







 本文介绍了决策树的构造,包括信息增益、信息增益率和基尼指数的概念及应用。接着讨论了剪枝处理,如预剪枝、后剪枝和损失函数。此外,还详细讲解了如何处理连续值和缺失值。最后,分析了随机森林的优缺点及算法,指出其在机器学习中的广泛应用和优势。
本文介绍了决策树的构造,包括信息增益、信息增益率和基尼指数的概念及应用。接着讨论了剪枝处理,如预剪枝、后剪枝和损失函数。此外,还详细讲解了如何处理连续值和缺失值。最后,分析了随机森林的优缺点及算法,指出其在机器学习中的广泛应用和优势。
一、决策树
决策树是一个树结构(可以是二叉树或非二叉树),每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,按照其值选择输出分支,直到到达叶节点,将叶节点存放的类别作为决策结果。二、决策树的构造
构造决策树的关键步骤是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”,就是尽量使一个分裂子集中待分类项属于同一类别。不纯度的选取有多种方法,每种方法形成了不同的决策树方法。ID3算法使用信息增益作为不纯度,C4.5算法使用信息增益率作为不纯度,CART算法使用基尼系数作为不纯度。2.1 信息增益
在信息论与概率统计中,熵(entropy)是表示随机变量不确定性的度量。设D为训练样本的一组划分,则D的熵表示为:
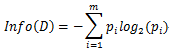
其中pi表示第i个类别在整个训练集中出现的概率,可以用属于此类别样本的数量除以训练集样本总数作为估计。
假设将训练集按属性A进行划分,产生v个分支结点,其中第j个分支结点记为Dj,考虑到不同分支结点所包含的样本数不同,赋予权重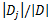
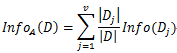
信息增益即为二者的差值:
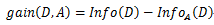
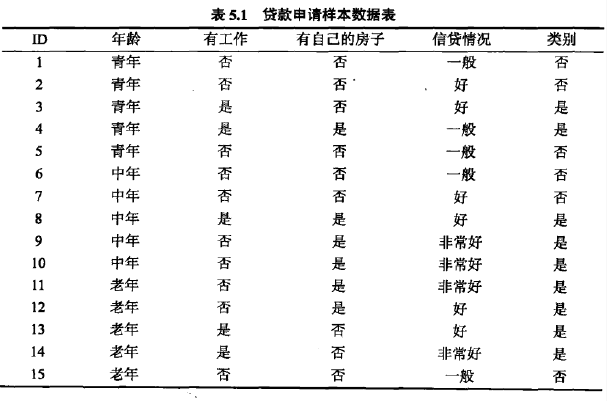
以A1、A2、A3、A4分别表示年龄、有工作、有自己的房子和信贷情况四个特征。分别计算各特征的信息增益,选择信息增益值最大的特征作为最优特征。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









