过程开始,对问题环境知之甚少时会更多地探索。随着训练进行,智能体可能会采取更多开发而不是探索。RL智能体探索策略设计属于动态搜索的领域,(如[Z.-W. Hong, T.-Y. Shann, S.-Y. Su, Y.-H. Chang, T.-J. Fu, and C.-Y. Lee, “Diversity-driven exploration strategy for deep reinforcement learning,” in Advances in Neural Information Processing Systems, vol. 31, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds. New York, NY, USA: Curran Associates, Inc., 2018, pp. 10489–10500. [Online]. Available:
https://proceedings.neurips.cc/paper/2018/file/a2802cade04644083dcde1c8c483ed9a-Paper.pdf])。
马尔可夫决策过程(MDPs)被认为是单RL智能体序列决策问题事实上的标准。MDP包含一系列状态S、动作A、转换函数T、和奖励函数R,也即元组<S,A,T,R>。在任意状态s∈S下,采取行动a∈A,使环境进入新的状态s'∈S,转换概率T(s, a, s')∈(0, 1),得到奖励R(s, a)。这一过程如下图。
 随机策略π:S → D是一系列动作下状态空间向概率的映射,π(a|s)代表在状态s下采取行动a概率。目标是找到最优策略π*,以得到最高的奖励总和:
随机策略π:S → D是一系列动作下状态空间向概率的映射,π(a|s)代表在状态s下采取行动a概率。目标是找到最优策略π*,以得到最高的奖励总和:
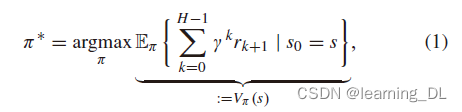
对所有状态s∈S,rk=R(sk, ak)是在k时间的奖励,Vπ(s),即“价值函数”,是状态s下采取策略π,期望的“收获”(或“效用”)。一个重要的相近概念是动作价值函数,即“Q函数”,定义如下:
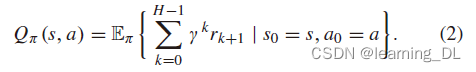
时间折扣γ∈[0, 1] 决定智能体如何看待未来的奖励。γ太小将导致智能体短时,追求短期利益最大,大的γ值会使得智能体目光长远,在更长的时间框架内取得最大收益。视界H表示MDP的时间步数。对于无限视界问题H=∞,片段H值是有限的。片段可在固定时间步,或当智能体达到某一目标状态后结束。片段域内最终达到的状态成为终止状态。对于有限视界或目标导向问题,时间折扣为(或接近)于1,以鼓励智能体聚焦于目标。而无限视界问题使用较小的时间折扣,已在长短期奖励中取得平衡。
在真实世界,智能体无法观察到环境状态所有特征,这种状态下的决策问题被称为部分观察马尔科夫决策过程(POMDP)。解决一个强化学习任务意味着沿状态空间内一定轨迹,找到可使折扣奖励总和最大的策略π。RL智能体可直接组恶习价值函数估计、策略和/或环境模型。给定完美的环境模型,奖励和转换函数已知,可用动态规划(DP)算法求得最优策略。与DP不同,蒙特卡洛方法无完整的环境知识假设。蒙特卡洛方法用于片段级问题。当一个片段内完成后,其预估价值和策略得到更新。另一方面,时序差分(TD)算法应用于时间步级别,适用于非片段场景。于蒙特卡洛方法类似,TD方法可以直接从原始经验中学习,而无需对动态环境建模。与DP类似,TD方法可从其他预估中学习预估。
3.1 基于价值的方法
Q-learning是强化学习最常用的算法。它是一种无需模型的TD算法,学习个体最佳状态-行动组合(定义见式(2))。Q-learning已被证明,对于MDP,其必定收敛于最佳状态-行动价值,只要所有状态下的所有行动可无限次采样,以及状态-行动值为离散表征。
使用Q-learning的智能体按如下规则更新Q值:
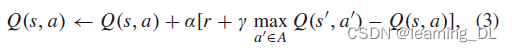
Q(s,a)是状态s下所选取行动a的效用预估,α∈[0, 1]是学习率,控制每一时间步Q值更新的程度,γ∈[0, 1]同式(1)中的时间折扣。Q-learning方法理论上对任意初始Q值均成立,故MDP过程的最佳Q值可以从任意初始行动价值函数开始学习。
深度Q网络(DQN)[V. Mnih et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015.] 为一个Q值可变的算法,使用在高维状态空间(如Atari游戏画面帧中的像素)的深度神经网络(DNN)作为非线性Q值估值器。实践中,神经网络可在无清晰信息或人工设计特征的情况下预测出所有行动的价值。DQN应用经验重放(experience replay)机制来打破连续经验采样间的联系,同时提升采样效率。3.4进一步介绍深度强化学习中DNN的应用。
3.2 基于策略的方法
基于价值和基于策略方法的区别本本在于所优化的对象。两种方法均需提出行动并评估结果,但基于价值的方法关注最佳累积奖励,并推荐相应策略;基于策略的方法直接评估最佳策略,而价值就算计算也是放在其次。通常,一个策略参数化为一个神经网络πθ。策略梯度方法使用梯度下降评估使期望奖励最大的策略。结果可以是随机策略,行动通过采样选取,也可以是确定性策略。真实事件的许多应用行动空间使连续的,确定性策略梯度算法(DPG)使强化学习可用在连续行动的问题上。确定性策略梯度具备简单的无模型形式,遵循行动-价值函数梯度。最终,与随机策略梯度状态和行动空间积分不同,DPG仅需对状态空间积分,是的问题采样更少,行动空间更大。
为确保足够的探索,当学习一个明确的目标策略时,行动通过随机策略选择。REINFORCE [R. J. Williams, “Simple statistical gradient-following algorithms for connectionist reinforcement earning,” Mach. Learn., vol. 8, nos. 3–4, pp. 229–256, May 1992.] 算法是一个直接的基于策略的方法。一个时间步内的累计折扣奖励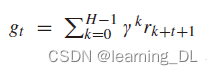 也通过整个片段来计算,所以策略无需专门的评估器。参数沿性能梯度方向更新:
也通过整个片段来计算,所以策略无需专门的评估器。参数沿性能梯度方向更新:
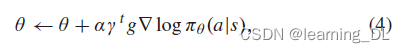
其中,α为学习率。
直觉地,我们希望状态-行动对向可能的最优结果前进。信任域策略优化(Trust Region Policy Optimization,TRPO)可以防止更新的策略与之前偏离太多,进而减少不良更新的几率。TRPO提出了一个替代的目标函数,基本思想是通过衡量当前策略和更新策略间的KL散度来限制策略梯度更新。此方法导致策略性能单调改进。近端策略优化(Proximal Policy Optimization,PPO)提出了一个裁剪的替代目标函数,对过大的策略变化进行惩罚。故PPO策略优化更易执行,而且在保证策略偏移较小的同时保证了样本的复杂性。
3.3 演员-评论家方法
演员-评价者方法结合了基于策略和基于策略算法。选取行动作为“演员”,预估价值函数作为“评价者”,评估行动的价值。每次选取行动后,评价者即评估新状态以评价行动的好坏。两个网络均需要学习梯度。令 为策略目标函数,θ为DNN参数。策略梯度目标是寻找最大的本地J(θ)。由于连续行动空间上的优化成本高且速度慢,DPG(Direct Policy Gradient)算法将行动参数化为
为策略目标函数,θ为DNN参数。策略梯度目标是寻找最大的本地J(θ)。由于连续行动空间上的优化成本高且速度慢,DPG(Direct Policy Gradient)算法将行动参数化为![]() ,
,![]() 代表行动网络参数。给出策略梯度的无偏差估计如下:
代表行动网络参数。给出策略梯度的无偏差估计如下:
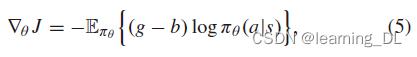
其中,b为基准。当b≡0时即简化为REINFORCE方程。选取好的基准可以减少 变化,得到更稳定的学习过程。基准b可通过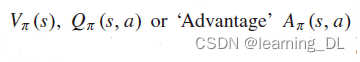 方法选取。
方法选取。
Deep Deterministic Policy Gradient (DDPG)是一种无需模型、off-policy、演员-评价者的算法,使用基于深度神经网络的函数估计,从连续动作空间中学习,将DPG扩展到更大更高维度的状态-动作空间中。当选取动作时,通过在演员策略中加入噪声实现探索(exploration)。类似DQN,为稳定学习过程,应用回放缓冲(replay buffer)最小化数据关联性。普通的Q-learning需要限定离散动作的数量,DDPG同样需要一个直接的方法选取动作。从Q-learning开始,将(2)式扩展,定义最佳的Q值和动作为Q*和a*:
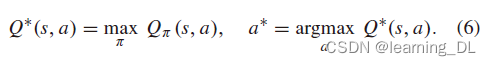
在Q-learning中,动作选择基于(6)式中的Q方程,但DDPG在动作早已按策略选择之后再评价Q值。选取最优动作修正Q值后,策略同样需相应更新,故Q*、π*需要两个独立的网络评估。
Asynchronous Advantage Actor Critic (A3C) 使用异步梯度下降优化深度神经网络控制器。基于经验重放的深度强化学习算法,如DQN、DDPG在一些困难领域展现出了可观的成功,如玩Atari游戏。然而,经验重放需要大量内存存储经验案例,且需要off-policy的学习算法。在A3C中,智能体不适用经验重放缓冲,而是异步执行环境的多个平行实例。为进一步减少经验间的联系,平行演员-学习者有助于稳定训练过程。这一简单机制使on-policy方法可以和off-policy强化学习算法一样鲁棒地应用深度神经网络。A3C在Atari领域超越了之前的方法,仅用一个多核CPU而不是GPU,训练时间还减半。它同样展示了使用价值函数预估作为基准b可以减少波动,减少收敛时间。通过定义advantage 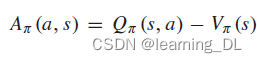 ,(5)式中的策略梯度可以写成:
,(5)式中的策略梯度可以写成:
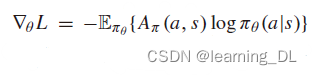 。评论家训练以最小化
。评论家训练以最小化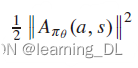 。
。
直觉上, 使用advantage而不是时间折扣,使智能体不仅仅知道它的动作“有多好”,而且可以知道比期望的“好多少”,进而减少波动,训练更加稳定。A3C模型在三维环境如走迷宫中表现良好。
Advantage Actor Critic (A2C)是A3C模型的同步版本,它在更新前会等到智能体完成当前经验。
大多数贪婪的策略要在探索(exploration)和开发(exploitation)间转换,好的探索应该访问价值不确定的状态。换言之,探索关注最不确定的状态路径,因为他们可以带来有价值的信息。在advantage上更进一步,一些方法引入熵来衡量不确定性,许多A3C实践中同样包含这个思想。
energy-based policies和更新更广泛使用的Soft Actor Critic (SAC)算法[T. Haarnoja et al., “Soft actor-critic algorithms and applications,” 2018, arXiv:1812.05905. [Online]. Available: http://arxiv.org/abs/1812.05905] 均在奖励函数中增加了熵的项。故(1)式策略目标改写如下:
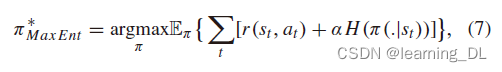
3.4 基于模型(vs.无模型)和On/Off Policy 方法
在实践中,与环境的交互受安全和成本的限制。构建环境的动态模型可减少与真实环境交互的次数。此外,探索可以在该模型中进行。在基于模型的方法(如Dyna-Q、R-max)中,智能体试图学习转换函数T和奖励函数R,其可用于选择动作。对环境建模意味着拥有环境的动态信息,可以减少有时成本高昂的环境互动。与之相反,无模型方法无需这些信息。无模型的学习者直接从MDP采样以获取未知模型的知识,如可以以价值函数预估的形势。在Dyna-2中,学习智能体存储长短期记忆,记忆定义为特征和相应参数的集合,以评估价值函数。长期记忆用于一般领域的知识,其从真实经验中更新,短期记忆是当前情景的特定本地知识,价值函数是长短期记忆的线性组合。
学习算法可以为on-policy和off-policy,取决于其更新基于当前策略还是其他策略生成的最新轨迹,其他策略可以是过往版本的策略,也可以是专家提供的策略。on-policy方法如SARSA[G. A. ummery and M. Niranjan, “On-line Q-learning using connectionist systems,” Cambridge Univ. Eng. Dept., Cambridge, U.K., Tech. Rep. TR 166, 1994.],当一个策略用于控制时同时评价该策略的价值。
然而,off-policy方法,如Q-learning[C. J. C. H. Watkins, “Learning from delayed rewards,” Ph.D. dissertation, Dept. Psychol., Cambridge Univ., Cambridge, U.K., 1989. [Online]. Available: https://ci.nii.ac.jp/naid/10008997819/]使用两套策略:行为策略用于生成行为,目标策略用于改进。这种分割的优势之一是目标策略可以更有决心deterministic(贪婪greedy),而行为策略可以持续对可能的动作采样。
3.5 深度强化学习(DRL)
列表是储存学习估计参数(如价值、策略或模型)最简单的方式,每个状态-动作对均有对应离散的参数。当参数被离散化表示时,状态每增加一个特征会使需要存储的状态-动作对的数量呈指数级上升。文献中常把此问题成为“维度诅咒(curse of dimensionality)”,由Bellman提出。在简单环境中这不是问题,但这在真实世界由于存储和/或计算限制,这个问题非常棘手。从巨大的状态-动作空间学习是可能的,但学到有用的策略可能会消耗不可接受的长时间。真实世界的状态空间和/或动作空间往往是连续的,在许多情形下可以离散,大的离散步长可能限制性能,而小的步长可能导致巨大的状态-动作空间,从而使获得足够数量状态-动作对采样不可行。状态和动作可用函数进行预估,函数预估是RL研究中一个活跃的领域,提供了一种处理状态和动作空间的方法,减缓了状态-空间爆炸,以及一般化了先前未看到的状态-动作对的经验。平铺编码(tile coding)是最简单的一种函数预估,一块区域代表了多个状态或状态-动作对。神经网络同样普遍应用于函数预估中,最著名的例子是[G. Tesauro, “TD-gammon, a self-teaching backgammon program, achieves master-level play,” Neural Comput., vol. 6, no. 2, pp. 215–219, Mar. 1994.]。近期新兴的主流算法DRL算法,已达到(或超过)了人类在复杂任务,如Atari和围棋的水平。
DQN展示了神经网络如何仅从原始的Arari视频中即可成功学到控制策略。网络为端到端训练,不提供任何游戏信息。卷积神经网络的输入为一个84×84×4的张量,4个连续帧用于捕捉瞬时信息。通过连续层后,网络学会如何组合各种特征以识别出什么动作可能会得到最大收益。一层由多个卷积核组成,例如,首层使用了32个8×8的核,步长为4,使用非线性整流。第二层有64个4×4卷积核,步长为2,使用非线性整流。第三层有64个3×3卷积核,步长为1,使用整流。倒数第二层有512个全连接整流单元组成,输出层为线性全连接层,输出一个可行的动作。DQN为了训练稳定性,使用两个网络,当在线网络参数迭代一定次数时,修正目标网络的参数。处于使用原因,Q(s,a)函数以神经网络表示,预测输入状态后所有动作的价值。相应的,决定要采取的动作即为神经网络的一次前向传播。更进一步,为了增加取样效率,智能体的经验存储在回放内存(经验回放experience replay)中,从中随机取样进行Q-learning更新。这种随机选组打断了连续样本中的联系。经验重放使RL智能体记住并重新运用过往的经验,其中观察到的转换(transiion),通常以队列的形式,已存储了一段时间,并统一从该存储中采样,以更新网络。然而,这种方法只是简单地以相同顺序重放转换过程,忽略了它们不同的重要性。另一种方法使用两个经验篮子(experience bucket),一个用于正向、一个用于反向奖励[K. Narasimhan, T. Kulkarni, and R. Barzilay, “Language understanding for text-based games using deep reinforcement learning,” in Proc. Conf. Empirical Methods Natural Lang. Process., 2015, pp. 1–11.]。两个篮子均选取固定数量片段进行回放。这种方法只适用于天然具备双向经验的问题。经验同样可以优先级排序[T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” 2015, arXiv:1511.05952. [Online]. Available: http://arxiv.org/abs/1511.05952],基于TD(Temporal Difference,时序差分)误差,更重要的转换会被更频繁地回放,和标准经验回放机制相比更加改进性能和加快训练。
标准Q-learning和DQN中的最大化操作(max operator)使用相同的值来选取和评估动作,会导致价值预估过优化。Double DQN(D-DQN)解决了DQN中这一过预估问题,其中的贪婪策略通过在线网络评估,并使用目标网络评估它的价值。实验现实这种算法不仅提高了值预估准确性,也在一些游戏中获得了更高分。
Dueling network(竞争网络) 架构判断了价值函数和相应的优势(advantage)函数,并将它们结合进而判断动作价值函数。竞争型架构的优势部分在于其可高效学习状态-价值函数。在一个单线的架构中,只更新一个动作的价值。而在竞争型架构中,每次更新均更新价值流,可以更好的评估状态价值,如Q-learning的时序差分方法需要该值准确。
DRQN[M. Hausknecht and P. Stone, “Deep recurrent Q-learning for partially observable MDPs,” 2015, arXiv:1507.06527. [Online]. Available: https://arxiv.org/abs/1507.06527]在DQN基础上用Q-Network作为LSTM机制。相应地,DRQN可以整个帧之间的信息进而检测如目标速度一类的信息。在观察完整的情况下,DRQN可以泛化其策略,在Atari游戏等闪烁类游戏中,DRQN泛化性好于DQN。
4. 强化学习扩展
4.1 设计奖励(Reward Shaping)
4.2 多智能体强化学习(MARL)
4.3 多目标强化学习(MORL)
4.4 状态表征学习(SRL)
4.5 从示例中学习(LfD)
5. 强化学习用于自动驾驶任务
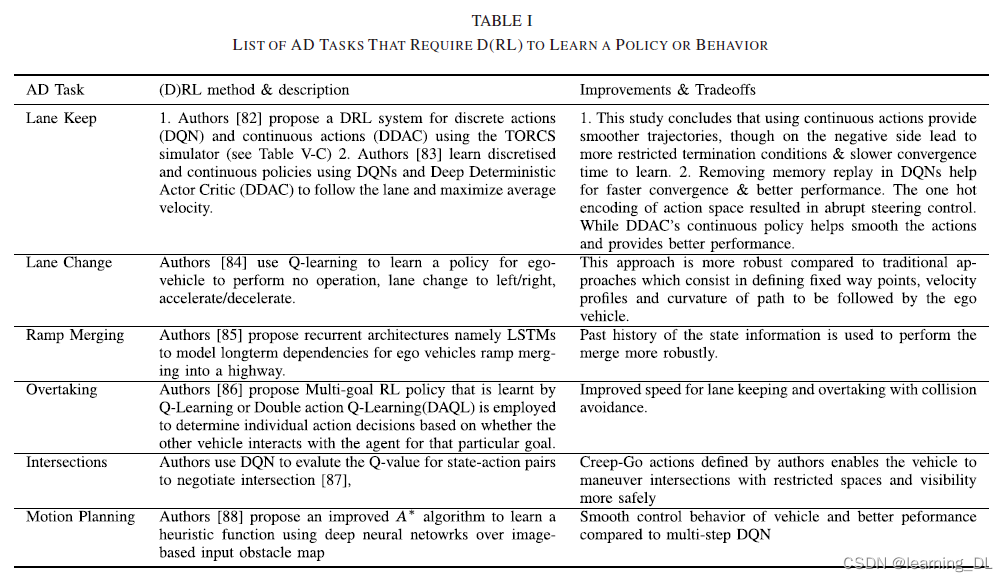
强化学习在自动驾驶任务中的应用包含:控制器优化、路径规划和轨迹优化、运动规划和动态路径规划、复杂导航任务下的高级驾驶策略开发、快速路基于场景的策略学习,路口通行,汇入和离开车流,用专家数据反向强化学习奖励用于交通参与者(如行人、车辆)意图预测,以及最终学习确保安全和评估风险的策略。
5.1 状态空间、动作空间和奖励
如何在自动驾驶任务中应用DRL,合理设计状态、动作空间、奖励很重要。Leurent等[E. Leurent, “A survey of state-action representations for autonomous driving,” Tech. Rep., 2018. [Online]. Available: https://hal.archivesouvertes.fr/hal-01908175/document]做了自动驾驶研究中不同状态和动作表征的调研。自动驾驶车辆中常用的状态空间特征包括:位置、朝向、本车速度、传感器感知到的本车周边障碍。为避免状态空间维度波动,经常采用以本车为原点的笛卡尔或极坐标系。进一步用车道信息进行增强,如车道数量、路径曲率、本车的历史和未来路径、径向信息如碰撞时间(TTC)、以及场景信息如交通法规和信号灯位置。
使用摄像头、激光雷达、雷达等传感器的原始数据可以更好构建背景信息,而使用更精简的信息会降低状态空间的复杂度。在二者之间,一种中级的表征如2D鸟瞰视角(BEV),是传感器不可知的(sensor agnostic),而又接近场景空间信息。下图俯瞰图展示了占用格、过往和投射(预测)轨迹,以及场景语义信息,如交通信号灯等。
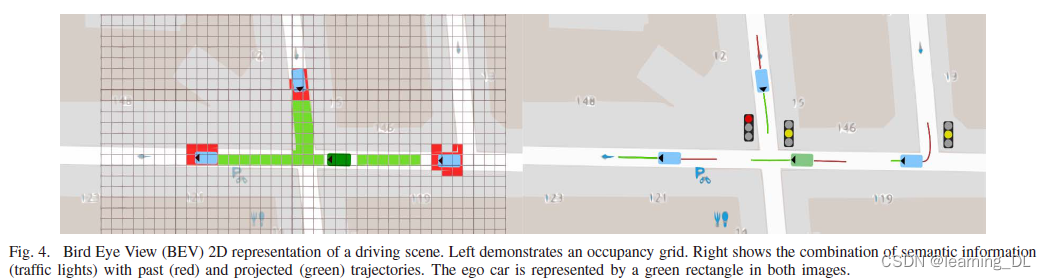
这一中间格式保留了空间布局,基于图像的表征做不到。一些模拟器提供了这种视角,如Carla或Flow,见下表。

一个车辆策略需要控制一定数量不同的执行器。车辆连续值执行器包括转向角、油门和刹车。其他执行器如挡位是离散的。为减少复杂度,并使仅适用于离散动作空间的DRL算法可用(如DQN),动作空间需要统一离散化,将连续执行器如转向角、油门和刹车的范围等分。由于在实践中,多数转向角接近于中心,还可以使用log空间离散化。然而离散化也会带来缺陷,动作过大的步长会导致轨迹波动或不稳定。此外,选择执行器的分割数量需要足够多以使控制平稳,而过多的分割会导致动作选择计算成本过高,这需要取舍。作为替代,可以使用可处理连续值的DRL算法直接学习策略(如DDPG)。Temporal abstractions options framework[R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning,” Artif. Intell., vol. 112, nos. 1–2, pp. 181–211, Aug. 1999.] 也可用于简化动作选取流程,其中智能体选择选项(option)而不是低级别的动作(action)。这种选项表示了一种子策略,可以扩展到多个时间步上的动作。
自动驾驶DRL智能体的奖励函数设计仍然没有定论。自动驾驶任务的评判标准包含如:向目标已行驶距离、本车速度、本车保持静止、与其他道路用户或场景物体的碰撞、与路肩刮擦、车道保持、行驶舒适平稳、避免急加速减速或转向,以及遵守交通规则。
5.2 运动规划和轨迹优化
运动规划任务确保目标和终点间的路径存在。不同车辆在动态环境中的路径规划对于自动驾驶非常关键,例如通过路口、高速汇车。近期的一些工作[W. Zhan et al., “INTERACTION dataset: An INTERnational, adversarial and cooperative moTION dataset in interactive driving scenarios with semantic maps,” 2019, arXiv:1910.03088. [Online]. Available: http://arxiv.org/abs/1910.03088] 包办了真实世界多种交互驾驶场景下不同交通参与者的的行为。近期,研究人员展示了DRL(DDPG)在全尺寸车辆上的自动驾驶应用[A. Kendall et al., “Learning to drive in a day,” in Proc. Int. Conf. Robot. Autom. (ICRA), May 2019, pp. 8248–8254.]。在上车使用车载电脑前,系统首先在模拟器上训练,并学会了沿路径前进,成功完成了250米的真实路试。基于模型的DRL算法被提出用于直接从原始像素输入中学习模型和策略。在[S. Chiappa, S. Racanière, D. Wierstra, and S. Mohamed, “Recurrent environment simulators,” in Proc. 5th Int. Conf. Learn. Represent., ICLR, Toulon, France, Apr. 2017, pp. 1–61.]中,深度神经网络被用于在模拟环境中数百个时间步上生成预测。强化学习同样适合控制。在[]中,经典的最佳控制方法如LQR/iLQR和RL算法进行了比较。经典RL算法用于随机设置上的最佳控制,如LQR(Linear Quadratic Regulator)在线性状态、iLQR(iterative LQR)在非线性状态中的应用。近期研究现实参数随机搜索获得策略网络和LQR表现一样好。
5.3 模拟器和场景生成工具
自动驾驶数据集为有监督的学习提供了多种形态的图像、标签对。强化学习需要一个环境,用于发掘状态-动作对,这个环境可以为车辆状态动力学、环境建模,也可以分别向环境和智能体的变化和动作增加随机性。多个模拟器活跃应用在强化学习算法训练和验证中。下表总结了多个高精确性的感知模拟器,能够模拟摄像头、激光雷达、雷达等。 一些模拟器还能提供车辆静态和动力学。

在成本高昂的真实路试之前,学习完成的驾驶策略需要在模拟环境中进行压力测试。[M. Cutler, T. J. Walsh, and J. P. How, “Reinforcement learning with multi-fidelity simulators,” in Proc. IEEE Int. Conf. Robot. Autom. (ICRA), May 2014, pp. 3888–3895.] 提出了多精度强化学习(Multi fidelity reinforcement learning, MFRL)框架,其中可用多个模拟器。在MFRL中,训练验证RL算法、表征状态和动力学的模拟器精度逐级增加(相应成本同样增加),并使用一台远程控制车辆,以寻找真实世界中成本最低的样本,并接近最优的策略。
CARLA Challenge 是一个基于Carla模拟器的自动驾驶竞赛,采用NHTSA(National Highway Traffic Safety Administration)一份报告中接近碰撞前的场景。系统在特定场景中进行测试,如:本车失控、对未知障碍物的反应、变道避开慢车。智能体得分取决于在不同循环中的行驶距离总和,在此基础上,总分还会根据违法情况相应扣除。
5.4 从示例学习(LfD)和逆强化学习(IRL)的自动驾驶应用
早期驾驶车辆Behavior Cloning(BC)研究展示了可以从示例中学习(LfD)的智能体,试图模仿人类专家的行为。BC是典型的有监督学习,因此,BC难以适应新的、未遇到过的情景。[M. Bojarski et al., “End to end learning for self-driving cars,” in Proc. NIPS Deep Learn. Symp., 2016, pp. 1–9.]、[M. Bojarski et al., “Explaining how a deep neural network trained with End-to-End learning steers a car,” 2017, arXiv:1704.07911. [Online]. Available: http://arxiv.org/abs/1704.07911] 提出在自动驾驶领域采用端到端的卷积神经网络。该CNN被训练到可以根据车辆单目前置摄像头的原始像素直接映射到转向命令。使用一个相对小的人类专家数据集,该系统学会在市区和快速路上沿车道行驶,无论是否有车道标识。该网络无需特别精细的训练,即学会了成功检测道路的图像表征。也有研究人员提出了使用Maximum Entropy Inverse RL,将人类司机作为示例,学习舒适驾驶轨迹优化。也有人在学习拟人变道动作中,使用DQN作为IRL中的精炼步骤提取奖励。
6. 真实世界的挑战和未来展望
6.1 强化学习系统验证
RL算法实际部署中的基础代码多种多样,超参数值变化万千,可解释性和泛化性能差。一些学者提出在高保真图像模拟器中自动生成有挑战性和稀有的驾驶场景,这种对抗性的场景是通过参数化行人和其他道路车辆行为自动生成的。将这些场景加入到模仿学习的训练集中,可以增加安全性。
6.2 连接模拟-现实的缺口
模拟-现实的转换学习是一个活跃领域,模拟是大量低成本有标注数据的来源。有学者利用领域适应(dimain adaption)从模拟到现实,从特征级别(feature level)到像素级别(pixel level)在真实世界中训练了一个机械臂抓取物体。这一基于视觉的抓取系统相比真实世界的采样快了50倍,即达到相似的性能。在自动驾驶领域,有学者[X. Pan, Y. You, Z. Wang, and C. Lu, “Virtual to real reinforcement learning for autonomous driving,” in Proc. Brit. Mach. Vis. Conf., 2017, pp. 2–14.]应用驾驶环境的模拟-现实转换图像训练了A3C智能体。进而,训练好的策略在真实驾驶数据集中评估。
6.3 采样效率
受益于对环境的先验知识,动物往往只需要几次尝试就可以学会新任务。然而对于 强化学习的关键挑战之一就是采样效率。学习过程需要太多样本来学得一个合理的策略。当有价值的经验获得成本过高或风险太大是,这一问题变得更加明显。在机器人控制和自动驾驶的案例中,由于延迟和稀疏奖励、以及在很大状态空间的观察分布不平衡,采样效率是一大难题。
设计奖励(reward shaping)通过设计更频繁的奖励函数,鼓励智能体从少数样本中更快学习,使其学到中间目标。[H. Chae, C. M. Kang, B. Kim, J. Kim, C. C. Chung, and J. W. Choi, “Autonomous braking system via deep reinforcement learning,” in Proc. IEEE 20th Int. Conf. Intell. Transp. Syst. (ITSC), Oct. 2017, pp. 1–6.]设计了一个每秒“trauma”回放机制。
IL Boostrapped RL:智能体首先线下通过模仿学习专家策略,进而当其与环境互动时可以通过强化学习自我提升。
带经验重放的演员评论员(Actor Critic with Experience Replay (ACER))
转移学习(Transfer learning)
元学习(Meta-learning)
高效的状态表征:有学者提出的模型通过VAE(?)学习了压缩的时空表征,进而直接从中得到紧凑简单的策略。
6.4 模仿的探索问题
在模仿学习中,智能体利用专家提供的轨迹。然而,专家遇到的状态分布往往不能覆盖已训练智能体在测试中遇到的所有状态。此外,模仿学习假设所有动作是独立同分布的(i.i.d.)。解决方案之一是使用数据聚集(Data Aggregation),执行训练好的策略,提取观察-动作对,再由专家进行标签,再聚集到原有的专家观察-动作数据集中。这样,从示例和已训练策略收集到的训练案例进一步探索了更多有价值状态,解决了探索缺乏的问题。
[T. Buhet, E. Wirbel, and X. Perrotton, “Conditional vehicle trajectories prediction in CARLA urban environment,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. Workshop (ICCVW), Oct. 2019, pp. 2310–2319.]指出了模仿学习的局限,训练了一个端到端的DNN,使用自车的输入原图,临近车辆的2d和3d位置,同时预测出自车动作和临近车辆轨迹。
6.5 内在的奖励函数
在受控的模拟环境,如游戏会给智能体明显的奖励信号。而在真实世界的机器人和自动驾驶却不同,设计一个好的奖励函数非常重要,这样才可以学习到想要的行为。最常用的解决方案是设计奖励(reward shaping)。在没有外在奖励或专家演示的情形时,智能体可以采用内在奖励或内在激励机制来评价其动作好坏。
6.6 DRL的整合安全
直接将训练好的自动驾驶车辆放到现实环境中很危险,因此需要考虑将安全机制加入到DRL算法中。对于模仿学习的系统,有Safe DAgger
6.7 多智能体强化学习
自动驾驶本质上是多智能体任务,除了本车由智能体控制,模拟和真实世界中同样有其他参与者,如行人、自行车和其他车辆。在MARL领域已有一些前沿方法。
一个MARL可能发挥大作用的领域是高等级决策和自动驾驶车辆组团协同,如高速超车场景,或无信号灯路口同行。另一领域是开发对抗性智能体以进行自动驾驶测试策略,即智能体在模拟器中无规律或违反交规地控制其他车辆,以暴露自动驾驶策略的缺点。最后,MARL还将在开发自动驾驶安全策略领域发挥潜在的重要作用。
7. 结论
强化学习在现实世界自动驾驶应用领域仍是一个活跃的新兴研究领域。尽管成功的商业应用还很少,有关文献也不多,而且缺乏大规模的公共数据集。自动驾驶场景包含了多个互动的智能体,它们之间需要进行协商并动态决策,这使得强化学习可以应用于该领域。然而,达到成熟的解决方案之前还有很多挑战需要解决。包括如何验证基于强化学习(RL)系统性能、模拟和现实的差距、采样效率、好的奖励函数设计以及如何将安全因素纳入到自动驾驶智能体RL系统的决策中等。















 2406
2406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









